-
[운영체제 만들기] FAT프로젝트/운영체제 만들기 2023. 8. 5. 02:59
글의 참고
https://download.microsoft.com/download/1/6/1/161ba512-40e2-4cc9-843a-923143f3456c/fatgen103.doc
http://elm-chan.org/docs/fat_e.html#name_matching
https://en.wikipedia.org/wiki/Design_of_the_FAT_file_system
http://elm-chan.org/docs/fat_e.html#name_matching
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
- `글의 참조`에서 빨간색 볼드체로 체크된 링크는 이 글을 작성하면 가장 많이 참조한 링크다.
글의 내용
- FAT32의 큰 구조는 아래 링크를 참조하자.
- https://slidesplayer.org/slide/11646243/
FAT32 File System Structure - ppt download
1. Layout BOOT CODE (446 byte FAT1 FAT2 FAT1 FAT2 Partition Table 1 알아야 할 것들. * 섹터 : 1sector는 512 byte * cluster : 1 cluster는 8 sector 즉 4096byte 파티션마다 변경 가능함 * 0xAA55 : MBR이나 PBR은 반드시 AA55로 끝나야
slidesplayer.org
- 루트 디렉토리 엔트리
- `starting cluster hi(2byte) + starting cluster low(2byte)`를 합쳐서 다음 클러스터 엔트리를 찾는다.
- 8.3 standard name의 유래는 `name(8byte) + extenstion(3byte)`에서 유래된다. 즉, `이름.확장자` 구조이다.
- 파일의 삭제는 name의 첫 바이트에 0xE5를 명시한다.
-

출처 - http://forensic-proof.com/archives/385
- Test
: FAT 파일시스템을 소스 코드로 구현했다면, 테스트하는 방법은 하드 디스크(HDD) 이미지를 만들고 그 이미지를 FAT 파일 시스템 유틸리티를 이용해서 포맷한다. 그리고 QEMU를 사용한다면 `-drive` 옵션을 이용해서 FAT 파일 시스템으로 포맷된 HDD 이미지를 로드해서 자신이 구현한 FAT 파일 시스템 코드로 로드한 HDD 이미지에 접근이 올바르게 되는지 테스트해본다. 예를 들어, 어떤 FAT 타입(FAT12, FAT16, FAT32)으로 포맷됬는지, Volume의 전체 Sector 개수는 몇 개 인지등을 테스트해본다.
- Boo Sector
: FAT Volume

출처 - FAT32 Spec _SDA Contribution_.doc : 하나의 디스크는 여러 파티션으로 나뉠 수 있다. 그리고 각 파티션에는 하나의 파일 시스템이 매핑된다. FAT에서 말하는 Volume은 하나의 파티션을 의미한다.
: FAT에서 Volume은 크게 4개의 구역으로 나뉜다.
: 섹터와 클러시터의 단위 구하기

출처 - FAT32 Spec _SDA Contribution_.doc : BPB_BytsPerSec은 한 개의 섹터가 몇 바이트로 이루졌냐를 의미하고, BPB_SecPerClus는 한 개의 클러스터가 몇 개의 섹터로 이루어졌냐를 의미한다. 크기는 `바이트 < 섹터 < 클러스터` 순이다.
: 전체 섹터 개수 구하기

출처 - FAT32 Spec _SDA Contribution_.doc : 이 필드가 0이면 BPB_ToSec32를 사용하라고 한다. 즉, FAT12/16이 아니면 FAT32라는 것이다. 이 필드가 0이 아니면, 해당 디스크의 파일 시스템은 FAT12/16 이다.

출처 - FAT32 Spec _SDA Contribution_.doc : 여기도 잘 나와있다. BPB_TotSec32 필드가 0이면, 반드시 BPB_TotSec16이 0이면 안된다.
total_sectors = (fat_boot->total_sectors_16 == 0)? fat_boot->total_sectors_32 : fat_boot->total_sectors_16;
: FAT 영역 크기 구하기

출처 - FAT32 Spec _SDA Contribution_.doc : BPB에서 위의 필드가 0이면, FAT32라는 소리이고, BPB_FATSz32 필드에 FAT32의 FAT Region의 할당된 섹터 개수가 들어있다. 당연히 위의 필드가 0이 아니면 FAT12/16 이라는 소리다.

출처 - FAT32 Spec _SDA Contribution_.doc fat_region_sector_num = (fat_boot->table_size_16 == 0)? fat_boot_ext_32->table_size_16 : fat_boot->table_size_16;: 근데 맨 처음 `FAT Volume` 에서 보다시피 FAT 영역은 FAT Copy 라고 2개의 동일한 FAT Backup 영역을 가지고 있다.

출처 - FAT32 Spec _SDA Contribution_.doc : 실제는 FAT1만 쓰여도, Backup FAT(FAT2)가 존재하기 때문에 FAT 영역은 위의 필드를 곱한 사이즈로 봐야한다.
fat_region_sector_num = (fat_boot->table_size_16 == 0)? fat_boot_ext_32->table_size_16 : fat_boot->table_size_16; fat_region_sector_num = fat_region_sector_num * fat_boot->fat_num
: Root Directory 영역 크기 구하기

출처 - FAT32 Spec _SDA Contribution_.doc : FAT32이면 위의 필드는 0 이여야 한다. 이 필드는 루트 디렉토리안에 존재하는 디렉토리 엔트리(4바이트)라는 자료 구조의 개수를 저장하는 필드다.
root_dir_sectors = ((fat_boot->root_entry_count * 32) + (fat_boot->bytes_per_sector - 1)) / fat_boot->bytes_per_sector;: 32를 곱하는 이유는 디렉토리 엔트리 하나가 32바이트를 차기하기 때문이다. 그리고 섹터 단위로 계산하기 위해 뒤에 먼저 하나의 섹터크기를 바이트로 환산된 값을 더한다. `-1`을 하는 이유는 그냥 fat_boot->bytes_per_sector 만 더해버리면, 무조건 섹터가 1개 존재한다고 볼 수 있기 때문이다. 맨 처음에 보다시피 FAT32에서는 루트 디렉토리 영역이 존재하지 않는다. 그래서 FAT32에서 이 값이 0이 나와야 하기 때문에 -1을 하는 것이다.
: Root Directory 영역 찾기

출처 - FAT32 Spec _SDA Contribution_.doc : FAT12/16은 루트 디렉토리의 위치를 찾는 것이 매우 간단하다. 그러나 FAT32는 약간의 복잡함이 있다. 일단`BPB_RootClus`의 값을 참조해야 한다.

출처 - FAT32 Spec _SDA Contribution_.doc : 위의 필드는 루트 디렉토리의 첫 번째 클러스트 번호를 의미한다. 위에서 `This value should be 2 or ... `의 의미는 DATA 영역의 맨 처음 2개의 클러스터는 예약된 클러스터(Cluster#0, Cluster#1)이기 때문이다. 그래서 DATA 영역의 실제 클러스터의 시작은 Cluster#2번 부터 시작이다. 그래서 FAT 영역에서도 FAT#0, FAT#1 엔트리는 예약된 엔트리다.

http://www.c-jump.com/CIS24/Slides/FAT/F01_0080_first_cluster.htm first_sector_of_cluster = ((cluster - 2) * fat_boot->sectors_per_cluster) + first_data_sector;: 소스 레벨에서는 클러스터 보다는 섹터 단위가 필요하다. 왜냐면, 실제로 중요한 건 클러스트가 아닌 FAT 엔트리이기 때문이다. FAT12/16은 간단하니 FAT32의 루트 디렉토리 위치를 구하는 코드를 짜보면 위와 같다. 위에서 `cluster`는 `BPB_RootClus`를 의미한다. `-2`를 하는 이유는 다음과 같다.
" 앞에 예약된 2개의 클러스트가 한다. 그리고 이 클러스트들 또한 데이터 영역에 존재한다.
" 위의 내용에 토대로, 실제 의미있는 데이터 영역의 첫 번째 클러스트의 번호가 0이 되어야 한다. 그러려면 앞에 예약된 2개 클러스트를 빼고 계산해야 한다.
- FAT 엔트리 찾기
: FAT12/16 에서는 루트 디렉토리의 사이즈가 고정되어 있었지만, FAT32 에서는 루트 디렉토리 사이즈가 고정되지 않는다. 그리고 위치도 고정되지 않는다. 사이즈와 위치 모두 본인의 시나리오에 맞게 정할 수 있다. 그러나 위치는 대게 이전 호환성 때문인지 DATA 영역의 RESERVED 클러스터(0, 1) 다음에 두는 경우가 많다.

출처 - http://www.c-jump.com/bcc/t256t/Week01FatReview/W01_0250_fat32_root_directory_.htm
- Directory 엔트리 이름 파싱
: 디렉토리 엔트리는 32바이트 크기인데, 만약 타입이 LONG FILE NAME 타입으로 속성값을 설정하면 그 앞에 똑같은 32바이트 사이즈의 LONG FILE ENTRY가 하나 더 붙는다. 즉, 파일의 이름을 읽기 위해서 2개의 엔트리(64 바이트)를 읽어야 한다.
: `mkdosfs -F 32`를 통해 만든 FAT32 파일 시스템에 `touch ef.txt`를 하고 xxd를 통해 확인하면 아래와 같다. 일단 ROOT Directory의 위치가 0x402000에서 시작한다는 것을 알 수 있고, LONG FILE NAME을 사용하는지, 총 64 바이트(한 줄당 16 바이트)를 차지한다.
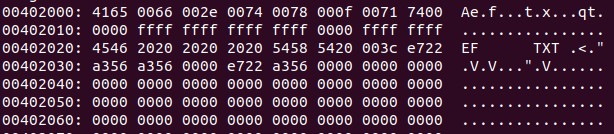
: 32바이트 시작이 디렉토리 엔트리의 시작이다. LONG FILE ENTRY는 항상 짝을 이루는 DIRECTORY ENTRY 바로 앞에 위치한다.
- FAT SFN(Short FIle Name)
: SFN은 글자가 모두 대문자여야 한다. 그리고 `확장자 3글자 + 파일 이름 8글자`해서 총 11개의 글자밖에 지원하지 않는다. 아래는 SFN이 지켜야 하는 글자 규칙이다.

출처 - FAT32 Spec _SDA Contribution_.doc : 요약하면 다음과 같다.
1" 첫 글자에서 0x00, 0x05, 0xE5는 해당 디렉토리 엔트리가 빈 엔트리라는 것을 의미한다. 그러나, 0x00과 0xE5는 범용적인 빈 디렉토리 엔트리를 의미하는 값이지만, 0x05는 캐릭터 세트가 KANJI일 때만 유효하다.
2" 첫 글자는 0x20(Space)가 될 수 없다.
3" 하나의 디렉토리내에서 이름은 유니크한 값이여야 한다.
2" 소문자 허용안함. 무조건 대문자로 컨버팅해야 한다.
3" SFN의 첫 글자(첫 바이트)를 제외하고 0x20 미만의 값을 가질 수 없다.
4" 0x22, 0x2A, ... 0x7C의 값은 SFN 글자로 사용할 수 없다.: 즉, SFN에서는 아래의 글자들이 허용되지 않는다.

출처 - https://en.wikipedia.org/wiki/ASCII : 심지어 소문자를 허용하지 않는다. 소문자로 작성해도 대문자로 저장된다. 그래서 결국 기존 데이터는 날아가게 된다.

출처 - FAT32 Spec _SDA Contribution_.doc : 위와 같이 SFN만 이용하면 엄청난 제약으로 인해 파일을 만들려고 하는데, 무슨 제약 사항이 더 많아 아예 파일을 안 만드는 게 나을 상황을 만들어 버린다. 요러한 제약들을 때문에 나온 놈이 LFN이다.
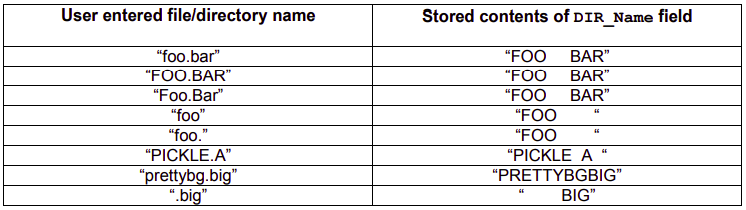
: 리눅스에서 SFN가 스펙과는 조금 달라 정리해보려고 한다. 맨 아래 `.big`은 앞에 8개의 공백(0x20)이 패딩마냥 붙게 된다.
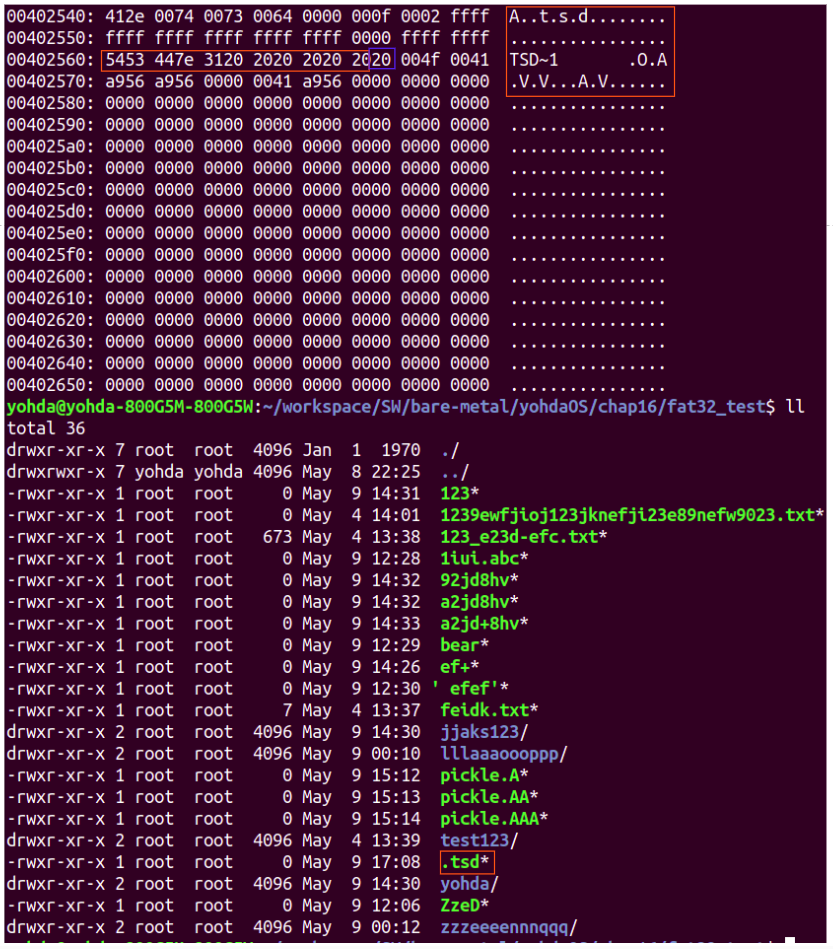
: 리눅스에서 FAT에서 `.tsd` 파일을 만들었다. FAT 스펙대로 만들어진다면, `2020 2020 2020 2020 5453 44` 여야 할 것 같지만, 그렇지 않았다. 리눅스에서 정책 상 파일 이름앞에 `.`이 붙으면 숨긴 파일로 되기 때문인 듯 한데, 정확한 내용은 더 알아봐야 될 듯 하다. 내가 만드는 yohdaOS는 리눅스를 모방하고 있지만, 이런 스펙적인 부분을 나만의 방식으로 처리하게 되면 다른 운영 체제들과 호환되지 않을 수 있으므로, 스펙을 정확히 따르도록 한다.
- FAT LFN (Long FIle Name)
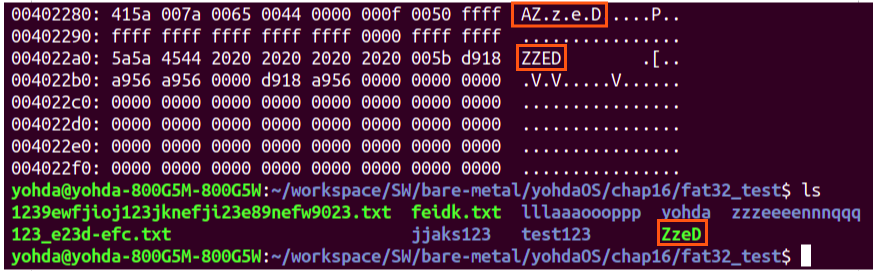
: SFN은 글자가 모두 대문자여야 한다. 그리고 `확장자 3글자 + 파일 이름 8글자`해서 총 11개의 글자밖에 지원하지 않는다. 심지어 `+`, `-` 같은 문자들을 SFN은 허용하지 않는다. 이런 모든 문자 뿐만 아니라, 전 세계 언어까지 포함하고 싶다면 LFN을 쓰면 된다. 아래의 그림은 `touch ZzeD` 명령을 통해서 파일을 하나 들었다. 그리고 해당 파일 시스템을 xxd 명령어로 내부 데이터를 파싱했다. SFN은 모두 대문자로 저장되었지만, LFN에서는 대소문자를 구별해서 저장하고 있다. 만약 SFN만 사용하면 어떻게 될까? `touch ZzeD`를 실행하면, `ZZED`라는 파일이 만들어졌을 것이다.
: 아래에서 보다시피 LFN을 지워하면 `ef+`, ` efef` 같이 `+`가 포함되거나 ` `(space) 가 포함된 이름도 사용할 수 있다. 그러므로, 이용이왕이면 반드시 LFN을 지원하는게 좋다.

: LFN은 20개까지 증가가 된다. 즉, 하나의 파일에 `1개 SFN(32B) + 20개로 LFN(640B)` 21개의 디렉토리 엔트리가 붙을 수 있다.

출처 - https://en.wikipedia.org/wiki/Long_filename : 그리고 LFN은 ASC II(1B)가 아니고 유니코드(2B) 여서 LFN 하나 당 유니 코드 13개 글자를 지원한다.
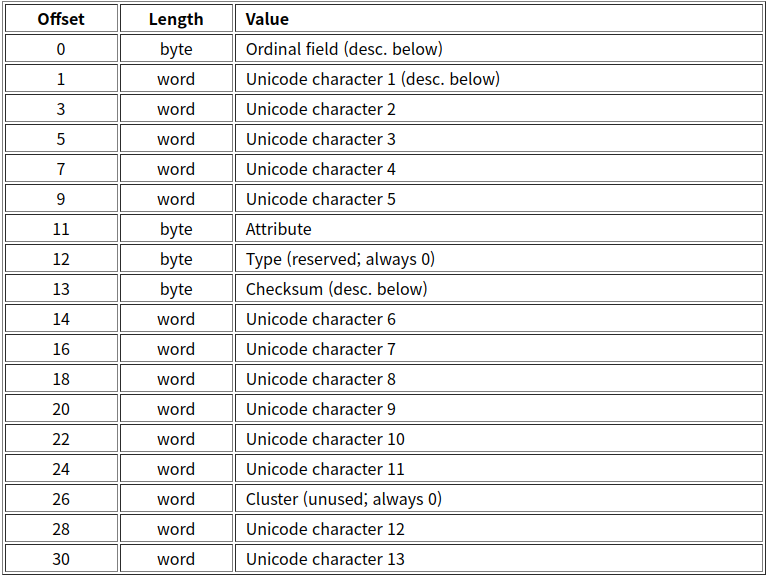
출처 - https://web.archive.org/web/20151025195158/http://home.teleport.com/~brainy/lfn.htm#organization : 그리고 아래의 글에서는 오타가 조금 있는거 같은데, 원래 유니코드에서 제시하는 기준은 첫번째 문자가 공백이고 두번째에 글자가 들어가는 걸로 되어 있지만, FAT32는 리틀-엔디안 때문에 첫 번째 바이트에 글자가 두 번째 바이트에는 공백이 들어간다.

출처 - https://web.archive.org/web/20151025195158/http://home.teleport.com/~brainy/lfn.htm#organization : 아래 그림에서 볼 수 있다시피, `t.m.p`로 되어있다.

: 그리고 LFN가 SFN에 붙는 순서가 있는데 고걸 알아야 파싱이 쉬워진다. 아래에서 보다시피, 맨 앞에 LFN가 끝놈이다.

출처 - https://web.archive.org/web/20151025195158/http://home.teleport.com/~brainy/lfn.htm#organization 
: 아래 그림에서 볼 수 있다시피, 마지막 LFN은 0x40(LAST_LONG_ENTRY)라는 FLAG와 함께 마지막 숫자(0x09)가 붙는다. 그리고 그 아래로 이전 LFN들이 붙고 마지막에, SFN(0x402200)이 붙는 것을 볼 수 있다.


: 그럼 만약 240자의 파일이 존재하면 으찌 될까? LFN 엔트리 하나당 13자를 담당하니 총 19개의 LFN이 필요할 거다.
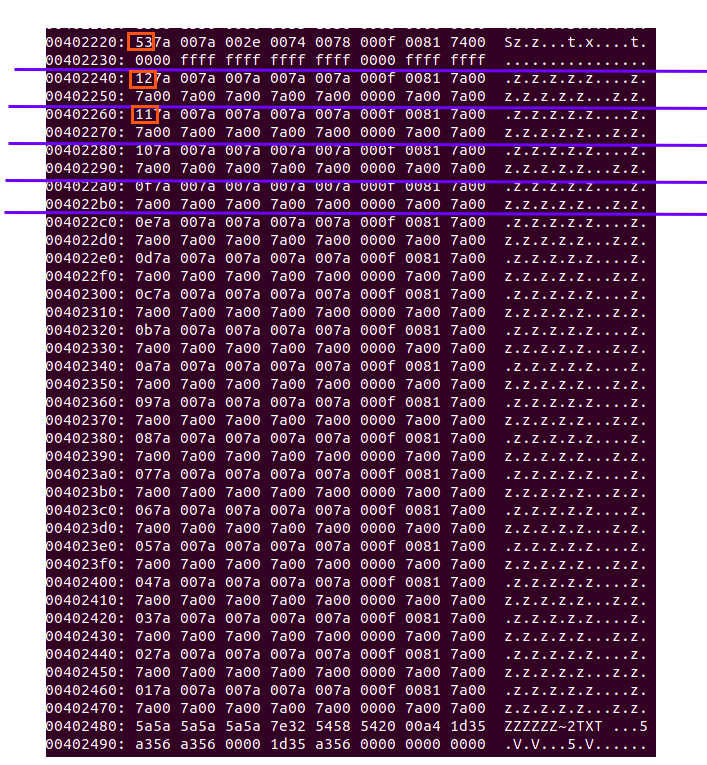
: 마지막 LFN은 자신이 마지막 LFN 이라는 플래그인 0x40과 현재 자신의 번호 0x13를 OR해서 0x53을 출력하고 있다.
- 디렉토리 하나당 사이즈
: FAT32에서는 하나의 디렉토리가 (65536(64KB) * 32)(2MB)를 지원한다는 것인데, 실제로 구현상에서 하나의 폴더에 사이즈를 할당하면 정말 낭비다. 리눅스는 한 폴더당 기본 4096(4KB)를 할당한다. 그리고 사이즈가 다 차면, 재할당하는 방식으로 진행한다.

: 마이크로소프트 FAT 관련 공식 문서에서는 2^21이 최대라고 하고 있다. 2^21은 2MB다.
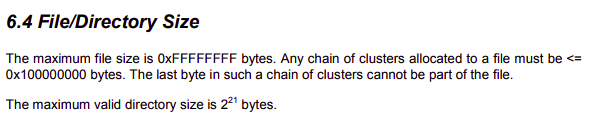
출처 - FAT32 Spec _SDA Contribution_.doc
- 디렉토리 만들기


출처 - FAT32 Spec _SDA Contribution_.doc
- 디렉토리의 끝

출처 - FAT32 Spec _SDA Contribution_.doc : 0x00이 보이면 그 디렉토리는 그 지점이 마지막이라는 뜻이다. 마치 널 문자와 같다. 이 말은 루트 디렉토리 엔트리가 순차적으로 저장된다는 말과 같다. 아래의 내용을 참고하자.

출처 - https://www.pjrc.com/tech/8051/ide/fat32.html
- 파일이 11
: 파일이 11개 여도 실제 FAT 엔트리는 8개만 존재한다. 왜냐면, 아직 파일들에 데이터를 쓰지 않았기 때문이다. 폴더는 만들기만 하면 바로 FAT이 생기지는 않는거 같고, 조금 기다리면 FAT 엔트리가 만들어 지는듯 하다. 여기서 이제 특정 파일에 몇 글자를 좀 써보자.

: 이제 아래와 같이 FAT 엔트리가 11개가 된 것이 보인다. 리눅스는 데이터가 실제 작성되기 전까지는 데이터 할당을 보류하는 메커니즘을 사용하는 것 같다. 아래에서 `0a00 0000`이 있는 위치는 8번째 바이트다(0부터 시작). 여기서 리틀 엔디안으로 읽으면, `00 00 00 0a`가 되서, 한 칸을 건너뛰고 그 다음 `0b00 0000`의 FAT엔트리를 클러스터 체인으로 연결한다. 그리고 `00 00 00 0b`가 그 다음 엔트리인 `FFFF FF0F`를 연결해서 이 엔트리가 마지막이 된다. 즉, 3개의 클러스터가 연결된 것을 간주한다. 이것도 리틀 엔디안으로 `0F FF FF FF`로 해석된다.
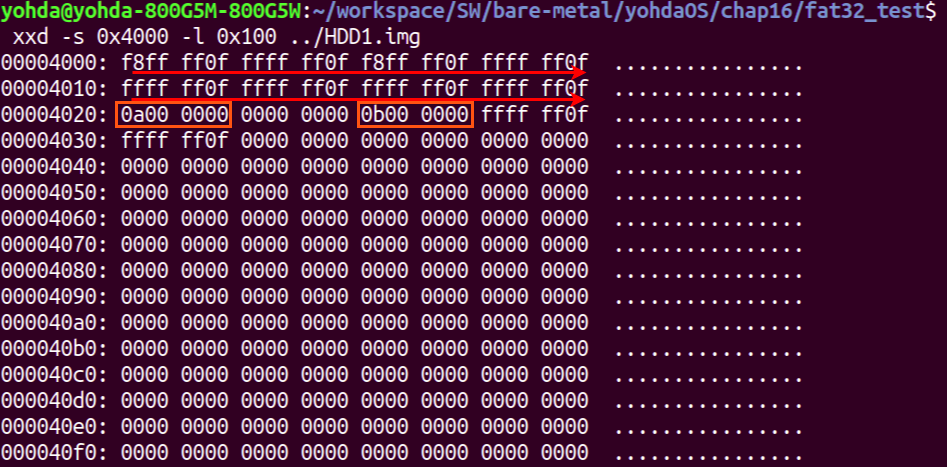
: 위의 3개의 클러스터 체인은 `213feyfh23r08ysd~ff` 파일에 매핑되어 있다는 것을 알 수 있다.
- 디스크 내용 파싱
: 디스크에 저장된 내용을 메모리로 가져올 때, 해당 포맷을 맞추면, 바로 맞춤으로 사용이 가능하다. 예를 들어, 아래와 같이 FAT32에서 LFN 는 32바이트로 형태로 정의되어 있다.


: 위의 스펙 포맷에 맞게 구조체를 선언한다고 해보자.
struct fat_lfn { // long directory entry u8 ord; //char name1[10]; u16 name1[5]; u8 attr; u8 type; u8 crc; // checksum //char name2[12]; u16 name2[6]; u16 rsvd; //char name3[4]; u16 name3[2]; // short directory entry }__attribute__((packed));: 그리고 HDD에 데이터가 아래와 같이 저장되어 있다고 하자. 그렇면, 0x402000에서 한 섹터만 그걸 메모리로 가져오고 위에 정의한 구조체로 변수하나를 선언하고 해당 변수가 0x402000을 바라보게 하면, 해당 구조체 선언된 변수들로 편하게 해당 메모리에 접근하다. 그러나 실제로는 스펙에 맞게 구조체를 정의해서 가져오는 경우도 많지만, 아닌 경우도 있다. 특히 이 파일 시스템이 이런 경우가 많은 듯 하다.
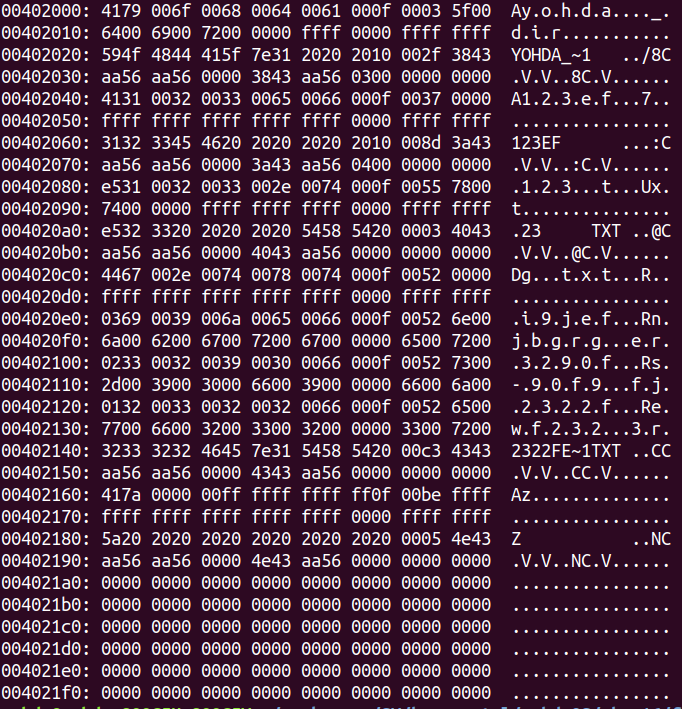
: 파일 시스템은 특히나 문자열을 주로 다룬다. 그래서 배열 활용이 필수적인데, FAT LFN의 구조를 보면 이름이 뛰엄뛰엄 떨어져 있다. 그래서 루프문으로 처리하기가 여간 까다로운것이 아니다.

- 파일 삭제
: 파일 삭제는 너무 간단하다. 디렉토리 엔트리의 맨 처음 바이트를 0xE5로 설정하면 파일을 삭제한것으로 판단한다.

출처 - FAT32 Spec _SDA Contribution_.doc : 아래의 상황에서도 FAT32 파일 시스템에서 파일을 삭제하면 디렉토리 엔트리의 맨 처음 바이트가 0xE5로 설정되는 것이 확인된다. 혹은 0x00 이여도 된다.
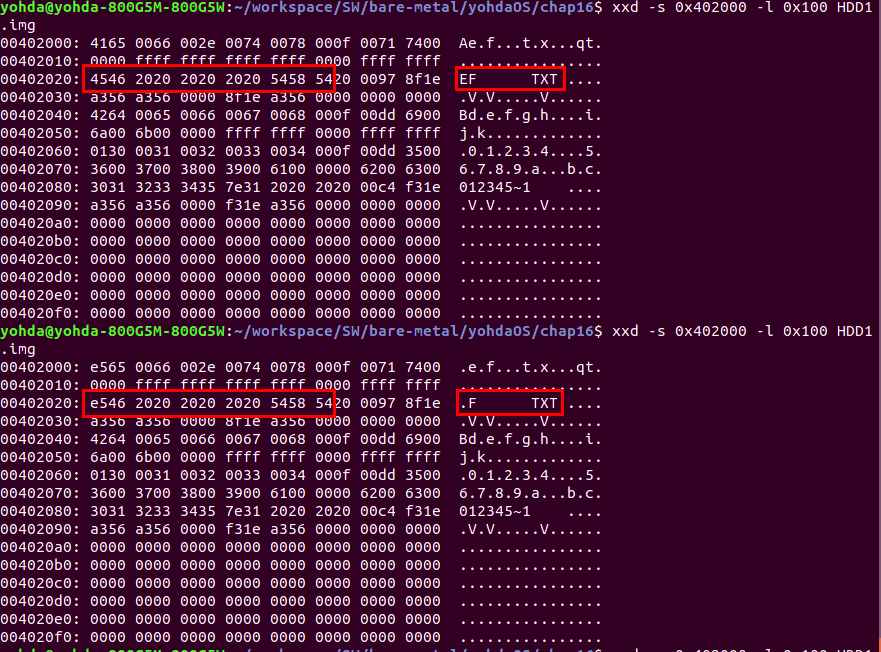
- 디렉토리 관련 구현 시 고려 사항
: FAT32의 데이터 영역에서 굳이 루트 디렉토리 영역과 클러스터 저장 영역을 나눠야 할 필요가 있을까? 루트 디렉토리 영역을 32개의 클러스터로 한정했다가 더 필요해지면? 그렇면 현재 할당되는 클러스터 영역 뒤쪽에 루트 디렉토리 영역 관련 몇 개의 클러스터를 더 할당해야 하고, 이렇면 루트 디렉토리 메모리가 정렬되어 있지 않아서 코드를 구현하는 입장에서 조금 지저분해지는 일이 발생할 우려가 있다. 차라리 데이터 영역에 `루트 디렉토리 영역`과 `클러스터 영역`을 나누지 않고 함께 저장하는 좀 더 유연한 방법일 거라 생각이 든다.
: 위와 같이 생각하는 이유는 데이터 영역을 위에서 2개의 영역으로 나눌 경우, 각 영역에 대한 포인터 주소가 필요하기 떄문이다. 그러나 데이터 영역이 하나로 관리되고 이것이 순차적으로 관리 된다면, 앞에서 부터 탐색하면서 사용가능한 클러스터를 각 파일 및 디렉토리에 할당하면 된다. 그리고 각 파일 및 디렉토리에 클러스터가 필요해지면, 데이터 영역을 관리하는 포인터를 통해 클러스터를 할당받으면 된다.
: 그런데 만약 데이터 영역을 2개의 영역으로 나눌 경우, `디렉토리 엔트리`를 관리하는 영역과 `클러스터`를 관리하는 영역이 나뉘게 되므로 2개의 포인터가 필요해지고 코드 또한 if-else 문 처러가 늘어남에 따라 복잡해질 확률이 매우 높다. 나는 개인적으로 if-else문이 없어지는 코드가 가장 멋있다고 생각한다. 그리고 이렇게 `루트 디렉토리 영역`과 `클러스터 영역`을 합쳐서 하나의 데이터 영역으로 관리가 가능한 이유는 디렉토리와 파일 이 모두 하나의 클러스터를 기본적으로 할당받기 때문이다.
: 아래의 내용은 커스텀 내용인데, 일단 스펙을 충실히 따르기 위한 과정을 먼저 구현한다. 스펙을 다 구현한 뒤, 아래의 내용에 취소선을 풀어서 반드시 확인해보자.
: 그러나 문제는 디렉토리 탐색 시, 속도가 느릴 수 있다는 문제가 있다. 예를 들어, `/A/C/E/D/R/T/S/Z/D/E/F/H/S/` 폴더를 찾는다고 해보자. 여기서 문자들은 모두 파일이다. 즉, A 폴더안에 B폴더가 있고, B 폴더안에 C 폴더가 있고, .., H 폴더안에 S 폴더가 있다. 우리는 S 폴더를 찾아야 한다. 그런데, 사실 폴더만 있겠는가? 파일이 더 많을 것이다. 이렇게 되면 A 폴더의 클러스터를 모두 읽어와서 순차적으로 탐색해서 B를 찾는다. 그리고 나서 B의 클러스터를 읽어와서 C를 찾는다. 이런 과정을 반복해서 S 폴더를 찾게 된다. 아마 시간 복잡도는 O(n*m)이 예상된다. n은 폴더의 깊이, 즉, 폴더의 개수(n). 그리고 m은 각 폴더의 파일 및 폴더의 총 개수(m). 최소 O(n) 정도까지는, 즉, 루프하나 정도까지 줄일 수 있어야 한다고 생각한다.: 위와 같은 현상은 파일 시스템에서 디렉토리 엔트리들이 곳곳에 산재되어 있어서 발생한다고 볼 수 있다. 그래서 디렉토리 엔트리들은 한군데에 모아 놓으려고 하는데, 그걸 루트 디렉토리 영역에 모아놔야 겠다고 생각했다. 그러나 문제가 있다. FAT 에서는 파일 및 폴더에 할당되는 클러스터는 자신의 데이터 영역 범위를 의미한다. 파일에서 클러스터의 의미는 해당 파일의 내용이 된다. 폴더에서 클러스터의 의미는 자신이 가지고 있는 파일과 폴더를 의미한다. 즉, A라는 폴더안에 B라는 폴더가 있기 위해서는 A 폴더가 관리하는 클러스터안에 B 폴더 엔트리가 존재해야 한다는 소리다. 그런데, 디렉토리 검색을 빨리 하기 위해서 이런 규칙을 깨고 폴더들을 모두 루트 디렉토리 영역에 저장하면 어떻게 될까? 이렇게 하면 모든 폴더는 한 개의 계층만 가지는 되는 구조가 된다. 왜냐면, 각 폴더들이 관리하는 클러스터 안에는 폴더가 존재하지 않고, 별도의 폴더 관리를 위한 클러스터 영역에 존재하기 때문이다.: 그러나 내가 아무리 생각해봐도 모든 폴더가 클러스터 곳곳에 산재되어 있을 경우. 이것을 모두 찾아내는데 걸리는 시간이 너무 오래 걸릴 것이 문제가 더 크다고 생각되어 자료 구조를 바꿔 추가 메타 데이터를 몇 개 추가하여 폴더를 빠르게 찾는것이 더 올바르다고 생각했다.: 파일 엔트리는 일반 데이터 엔트리들과 구분하지 않아도 될 듯 싶다.
- FAT 엔트리와 클러스터
: 클러스터와 달리 FAT 엔트리의 크기는 섹터가 아닌 4B다. 그래서 데이터 영역의 첫 섹터를 구하는 것은 FAT 영역의 첫 섹터를 구하는 것과는 다르다. FAT의 첫 번째 섹터는 그냥 예약 영역의 다음 바로 섹터가 된다. 그러나, 데이터 영역의 첫 섹터는 2개의 클러스터를 제외하고 계산해야 한다.
- Yohda-OS 예약 클러스터
: Yohda OS는 시스템 예약 클러스터로 일단 하나를 사용한다. 결국 FAT에서 DATA 영역에서 `예약 클러스터 2 + Yohda OS 시스템 클러스터 1개`는 DATA 클러스터 영역에서 사용할 수 없는 클러스터다. 이 시스템 클러스터에는 루트 디렉토리 엔트리 하나와 컴퓨터가 종료하기 직전에 가지고 있던 파일 시스템에 대한 메타 데이터를 저장한다.
- FAT 파일 시스템에서 `트리` 자료 구조가 필요할까?
- 문자열 보다는 인덱스 ?
: 파일 시스템에서 모든 파일은 폴더안에 존재한다. 즉, 파일을 찾는 과정은 먼저 폴더를 찾아야 한다. 그러므로, struct fat_file 구조체안에 dir_id를 추가하여 해당 파일이 속한 디렉토리의 id를 저장한다. 이걸 왜 디렉토리 구조체안에 선언하지 않을까? YohdaOS에서는 리눅스처럼 디렉토리 또한 하나의 파일이며, 디렉토리는 파일 구조체를 상속하기 때문이다. 즉, 디렉토리 구조체안에 이걸 선언하면 폴더만 id를 갖게된다. 그건 의미가 없다. 모든 파일은 디렉토리안에서만 존재할 수 있으므로, 이 변수는 파일 구조체안에 선언되어 있어야 한다.
struct fat_file { ... u32 dir_id; ... }; struct fat_dir { ... struct fat_file f; ... };: FAT 타입이 FAT12, FAT16, FAT32인지 알기 위해서는 데이터 영역을 크기를 섹터단위로 구해야 한다. 그리고 그 데이터 영역의 할당된 섹터 개수에 따라 FAT 타입이 결정된다.

출처 - FAT32 Spec _SDA Contribution_.doc - FAT
: 구조체 선언시 `__attribute__((packed))` 을 사용하지 않으면, 디스크와 구조체의 매핑이 이상해진다. 추측인데, 아마 컴파일러 컴파일시 최적화를 위해서 각 CPU 워드 사이즈에 맞게 구조체에 패딩을 추가하게 되는데, 이게 하드 디스크와 뭔가 맞지 않는 듯 하다. 그럼 MMIO에 매핑할 때는 왜 `__attribute__((packed))`을 사용하지 않을까(MMIO는 대개 `__attribute__((packed))`보다는 `volatile`을 자주 사용한다. 즉, non-cacheable 영역이거나 이미 non-locked 영역은 volatile을 사용할 것이다. AHCI 1.3 Specification 참고)?
'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
Real mode (0) 2023.08.05 Protected mode (0) 2023.08.05 GDT (1) 2023.08.05 부트 로더 (0) 2023.08.03 [xv6] entry (0) 2023.08.01