-
GDT프로젝트/운영체제 만들기 2023. 8. 5. 01:22
글의 참고
- https://wiki.osdev.org/Segmentation#Protected_Mode
- https://wiki.osdev.org/Global_Descriptor_Table
- https://stackoverflow.com/questions/37554399/what-is-the-use-of-defining-a-global-descriptor-table
- https://stackoverflow.com/questions/67901342/why-in-xv6-theres-sizeofgdt-1-in-gdtdesc
- https://en.wikipedia.org/wiki/X86_memory_segmentation
- https://softwareengineering.stackexchange.com/questions/100047/why-not-segmentation
- https://www.quora.com/Why-did-segmentation-fall-out-of-favor-to-paging
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
- `글의 참조`에서 빨간색 볼드체로 체크된 링크는 이 글을 작성하면 가장 많이 참조한 링크다.
- `운영체제 만들기` 파트에서 퍼온 모든 참조 글들과 그림은 반드시 `이 글과 그림을 소스 코드로 어떻게 구현을 해야할까` 라는 생각으로 정말 심도있게 잠시 멈춰서 생각해봐야 실력이 발전한다.
글의 내용
: GDT는 Global Descriptor Table의 약자로 x86 기반 구조에서 사용되는 자료 구조다. 즉, ARM에서 이 GDT라는 말 자체가 존재하지 않는다. GDT는 x86에서 디스크립터 저장소로 사용된다. x86에서 디스크립터는 시스템 자료 구조에 대한 메타 데이터 정보를 저장하는 역할을 한다(개인적으로, GDT의 `간접 참조` 구조는 유지 보수 측면에서 좋은 설계 방법이라고 생각된다). 메테 데이터 정보들의 예를 들자면, 해당 메모리를 어떻게 사용할 것인지, 범위가 얼마나 되는지, 해당 메모리에 대한 권한 등이 포함되어 있다.
: 현대의 대부분의 운영체제는 하드웨어적인 메모리 관리 방식으로 `페이징`을 주로 사용한다. 세그먼트처럼 동적으로 영역을 지정하는 방식은 페이징처럼 고정된 영역의 메모리를 관리하는 방식보다 유연하지 못하기 때문이다. 세그먼트 관리 방식은 기능 및 의미별로 메모리를 나눈다. 즉, 커널과 유저 영역과 같이 그 의미가 명확히 나눌 때는 여전히 의미가 있어보인다(이 글은 GDT에 대한 내용보다는 세그먼테이션에 대한 내용이 주를 이룰 듯 싶다)
: GDT 크기는 최대 2바이트의 크기를 갖는다. 아래의 `GDTR` 통해서 GDT의 사이즈를 설정한다.

: 위에서 뒤쪽에 16 ~ [47 | 79]는 GDT가 위치하는 시작 주소를 의미하고, 앞에 Limit의 GDT의 사이즈를 의미한다. 32비트 기준 GDT가 3개의 엔트리로 구성되어 있다면, Limit은 24가 될 것이다. 64비트 라면 GDT가 3개의 엔트리로 구성되어 있다면, Limit은 48이 될 것이다. 그런데 사실 이렇지가 않다. 저기는 현재 GDT의 사이즈를 기입하는게 아니라, 엔트리의 마지막 주소를 기입하는게 맞다. 인텔 매뉴얼에 이 부분에 대한 자세한 내용은 없지만, 모든 GDT 관련 글에서 저 Limit 필드에 `size - 1` 로 작성되어 있다. 이 말은 저 필드는 GDT의 마지막 엔트리의 끝 주소를 작성하는 필드로 보면 된다. 예를 들어, 32비트 기준 GDT에 3개의 엔트리가 있다면 GDT의 시작 주소를 기준으로 0-7, 8-15, 16-23으로 될 것이다. 마지막 엔트리의 끝 주소가 23이다. 이 값은 `size(24) - 1` 이다. 참고 글에 스택 오버플로우 글을 참고하자.
: 아래에 보다시피 GDTR은 시스템 레지스터다. 각 코어마다 존재하는 레지스터가 아니다. 그러므로, 부팅 시에 한 번 설정되면 거의 바뀔일이 없을뿐마 아니라, 각 코어마다 동일한 설정을 갖게된다.

출처 - Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A:. System Programming Guide, Part 1 (order number 253668) : 아래의 그림은 세그먼트 셀렉터의 TI 필드를 통해서 GDT 및 LDT를 선택하는 내용이다. 그리고 GDT의 맨 처음 엔트리는 `NULL 세그먼트 디스크립터` 라고 해서 시스템에 의해 사용되는 엔트리다. 이 부분을 인텔이 사용한다고 해서 개발자가 작성하지 말라는 뜻이 아니다. 이 부분도 OS 개발자가 코드상에서 직접 작성해서 GDT에 등록해야 한다.

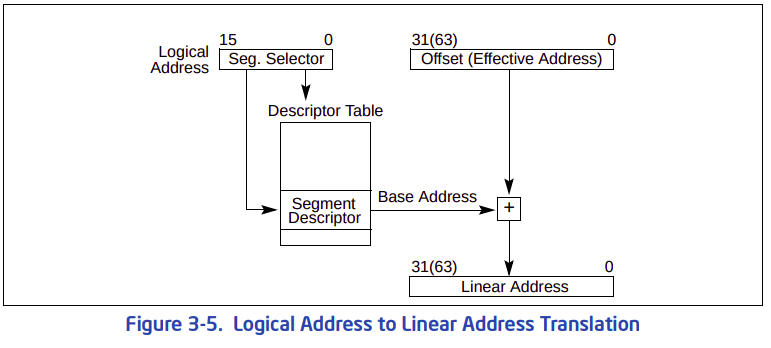
출처 - Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A:. System Programming Guide, Part 1 (order number 253668) : `논리 주소 -> 선형 주소 -> 물리 주소`로의 과정을 보여준다. 보호 모드에서 주소의 변환 과정은 앞에서 말한 과정을 거치게 된다. 만약, 페이징이 활성화되어 있지 않다면, `선형 주소 == 물리 주소`로 주소 변환을 1단계만 거치면 되지만, 페징이 활성화 되어있다면, 2단계 과정을 거쳐서 `물리 주소`가 나오게 된다. 보호 모드에서는 세그먼테이션은 비활성화가 불가능하다. 페이징과 함께 쓰거나, 세그먼테이션만 단독으로 쓰거나, 둘 중 하나를 선택해야 한다. 그래서 보호 모드에서는 `세그먼테이션 + 페이징`을 사용하게 된다. 그런데, x86 기반의 현대 운영 체제에서 보호 모드 사용 시, 마치 페이징만 사용하고 있다는 느낌을 받게 한다. 즉, 세그먼테이션을 아예 비활성화한듯한 느낌을 들게한다는 것이다. 이 내용을 알려면 `플랫 모델` 에 대해 좀 알아봐야 한다.

: 만약 세그먼트 방식을 제대로 사용한다면, 아래와 같이 메모리의 각 영역을 아래와 같이 나눌 것이다. 세그먼트 레지스터 또한 각 메모리의 영역의 기능별로 나눠져 있다. CS는 코드 영역, SS는 스택 영역, DS와 ES는 데이터 영역으로 사용된다. FS와 GS는 여러 용도로 사용이 가능한 레지스터다. 그런데 아래의 방식에 뭔가 문제가 있어서 현재는 사용되지 않을 것이다. 그 이유가 뭘까?
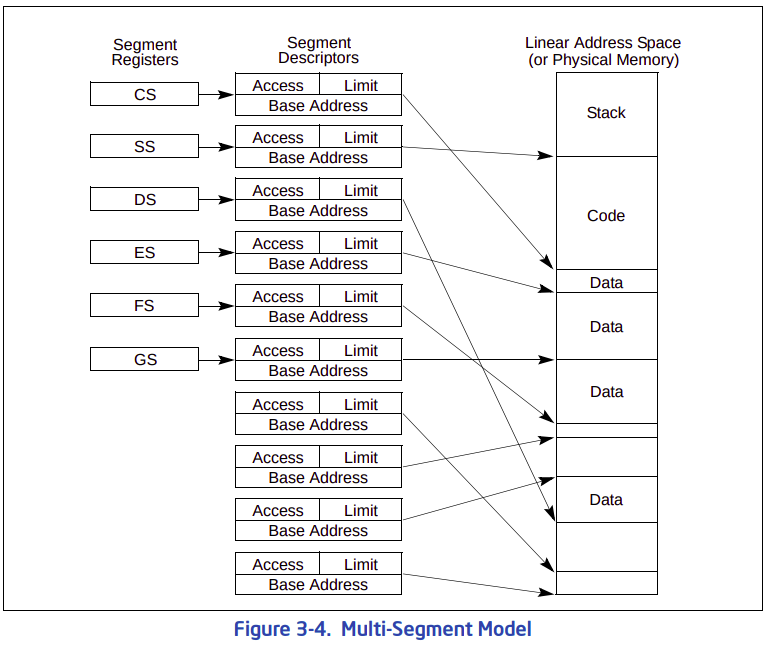
: 첫 째로 세그먼트테이션 방식은 `호환성` 측면에서 좋은 설계가 아니다. 세그먼테이션은 인텔이 리얼 모드 시기때부터 존재하던 메모리 관리 방식이다. 인텔은 호환성을 위해 이 방식을 계속 유지해 오고 있다. 현대의 모든 OS들은 거의 대부분이 페이징만을 사용해서 메모리 관리를 한다. 애초에 세그먼테이션 관리 방식이 존재하지 않는 CPU들도 존재한다. 세그먼테이션은 x86 ISA 에만 존재하는 메모리 관리 방식이다.
: 두 번째로 세그먼테이션 방식은 메모링 접근할 때, `상대 주소` 개념을 접근한다. 리얼 모드에서 16비트만 지원하는 CPU에서 20비트를 지원하기 위해 `세그먼트:오프셋` 방식은 개인적으로는 디버깅시에 착각을 일으킬 소지가 있다. 왜냐면, 메모리에 접근하려는 코드를 작성할 때마다, 저 공식에 대입해서 메모리의 값을 알아내야 한다. 직관적이지 못하다는 생각이든다.
: 세 번째로 세그먼테이션 개수의 문제다. GDT가 포함할 수 있는 최대 엔트리의 개수 8192개다(GDT 사이즈는 2^16). 즉, 시스템 전역적으로 존재할 수 있는 세그먼테이션은 총 8192개가 존재할 수 있다는 말이다. 물론 LDT가 있어서 각 코어마다 사용할 수 있는 세그먼테이션의 개수는 더 늘어날 수 있다. 그러나, 생각해보자. 전역 변수를 8192개만 사용할 수 있다는 전제가 있다면, 리눅스같이 덩치가 큰 OS들은 이 부분이 엄청난 문제가 될 수 있다.
: 세그먼테이션은 분명히 이점도 있지만, 현재 대부분의 OS는 외부 단편화와 호환성 문제로 페이징만을 주로 사용한다. 이제 진짜 `플랫 모델`에 대해 설명할 차례다.

: 이 방식은 2개의 세그먼테이션만 사용한다. `코드 세그먼테이션`과 `데이터 세그먼테이션` 이다. 2개의 세그먼테이션이 가리키는 메모리 범위는 32비트 기준 4GB로 설정한다. 즉, 각 세그먼테이션들은 모든 메모리에 접근이 가능하다. 이렇게 함으로써, 위의 두 번째 문제였던 RAM이 가려지는 문제를 해결할 수 있다. 왜냐면, 세그먼테이션의 베이스 주소를 0으로 하고 최대 주소를 0xFFFFFFFF로 설정하니 코드에서 접근하려는 주소와 실제 주소가 1:1로 매핑될 수 있다. 세그먼테이션은 베이스 주소를 기준으로 상대 주소를 사용하는 방식이기 때문에, 베이스 주소를 0으로 설정해야 실제 주소와 매핑이 가능하다. 그리고 각 세그먼트 레지스터에 내용이 교체될 오버헤드는 줄어든다. 2개의 세그먼트 각각이 RAM 전체를 가리키고 있으니, 세그먼트를 교체할 일이 없다.
: 그렇면 보호 관련 문제는 어떻게 해결할까? 대개 이 문제는 페이징을 이용해서 처리한다. 이 부분은 페이징 내용을 참고하자.
: GDT의 세그먼트 디스크립터는 어떻게 사용되는지를 알아보자.

: 시작은 세그먼트 셀렉터에 들어있는 값으로 시작한다. 세그먼트 설렉터에 들어가있는 값은 GDT의 엔트리의 주소, 즉, 세그먼트 디스크립터의 주소를 가리킨다. 그래서 보면, 세그먼트 셀렉터의 인덱스 값의 범위가 2^13임을 알 수 있다. 이 값은 GDT의 엔트리 개수와 동일하다. 즉, 프로세서는 세그먼트 셀렉터의 `인덱스 * 8`을 통해서 GDT의 세그먼트 디스크립터를 선택한다. 그리고 세그먼트 디스크립터에 실제 사용하고자 하는 세그먼트의 세부 내용들이 포함되어 있다. 즉, 세그먼트 셀렉터는 직접적으로 세그먼트를 가리키는게 아니고, 세그먼트 디스크립터를 통해서 세그먼트를 선택할 수 있게 된다. 왜 이렇게 했을까?
세그먼트 셀렉터 -> 세그먼트 디스크립터 -> 세그먼트
: 유연성과 확장성 때문이다. 코딩을 하다보면 함수를 만들게 된다. 프로그래밍에서 함수를 처음 배울 때는 중복되는 코드를 방지하기 위해서라고 배웠던 기억이 난다. 맞는 말이다. 그러나 객체지향에 대해 배우게 되면 정보 은닉에 대해 배우고 되고, 인터페이스에 대해 배운다. 그 내용을 알게 되면 함수는 아래와 같이 볼 수 있다.
입력 -> 함수(xjie&*^G*Yefuv) -> 출력
: 위에서 핵심은 함수가 블랙 박스라는 것이다. 입력은 단지 함수에 필요한 내용만 전달한다. 그러면 함수에서 특정한 값이 나오게 된다. 그러나 세부 내용은 모른다. 즉, 핵심적인 알고리즘을 함수안에 넣어놓으면 나중에 문제가 발생했을 때, 함수 내부만 수정하면 된다. 인터페이스는 전혀 건드리지 않고 말이다. 예를 들어, 아래 코드를 보자.
int add(int a, int b) { int sum = 0; ... sum = a + b; ... return sum; } int main() { int sum = add(3, 4); return sum; }: 처음에는 add() 함수가 2개의 인자를 받아서 2 인자의 합을 반환하는 함수였다. 그런데, 시간이 지나면서 개발자들은 함수에 반환값을 통해 결과를 받는 것이 아닌, 3번째 인자로 그 결과를 받고 싶어졌다. 그런데 문제는 이미 add() 함수가 다른 프로그램들에서 너무 많이 사용되서, 수정을 하기가 어렵다는 것이다. 이럴 때, 아래와 같이 만들 수 있다.
int add(int a, int b) { ... return _add(a, b, NULL); } int _add(int a, int b, int *c) { ... sum = a + b; ... *c = sum; ... return sum; } int main() { int sum = add(3, 4); return sum; }: 새로운 _add() 함수를 사용해서 외부로 노출되는 add() 함수의 인터페이스를 망가트리지 않았다. 즉, 직접적으로 바꾸기 보다는 중간에 가드(Guard)두면 수정할 일이 줄어든다는 것이다.(그리고 위의 코드에서 포인터로 저렇게 지역 변수를 참조하면 안된다. 간단히 설명하려고 작성한 내용이다. 절대 저렇게 사용하면 안된다)
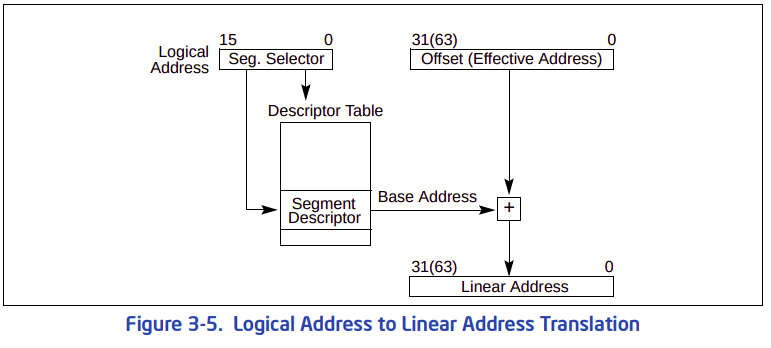
: 다시 돌아와서, 세그먼트를 선택할 때는 제일 먼저 세그먼트 셀렉터의 인덱스 필드를 참고한다. 인덱스 필드는 세그먼트 디스크립터의 주소가 들어있다. 그렇면 GDT에서 세그먼트 디스크립터를 꺼내서, 세그먼트의 베이스 주소를 꺼낸다. 이 값을 오프셋과 더해 가상주소를 만들어 낸다.
: 리얼 모드에서는 세그먼테이션 방식밖에 존재하지를 않았다. 그리고 리얼 모드의 메모리 계산은 참 독특하다.

출처 - https://en.wikipedia.org/wiki/X86_memory_segmentation : 저때 당시에는 16비트가 대세였기 때문에, 위와 같은 방식으로 메모리에 접근했다. 위의 세그먼트가 각 세그먼트의 베이스 주소가 된다. 그리고 해당 세그먼트의 크기는 그 밑에 오프셋이 담당한다. 당연히 16비트 시대였기 때문에, 베이스 주소와 오프셋 모두 16비트다. 저런 괴상한 방식으로 20비트를 뽑아낸다. 재미있는 건 0x08124가 되려면 여러 가지 세그먼트 주소가 나올 수 있다는 것이다.
1" 0x06EF:0x1234
2" 0x0812:0x0004
3" 0x0000:0x8124: 위의 3개의 주소 모두 `0x08124`를 만들어 낸다. 그럼 다시 돌아와서, 논리적 주소의 32비트 오프셋은 뭘까? 오프셋은 리얼 모드에서는 `IP`를 의미하고, 보호 모드에서는 `EIP`, 롱 모드에서는 `RIP`가 된다. 즉, `오프셋`은 현재 실행할 명령어 주소를 의미한다.
- 세그먼트 디스크립터

: 각 비트들의 의미는 다음과 같다.
레이블 설명 BASE (Base Address fields) 말 그대로 해당 세그먼트 시작 주소를 나타낸다. BASE 비트는 총 32비트로 구성되어 있다. 그래서 4G를 표현이 가능하다. 가장 중요한 부분은 물리 주소가 아닌 선형 주소를 기입해야 한다. 이 주소는 16바이트 정렬된 주소로 제공되는 것이 퍼포먼스에 좋다. 왜 16바이트 정렬을 선호할까? 리얼 모드와의 호환을 위해서다. 리얼 모드에서 주소 지정 방식이 `(세그먼트 주소 << 4)` 였다. 이 계산법은 무조건 16바이트 정렬을 유도한다. x86 리얼 모드가 이 방식에 최적화되어 있다보니 보호 모드에서도 이 구조를 지켜줘야 하는 것 같다(참고로, 16바이트 정렬은 하위 4비트가 0임을 의미한다). S (Descriptor Type) flag 1이면 코드/데이터 세그먼트, 0이면 시스템 세그먼트 DPL (Descriptor Privilege Level) flag 프로세서 세그먼트 보호 메커니즘으로 세그먼트의 권한 레벨을 지정한다. 0 - 3을 명시할 수 있으며, 0은 가장 강한 권한이다. 3이 가장 약하다. `5.5 Privilege Levels`를 참고하자. P (Segment-Present) flag 현재 세그먼특 메모리(1)에 있는지 디스크(0)에 있는지를 나타낸다. 만약, 해당 세그먼트가 메모리에 없다면(0), 프로세서는 `Segment-Not-Present Exception`(#NP) 를 발생시킨다. G 이 비트가 0이면 `Segment Limit`의 단위가 1바이트가 되고, 1이면 4KB 단위가 된다. AVL 시스템 소프트웨어가 사용하라고 남겨놓은 플래그 비트 LIMIT 세그먼트 사이즈를 나타낸다. 총 20비트를 차지한다. 그래서 `G` 비트 값에 따라 프로세서는 세그먼트의 사이즈를 1MB 혹 4GB 로 할지를 결정한다.
만약, 베이스 어드레스에 더해지는 `오프셋` 값이 LIMIT 보다 더 크다면 #GP(General-Protectin Exception)을 발생시킨다. 만약, 해당 세그먼트가 SS 였다면 #SP(Stack-Fault Exception)을 발생시킨다.TYPE 구체적인 내용은 `3.4.5.1. Code and Data Segment Descriptor Types` 참고. : Type 필드는 구체적으로 아래와 같이 구성되어 있다. Type 필드가 아래와 같이 구성되는 전제는 S가 필드가 코드 및 데이터 세그먼트 여야 한다는 것이다. Type 필드의 11번째 비트가 해당 디스크립터가 코드 세그먼트(0) 인지 데이터 세그먼트(1) 인지를 나타낸다. 그리고 A는 `Access`를 의미하고, `W`와 `R`은 각각 `Write`와 `Read`를 의미한다. `W` 과 `R`는 11번째 비트가 코드냐 데이터에 따라 그 의미가 달라진다. `A`는 CPU에서 접근할 때 자동으로 설정되는 비트이므로, 0으로 설정하는 것이 좋다.
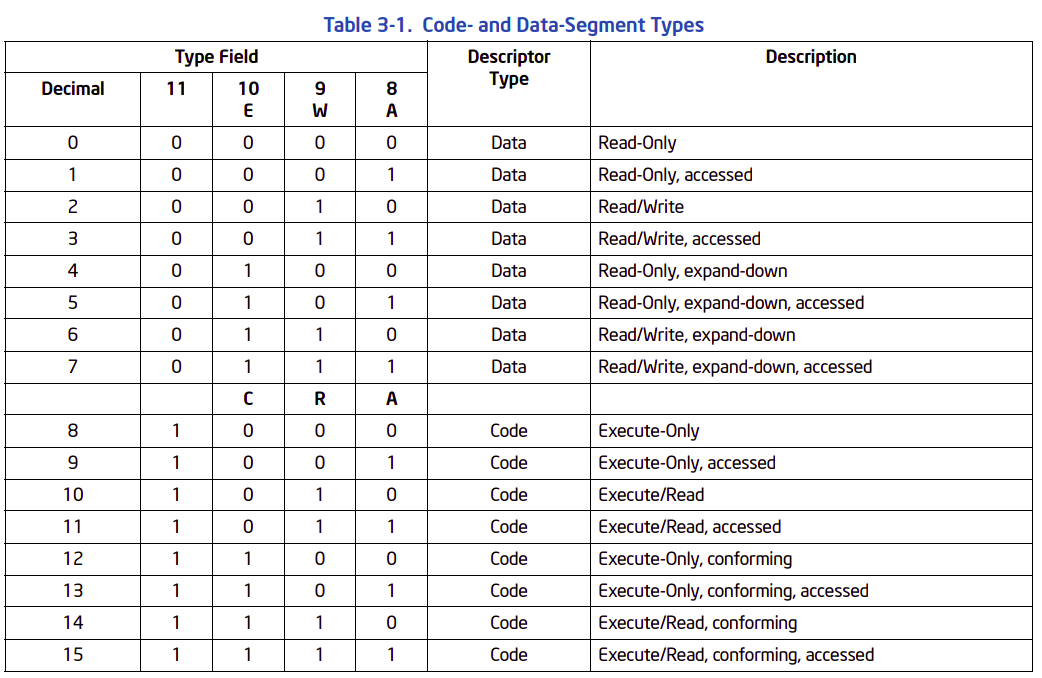
: 주의할 점은 스택 데이터 세그먼트는 반드시 읽기/쓰기가 모두 허용되야 한다. 왜냐면, 스택은 개발자만 쓰는 데이터 영역이 아니다. 자연스럽게 PUSH, POP 같은 명령어를 이용하면 당연히 스택을 읽고 쓰게 된다. 만약, 스택 세그먼트에 쓰기가 허용되지 않으면, 프로세서는 #GP 를 발생시킨다.
: `E`와 `C` 또한 해당 세그먼트가 코드 혹 데이터 세그먼트 이냐에 따라 다르다. 데이터 세그먼트에서 `E` 필드는 스택 세그먼트와 관련이 있다. 스택 세그먼트의 크기를 동적으로 늘려야 할 경우, `E`를 1로 세팅할 수 있다. 확장시에 2가지를 변경할 수 있다. 스택 세그먼트 베이스 어드레스와 스택 세그먼트 제한(LIMIT)중에서 아무거나 바꿔도 되는 듯 하다.
: `C`는 코드 세그먼트와 관련이 있다. 코드 세그먼트 권한이 더 높은 레벨로 가고 싶을 경우, 이 비트를 SET 하면 된다.
- 64비트 세그먼테이션
: 인텔 64비트 모드를 일반적로 `IA-32e` 모드라고 한다. 그런데, 이 모드는 2가지 모드로 다시 나뉠 수 있다. `호환 모드`와 `64비트 모드`로 나뉜다. `호환 모드`는 기존 `보호 모드`에서 동작했던 애플리케이션들에 대한 호환 모드다. 진짜 중요한 건 `64비트 모드`다. 이 모드에서는 세그먼테이션은 일반적으로 비활성화되어 있다.
In IA-32e mode of Intel 64 architecture, the effects of segmentation depend on whether the processor is running in compatibility mode or 64-bit mode. In compatibility mode, segmentation functions just as it does using legacy 16-bit or 32-bit protected mode semantics.
In 64-bit mode, segmentation is generally (but not completely) disabled, creating a flat 64-bit linear-address space. The processor treats the segment base of CS, DS, ES, SS as zero, creating a linear address that is equal to the effective address. The FS and GS segments are exceptions. These segment registers (which hold the segment base) can be used as additional base registers in linear address calculations. They facilitate addressing local data and certain operating system data structures.
Note that the processor does not perform segment limit checks at runtime in 64-bit mode.
- 참고 : [ 3.2.4 Segmentation in IA-32e Mode ]- 64비트 세그먼트 디스크립터
: 64비트 세그먼트 디스크립터 작성 시에는 2가지 비트만 주의하면 된다.

: 위에서 볼 수 있다시피 세그먼트 디스크립터는 32비트, 64비트 상관없이 사이즈는 8바이트다. 그래서 GDT 도 64비트에서 크기가 확장되지 않고, 8192B 를 차지한다. 단지, 오프셋의 값이 바뀐다. 저 오프셋은 자동으로 모드에 따라 크기가 바뀌기 때문에 개발자가 신경쓸 필요는 없다. 64비트 갈 때, 신경써야 할 부분은 `L`과 `D` 비트다.
레이블 설명 L L - 이 비트가 1이면, 해당 세그먼트가 `64비트 코드 세그먼트`임을 나타낸다. 이 비트가 0이면 호환(32비트) 모드의 코드 세그먼트임을 나타낸다. 이 비트는 값이 고정되는 경우가 있다.
; `L` 이 비트가 1이면, `D` 비트는 반드시 0 이어야 한다.
; `IA-32e 모드`가 아니거나 코드 세그먼트가 아니면, 이 비트는 반드시 0 이어야 한다.D/B 이 비트는 실행 가능한 코드 세그먼트이냐 아니야 따라 기능이 달라진다. 32비트 코드 및 데이터 세그먼트라면 이 비트는 반드시 1 이어야 한다. 64비트, 16비트 코드 및 데이터 세그머트라면 이 비트는 0 이어야 한다. - 세그먼트 레지스터
: 보호 모드로 진입하면 세그먼트 레지스터는 실제로 컨트롤이 불가능하다. 보호 모드에서 SW 개발자들이 컨트롤하는 `CS`나 `DS`는 `세그먼트 셀렉터`다. 보호 모드까지는 세그먼테이션 사용이 필수다. 그래서, 최소 3개의 세그먼트 레지스터들(CS, DS, SS)는 반드시 설정해야 줘야한다.
To reduce address translation time and coding complexity, the processor provides registers for holding up to 6 segment selectors (see Figure 3-7). Each of these segment registers support a specific kind of memory reference (code, stack, or data). For virtually any kind of program execution to take place, at least the code-segment (CS), data-segment (DS), and stack-segment (SS) registers must be loaded with valid segment selectors. The processor also provides three additional data-segment registers (ES, FS, and GS), which can be used to make additional data segments available to the currently executing program (or task).
For a program to access a segment, the segment selector for the segment must have been loaded in one of the segment registers. So, although a system can define thousands of segments, only 6 can be available for immediate use. Other segments can be made available by loading their segment selectors into these registers during program execution.
- 참고 : [ 3.4.3 Segment Registers ]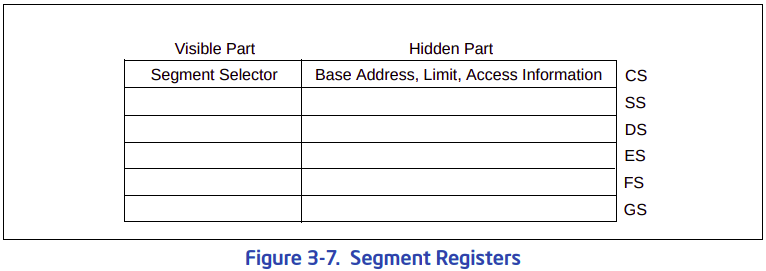
: 보호 모드 부터는 세그먼트에 접근하기 위해서는 `세그먼트 셀렉터`, `세그먼트 레지스터`, `세그먼트 디스크립터`의 관계를 알아야 한다. 보호 모드에서 특정 세그먼트에 접근하기 위해서는 반드시 해당 세그먼트의 정보가 담겨있는 세그먼트 디스크립터가 GDT에 정의되어 있어야 한다. 그리고, 이 세그먼트 디스크립터의 위치(인덱스)가 반드시 세그먼트 셀렉터에 로딩되어 있어야 한다. 그리고, 실제 세그먼트에 접근할 때, 세그먼트 셀렉터에 저장된 세그먼트 디스크립터의 인덱스가 세그먼트 레지스터의 `Visible Part`에 로딩된다. 그러면, 프로세서는 GDT에서 해당 인덱스에 해당하는 세그먼트 디스크립터를 검색한다. 그리고 해당 디스크립터에서 `Base Address`, `Limit`, `Access` 정보들을 추출해서 세그먼트 레지스터의 `Hidden Part`에 저장한다.
Every segment register has a “visible” part and a “hidden” part. (The hidden part is sometimes referred to as a “descriptor cache” or a “shadow register.”) When a segment selector is loaded into the visible part of a segment register, the processor also loads the hidden part of the segment register with the base address, segment limit, and access control information from the segment descriptor pointed to by the segment selector. The information cached in the segment register (visible and hidden) allows the processor to translate addresses without taking extra bus cycles to read the base address and limit from the segment descriptor. In systems in which multiple processors have access to the same descriptor tables, it is the responsibility of software to reload the segment registers when the descriptor tables are modified. If this is not done, an old segment descriptor cached in a segment register might be used after its memory-resident version has been modified.
- 참고 : [ 3.4.3 Segment Registers ]: 위에서 볼 수 있다시피, 이 정보들은 `descriptor cache` 혹은 `shadow register` 라는 캐시에 저장된다. 그래서, 메모리에 저장된 세그먼트 디스크립터에 매번 접근하기 보다는 CPU와 가까이 있는 캐시에 접근해서 퍼포먼스를 향상시킨다.
- 32비트 GDT 로딩
: GDT 테이블의 시작 주소는 선형 주소다. 리얼 모드에서 보호 모드로 갈 때, 보호 모드용 GDT를 만들어야 한다. 그리고 16비트 상태에서 GDT를 GDTR로 로딩시켜야 한다. 그런데, 리얼 모드는 논리 주소를 사용한다. 말이 논리 주소지 그냥 리얼 모드에서 사용하는 세그먼트 주소라고 보면 된다. 논리 주소와 선형 주소의 형태는 다음과 같다.
1" 논리 주소 = 세그먼트 주소(16비트) + 오프셋(16비트)
2" 선형 주소 = (세그먼트 주소 << 4) + 오프셋: 아래의 인텔 문서에도 나오지만, 리얼 모드 및 보호 모드에서 논리 주소를 통해 선형 주소를 구하는 공식은 다음과 같다.
: 오프셋의 사이즈는 보호 모드(32) 및 롱 모드(64)일 때, 따라 달라진다. 그러나, 64비트 모드에서는 세그먼트 주소 지정 방식이 사라졌다고 봐도 무방하다. 그리고 리얼 모드에서도 선형 주소라는 표현을 쓰는데, 리얼 모드만 있을 경우에 선형 주소는 논리 주소와 동일하다.
: 그럼 코드에서는 위의 내용을 토대로 어떻게 GDT의 주소를 구할까? `.gdt_load` 심볼을 보면 알 수 있다.
... ... .gdt_load: xor eax, eax mov ax, ds shl eax, 4 add eax, .gdt_tbl mov [.gdtr+2], eax mov eax, .gdtr sub eax, .gdt_tbl mov [.gdtr], ax lgdt [.gdtr] ... ... .gdt_tbl: ; NULL Segment dw 0x0000, 0x0000, 0x0000, 0x0000 ; Code Segment dw 0xFFFF dw 0x0000 db 0x00 db 0b10011010 db 0b11001111 db 0x00 ; Data Segment dw 0xFFFF dw 0x0000 db 0x00 db 0b10010010 db 0b11001111 db 0x00 .gdtr: dw 0 dd 0: 위의 내용의 핵심 코드들은 다음과 같다.
1" ds를 4만큼 왼쪽 시프트
2" .gdt_tbl을 더해준다.: 보호 모드에서 논리 주소를 통해 선형 주소를 구하는 공식은 `(세그먼트 주소 << 4) + 오프셋` 이다. 이 공식을 그대로 대입하면 위와 같이 나온다.
- 32비트에서 GDT 리로딩
: GRUB을 통한 멀티 부트를 하면, GRUB이 설정해놓은 GDT를 사용할 수도 있지만 나중에 64비트 GDT도 올려야 하므로, 이 때 리로딩하는 것이 여러 가지면에서 편한 방법이 된다. 여기서 주의점은 다음과 같다.
1" 16비트에서 32비트 GDT로딩
2" 32비트에서 32비트 GDT 로딩.: 말장난 같지만, 분명한 차이가 있다. GDT의 주소를 로드할 때는, `선형 주소`여야 한다. 그런데, 16비트에서 주소는 논리 주소라서 이 걸 선형 주소로 바꿔줘야 한다. 즉, `논리 주소 << 4 : 오프셋` 공식을 사용해야 한다. 그런데, 32비트에서 주소는 그 자체가 선형 주소다. 그래서 아래와 같이 간단하게 GDT 리로딩이 가능하다. 복잡한 계산이 필요없다.
...
lgdt [_gdtr]
jmp 0x08:pstart
pstart:
mov ax, 0x10
mov ds, ax
mov es, ax
...
...
call main
jmp $ ; Nevere come here
...
...
_gdt_start
_gdt_tbl:
; NULL Segment
_gdt_null_desp:
dw 0x0000
dw 0x0000
dw 0x0000
dw 0x0000
; 32 Code Segment
_gdt32_code_desp:
dw 0xFFFF
dw 0x0000
db 0x00
db 10011010b
db 11001111b
db 0x00
; 32 Data Segment
_gdt32_data_desp:
dw 0xFFFF
dw 0x0000
db 0x00
db 10010010b
db 11001111b
db 0x00
; 64 Code Segment
_gdt64_code_desp:
dw 0xFFFF ; limit = 0
dw 0x0000 ; base1[16] = 0
db 0x00 ; base2[8] = 0
db 0b10011010 ; P = 1, DPL[6:5] = 0, S = 1, TYPE[3:0] = 1010
db 0b10101111 ; G = 1, D/B = 0, L = 1, AVL = 0, LIMIT[3:0] = 0
db 0x00 ; base3[8] = 0
; 64 Data Segment
_gdt64_data_desp:
dw 0xFFFF ; limit = 0
dw 0x0000 ; base1[16] = 0
db 0x00 ; base2[8] = 0
db 0b10010010 ; P = 1, DPL[6:5] = 0, S = 1, TYPE[3:0] = 0010
db 0b11001111 ; G = 1, D/B = 1, L = 0, AVL = 0, LIMIT[3:0] = 0
db 0x00 ; base3[8] = 0
_gdt_end
_gdtr:
dw _gdt_end - _gdt_start - 1
dd _gdt_tbl
...- 64비트 GDT 로딩
: GDTR에 들어가는 GDT 주소는 선형 주소라고 했다. 롱 모드는 보호 모드와는 다르게 진입 전 페이징을 활성화 해야 한다. 즉, 롱모드에 진입하기 전부터 이미 페이징은 활성화가 되어 있다고 봐야 한다.
- 시스템 디스크립터
: GDT, IDT, LDT, TSS, CALL 디스크립터는 모두 시스템 디스크립터에 포함된다. 세그먼트 디스크립터는 GDT가 괸리하는 자료 구조라고 보면된다.
'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
Protected mode (0) 2023.08.05 [운영체제 만들기] FAT (0) 2023.08.05 부트 로더 (0) 2023.08.03 [xv6] entry (0) 2023.08.01 [xv6] mkfs (0) 2023.07.30