-
[리눅스 커널] Scheduler - BasicLinux/kernel 2023. 10. 30. 16:28
글의 참고
- https://blogs.oracle.com/linux/post/task-priority
- https://www.kernel.org/doc/html/v5.9/core-api/rbtree.html
- http://www.wowotech.net/process_management/447.html
- https://www.cnblogs.com/LoyenWang/p/12249106.html
- https://qiita.com/rarul/items/88d3e803d8456f50db01
- https://qiita.com/nhiroki/items/2fa7bb048118145b00cd
- http://www.iamroot.org/xe/index.php?mid=Programming&document_srl=13525
- http://www.wowotech.net/process_management/scheduler-history.html
- https://lwn.net/Articles/224865/
- https://www.xjx100.cn/news/164325.html?action=onClick
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" 스케줄러가 뭘까? 어떤 역할을 할까? 스케줄러의 역할은 실행 준비 중인 프로세스를 선택해서 특정 CPU 에 얼마동안 실행시킬지를 결정한다. 컴퓨터의 모든 동작은 CPU 를 통해서 수행된다는 점을 감안하면 스케줄러는 운영 체제의 핵심적인 역할을 수행한다고 볼 수 있다. 각 운영 체제마다 다양한 상황을 대비해서 그에 맞는 다양한 스케줄러들이 존재한다. 현재 리눅스 커널에는 RT scheduler, Deadline scheduler, CFS scheduler, Idle scheduler 가 존재한다.
- History
1. traditional scheduling machanism
" O(n) 과 O(1) 스케줄러는 고정된 time slice 를 할당받는다. 그리고, static priority 가 높을 수 록, 더 많은 time slice 를 할당 받았다. 예를 들어, nice 값이 20 인 process 에게 할당되는 default time slice 는 5ms 였다. 반면에, nice 가 0 인 process 는 default time slice 로 100ms 를 할당받았다. 이와 같이 priority 가 클 수록, 더 많은 time slice 를 가져가는 메커니즘은 스케줄링에서 가장 기본적인 방법이다. 그런데, 주의해야 할 점이 있다. CPU 처리가 많이 필요한 프로세스를 CPU bound process 라고 한다. 즉, CPU 를 많이 사용해야 하는 프로세스라고 생각하면 된다. higher priority process 는 더 많은 CPU 점유율을 얻게 될 것이다. 결국, higher priority process 는 CPU bound process 가 된다고 볼 수 있다. 그러나, 실제로는 CPU bound process 는 주로 background 로 실행되는 경우가 많기 때문에 우선 순위가 낮다. 즉, CPU bound process 는 연산 및 계산하기 때문에, user interaction 이 없고, 사용자의 실시간 반응성에 영향을 미치지 않는다(I/O bound process 는 화면에 실시간으로 뿌리거나, 사용자에게 빠른 응답성을 보여하는 경우가 많아 우선 순위가 상대적으로 높다).
" 혹시 위에서 언급된 내용을 이해했다면, fixed time slice 의 문제를 이해했다는 뜻이 된다. 기존 스케줄러들은 higher priority process 일 수록, 더 많은 time slice 를 준다고 했다. 그런데, CPU 점유울이 높은 process 는 CPU bound process 이고, 이 프로세스들은 background 로 실행되기 때문에, 우선 순위가 상대적으로 높지 않아도 된다고 했다. 즉, 우선 순위가 높아서 time slice 를 많이 줬더니, 우선 순위가 높을 필요가 없다고 한다. 이건 말 그대로 `딜레마` 다.
" 참고로, 사용자에게 더 빠른 반응성을 보이기 위해 user-interactive process 에게 높은 우선 순위를 주고 싶을 것이다. 그러나, 이건 정말 의미가 없는 짓이다. 왜냐면, 이런 프로세스들은 대개 user input event 를 기다리는 동안 blocked state 로 진입하기 때문이다. 즉, I/O bound process 에게 CPU 점유율을 높여도 의미가 없다는 뜻이다. 앞에서, background process 가 우선 순위가 높지 않아도 된다고 했다. 그런데, 정말 그럴까? 만약, 이론만 믿고 background process 에게 낮은 우선 순위를 주면, small time slice 를 할당받게 되서 퍼포먼스에 큰 영향을 줄 수도 있다(이런 타입의 프로세스들은 cache hit rate 를 증가시키는 방법이 가장 좋다. 즉, process affinity 를 설정하는 것이다).
2. the problem of traditional scheduler
" O(n) scheduler 가 O(1) scheduler 로 대체되면서 scalability 와 performance 와 같은 큰 문제들이 해결되었다. 심지어, O(n) scheduler 로 release 된 리눅스 버전을 O(1) scheduler 만 별도로 적용시키는 back-porting 하고 난리도 아니었다고 한다. 근데, 결과적으로 퍼포먼스가 좋아졌다고 한다. 그래서, 모든 문제가 해결 됬다고 생각했었나보다 ^.^
" O(1) scheduler 는 상대적으로 O(n) scheduler 보다 좋아진 것이지, 여전히 user-interactive 관련해서는 불만이 으마으마했다. 예를 들어, CPU 사용률이 높은 프로세스가 하나 실행되면, 사용자 프로그램 중에 하나가 blcoked 되는 것이다. 이와 같은 문제는 user experience 에 굉장히 치명적이다. 그래서, 많은 천재 엔지니어들이 user interaction 문제를 해결하기 위해 많은 시도를 했다. 거기에는 `fair scheduling` 를 제안한 `Con Kolivas` 도 있었다.
" Con Kolivas 는 O(1) scheduler 코드를 분석하면서, 문득 이상한 생각이 들었다. "process`s user interaction index 가 뭐지?". process scheduler 는 도대체 왜 process 의 동작을 기반으로 해서 user interaction 을 추측하는 것일까? 예를 들어, process A 는 CPU 점유율이 높은 프로세스니깐 user interaction index 를 낮추는 것과 같다. process scheduler 가 이짓을 왜 하는것일까? 물론, process scheduler 는 시스템을 busy 하게 만들기 위해 최적의 스케줄링 알고리즘으로 동작을 해야 한다. 그러나, 각 process 의 user interaction 성향을 파악하는 것은 완전 말도 안되는 행위다. 왜냐면, 예외 케이스가 너무 많았기 때문이다. AI 프로세서에서 해야 할 일을 스케줄러에서 하고 있어서 문제가 발생했던 것이다.
" 왜 확실한 factor 를 두고 엉뚱한 user interaction index 에 초점을 두는 것일까? 그렇다면, 확실한 factor 는 뭘까? 바로 `static priority` 다. 이 값이면 충분하다. 이제 scheduler 는 user interactivity 를 추측할 필요가 없다. 이제 정리할 때가 됬다. 위에서 언급 되었던 fixed-time slice 이슈와 static priority 만 고려해서 만든 RSDL(Rotating Staircase Deadline) scheduling 을 소개할 때가 됬다. 그전에, 먼저 staircase scheduler 에 대해서 짧게 알아보자.
3. Staircase scheduler [참고1]
" staircase scheduler 는 흔히 SD 라고 불리며, O(1) scheduling 과는 완전히 다른 메커니즘이다. SD 에서는 dynamic priority 를 아예 배제한다. 대신 SD 의 목적은 `completelty fairness` 다. O(1) scheduler 는 스케줄링 알고리즘 자체는 복잡하지 않다. 그런, dynamic priority 를 계산하는 과정이 상당히 복잡했다. 그러나, SD 는 굉장히 심플한 알고리즘이다. 그런데, 여러 케이스와 실험을 통해 interactive process 의 반응성이 O(1) 보다 SD 알고리즘을 사용했을 때, 더 개선되었다는 것이 검증됬다.
" SD 도 O(1) 과 마찬가지로, active array 가 존재했고, 그 안에는 개별 priority queue 가 존재했다. 대신, next running process 를 선택할 때, SD 는 직접 active array 를 탐색했다(O(1) 은 active bitmap 을 탐색). 그리고, O(1) 같은 경우는 process 가 time slice 를 모두 소진하면, expired array 로 푸쉬됬지만, SD 는 expired array 가 아닌, active array 의 현재 priority level 보다 한 단계 아래인 priority queue 로 푸쉬됬다. 여기서 주의할 점이 있다. 태스크가 lower-priority queue 로 푸쉬될 때, 자신의 priority 를 바꾸는 것이 아니다. 단지, lower-priority queue 에 푸쉬만 되는 것이다. time slice 를 전부 소모하면, lower-priority queue 로 푸쉬되는 과정은 계속 반복된다(알고리즘의 이름 유래는 여기서 나온 것이다). 이렇게 계속 내려가다가, lowest priority level 을 만나게 되면, 그리고 여기서도 time slice 를 모두 소진했다면, 자신의 초기 priority level 보다 한 단계 낮은 priority queue 에 푸쉬된다. 예를 들어, 프로세스의 priority 가 1 이라고 가정하자. 이 값이 마지막 priority level 인 140 에 도달했고 여기서도 time slice 를 모두 소진하면, 해당 프로세스는 active array 의 priority 2 queue 로 푸쉬된다.
" 그러나, 이 때, 단순히 priority level 이 낮아지는 것으로 끝나는 것이 아니다. time slice 가 2배가 된다. 예를 들어, 기존 priority 1 queue 에 있을 때는 time slice 가 10ms 였다면, scheduling cycle 을 한 바퀴 돌고나서 priority 2 queue 에 푸쉬될 때는 time slice 가 20ms 가 된다. 참고로, 위 과정들은 모두 ordinary process 들에게만 적용된다. real-time process 들은 기존에 사용하던 스케줄링 알고리즘을 그대로 사용한다(FIFO & RR).
" SD 는 process starvation 을 막을 수 있다. 왜냐면, high-priority process 들은 계속 내려가기 때문에, 어느 시점에는 low-priority process 들보다 우선 순위가 낮아지는 지점이온다. 이 때, low-priority process 들에게 실행 기회가 생긴다. 예를 들어, high-priority 가 2 이고 low-priority 가 5 라고 할 때, 언제가는 high-priority 가 5 미만으로 내려가는 시점이 온다. 이렇게 함으로써, process starvation 을 막을 수 있다. 그렇다면, 문제의 interactive process 는 어떨까? interactive process 가 sleep 에 빠지면, 동일 우선 순위를 갖는 프로세스들은 아무 상관없다는 듯이 계속 자기 일을 수행해 나갈것이다. 그렇다 보면, 동일 우선 순위였던 프로세스들이 한 단계씩 점차 lower-priority queue 에서 수행되게 된다. interactive process 가 wake-up 했을 때는, 이전 higher-priority queue 에 그대로 있고 다른 친구들은 lower-priority queue 에 있기 때문에, scheduler 에 의해서 빠르게 선택될 것이다. 즉, 반응성을 해지지 않는다는 뜻이다.
" SD 는 알고리즘 구현측면에서 O(1) 과 동일한 자료 구조들을 사용하지만, dynamic priority 를 계산하는 복잡한 코드를 제거했고, 거기다가 expired array 를 제거함으로써 알고리즘 자체가 상당히 심플해졌다. 또한, 구현측면에서 상당히 어려울 것 같았던 complete fairness 를 코드 레벨에서 입증했다는 것에 의의가 있다.
4. RSDL scheduler [참고1 참고2 참고3]
" RSDL scheduling 은 O(1) scheduler 에서 사용하던 자료 구조를 그대로 사용한다. 그러나, process interaction index 를 factor 에서 제거했다. 이 섹션에서는 RSDL 의 핵심 개념인 Rotating, Staircase, Deadline 에 대해서 알아보기로 한다.
1. Staircase : process scheduling 과정에서 priority 가 조금씩 낮아지는 의미한다. 기존 scheduling 에서는 process`s time slice 는 statis priority 와 매칭됬었다. RSDL 에서도 여전히 time slice 는 존재하지만,
예를 들어, process` priority 가 120 이라고 가정하자. 이 때, 스케줄러를 통해서 할당받은 total time slice 는 priority 120 ~ 139 에서 나눠서 사용된다. 예를 들어, priority queue 120 에서 6ms 를 할당받았다고 가정하자. 6ms 를 모두 소진하면, 한 단계 아래 prioirity 로 내려간다. 즉, priority queue 121 로 이동한다.
2. Rotating : rotating 은 priority level 이 낮아지거나 높아지는 것을 의미한다. 주로, RSDL 은 fairness 가 핵심으로 minor rotation (step down priority) 에 초점을 맞춘다.
3. Deadline : rotating 가 마찬가지로 fairness 를 위해서 사용되는 값이다. RSDL 은 group 단위의 time qouta 를 제안한다. 이 값을 모두 소진하면, next lower priority queue 로 푸쉬되는데, 자세한 설명은 뒤에서 다시 다룬다." RSDL 의 핵심 메커니즘은 `completely fair` 를 기반으로 한다. RSDL 은 기존 알고리즘들과는 달리 복잡한 dynamic priority 할당 알고리즘은 존재하지 않는다. 대신, RSDL 에서 재미있는 부분은 각 priority level 마다 group time slice quota 를 제공한다는 것이다. 이 값을 Tg 라고 약속하자. 그리고, 동일한 priority level 에 있는 모든 프로세스들은 동일한 process time quota 를 할당받게 된다. 이 값을 Tp 라고 약속하자. 만약, 프로세스가 자신의 Tp 를 모두 소진할 경우, next lower priority level 로 내려간다. 이 과정은 SD 와 동일하다. 그런데, RSDL 에서는 이 과정을 `minor rotation` 이라고 부른다. 아래 그림에서 minor rotation 에 대해서 보여주고 있다. 이 과정은 우선 순위가 한 단계씩 감소하는 것을 의미한다. 예를 들어, process A 가 priority 1 queue 부터 scheduling cycle 이 시작했다면, priority 140 queue 까지 한 단계식 내려간다. priority 140 queue 에서 모든 time quota 를 소진하면, priority 2 queue 로 들어가게 된다. 그리고, 다시 scheduling cycle 이 시작되면, priority 2 queue 에서 또 한 단계식 내려간다. priority 140 queue 에서 모든 time quota 를 소진하면, 이번에는 priority 3 queue 로 들어가게 된다.

" SD 에서는 low-priority process 가 만약에 굉장히 아래쪽 priority queue(예를 들어, priority 138 level) 에 있으면, 모든 higher-priority process 들이 자기와 동일한 혹은 이하의 priority queue 에 푸쉬되어야 CPU 를 점유할 수 있게된다. 즉, low-priority process 의 waiting time 을 예측이 불가능하다. 그런데, RSDL 에서는 priority queue group 에 할당된 Tg(group time quota) 를 모두 소진하면, 개별 태스크에게 할당된 Tp(process time quota) 를 아직 모두 소진하지 않았음에도, 이 그룹에 속한 모든 태스크들을 강제로 next lower priority queue 로 푸쉬한다. 이렇게 함으로써, low-priority process 들의 waiting time 을 예측할 수 가 있다(RSDL 에서 DL(`DeadLine`)이 Tg 를 의미한다).
" 만약, 프로세스가 할당받은 time slice 를 모두 소진하면, expired queue 로 푸쉬된다. 이 때, 최초 시작됬던 priority level 로 푸쉬된다. 참고로, 이 과정을 major rotation 이라고 하지 않는다. 그렇다면, time slice 와 time quota 의 차이는 뭘까?

" major rotation 은 active queue 와 expired queue 를 exchange 함으로써, scheduling cycle 을 다시 시작하는 것을 의미한다. major rotation 이 발생하는 케이스는 2가지로 나뉜다.
1. active queue 가 empty 인 경우.
2. active queue 의 모든 프로세스들이 lowest priority 에 도달한 경우.- Scheduling class
" 리눅스 커널 v2.6.23 부터 리눅스에서 scheduling class 라는 것을 도입했다. scheduling class 는 다양한 상황에 맞게 스케줄링 정책을 모듈화할 수 있도록 했다. 즉, 스케줄러 코드의 확장성을 향상시켰고 새로운 스케줄러를 추가하기 쉽게 만들어 주었다. 리눅스에서는 스케줄러를 2가지 파트로 나눈다.
1. common part : 코어 스케줄링 파트를 의미한다.
2. specific part : 각 스케줄러마다 다른 특성을 나타내는 파트를 의미한다." 코어 스케줄링 코드에서 specific scheduling class 를 호출하는 식으로 스케줄링이 수행된다. specific part 에서는 `struct sched_class` 구조체를 작성해서 코어에 등록해야 한다.
// kernel/sched/sched.h - v6.5 struct sched_class { .... void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); .... void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags); struct task_struct *(*pick_next_task)(struct rq *rq); .... };- enqueue_task : 프로세스를 현재 스케줄러가 관리하는 런큐에 삽입한다.
- dequeue_task : 프로세스를 현재 스케줄러가 관리하는 런큐에서 제거한다.
- check_preempt_curr : 프로세스가 새로 생성되거나 wakeup 했을 때, 현재 CPU 에서 동작 중 인 프로세스를 선점할 수 있는지를 체크해야 한다. 만약, 선점이 가능하다면 동작 중인 프로세스에 TIF_NEED_RESCHED 플래그가 설정되어 있어야 한다.
- pick_next_task : 런큐에서 실행하기 가장 적합한 프로세스를 선택한다. 이 역할이 스케줄러에서 가장 핵심적인 파트다." 참고로, 이전에는 `struct sched_class` 에 `->next` 라는 필드가 존재해서 다음 스케줄러를 가리키도록 했다. 그러나, 리눅스 커널에서 스케줄러가 선택되는 순서가 고정(`stop_sched_class -> dl_sched_class -> rt_sched_clas -> fair_sched_class -> idle_sched_class`) 되어 있다보니 `->next` 를 사용하지 않고, linker script 에 작성하도록 했다. 아래와 같이 작성할 경우, 어떤 효과가 있을까?
// include/asm-generic/vmlinux.lds.h - v6.5 /* * The order of the sched class addresses are important, as they are * used to determine the order of the priority of each sched class in * relation to each other. */ #define SCHED_DATA \ STRUCT_ALIGN(); \ __sched_class_highest = .; \ *(__stop_sched_class) \ *(__dl_sched_class) \ *(__rt_sched_class) \ *(__fair_sched_class) \ *(__idle_sched_class) \ __sched_class_lowest = .;" 주소를 연속적으로 할당하기 때문에, 메모리에 다음과 같이 저장된다. 오케이. 주소에 연속이기 때문에 배열처럼 사용할 수 있을 것 같다. 그래서 각 클래스를 순회하는 매크로의 형태는 다음과 같다.

// kernel/sched/sched.h - v6.5 /* Defined in include/asm-generic/vmlinux.lds.h */ extern struct sched_class __sched_class_highest[]; extern struct sched_class __sched_class_lowest[]; #define for_each_class(class) \ for_class_range(class, __sched_class_highest, __sched_class_lowest)" for_class_range 매크로는 __sched_class_highest 부터 __sched_class_lowest 까지 순회한다. 즉, 스케줄링 클래스의 우선 순위가 높은 순서로 순회한다. 그렇다면, 리눅스 커널에는 어떤 스케줄링 클래스들이 존재할까? v6.5 를 기준으로 총 5개가 존재한다.
// kernel/sched/sched.h - v6.5 extern const struct sched_class stop_sched_class; extern const struct sched_class dl_sched_class; extern const struct sched_class rt_sched_class; extern const struct sched_class fair_sched_class; extern const struct sched_class idle_sched_class;" 리눅스에서 사용되는 scheduling class 는 `stop_sched_class -> dl_sched_class -> rt_sched_clas -> fair_sched_class -> idle_sched_class` 가 있다. 모든 프로세스는 하나의 scheduling strategy 에 대응되고, 각 scheduling strategy 는 하나의 scheduling class 에 대응된다. 그런데, 스케줄링 정책이 뭘까?
1. scheduling policy [참고1 참고2 참고3]
" 스케줄러가 등장한 배경이 뭘까? 스케줄러는 시스템을 계속 bsuy 한 상태로 만들기 위해 등장했다. 즉, CPU 를 놀게하지 않고 계속 일하게 만드는 것이 스케줄러의 등장 배경이다. 즉, 스케줄러는 퍼포먼스 증가를 위한 목적으로 스레드를 스케줄링하지 않는다는 것이다. 예를 들어, NUMA 시스템에서 app X 가 node A 에서 열심히 실행중이다. 이 때, node B 에 있는 한 프로세서가 한가해졌다. node B 의 프로세서를 busy 하게 만들고 싶어서, 스케줄러가 node A 에서 실행중이던 app X 를 node B 의 프로세서에게 할당했다. 그런데, app X 는 node A 에서 작업중에 갑자기 node B 로 왔기 때문에, 이전 node A 의 메모리에 액세스가 필요했다. 그러나, app X 는 이제 node B 에 있기 때문에, node A 의 메모리에 액세스하는 것은 퍼포먼스 저하가 우려되는 상황이 되었다.
: 위 사례를 통해 알 수 있는 사실이 있다. `performance sensitive application` 들은 종종 자신이 어느 위치(어떤 프로세서, 어떤 누마 노드)에서 실행되느냐에 따라 퍼포먼스가 달라진다는 것이다. 그래서, 리눅스 스케줄러는 스케줄링 정책이라는 것을 도입해서 특정 스레드가 어디에서 혹은 얼마나 실행되어야 하는지를 결정하도록 한다. 스케줄링 정책은 크게 2가지로 나눌 수 있다.
1. Normal policies : normal priority 를 갖는 스레드를 의미한다. 흔히, time-sharing scheduling 이라고 불린다.
2. Realtime policies : time-sensitive 스레드를 의미한다. 그리고, 이 스레드들은 time-slice 가 종속되지 않는다. 대표적으로, 아래와 같은 경우들이 있다.
- block 되기전까지는, 계속 실행(without interruputs)되어야 한다.
- exit 되기전까지는, 계속 실행되어야 한다.
- 자기 스스로 yield 하기 전까지는 계속 실행되어야 한다.
- 자신보다 높은 우선 순위의 스레드가 선점하기 전까지 계속 실행되어야 한다." 리눅스에서 사용하는 6개의 정책들을 2가지 타입으로 분류하면 다음과 같다.
real-time policies SCHED_DEADLINE, SCHED_FIFO, SCHED_RR time-sharing policies SCHED_OTHER, SCHED_BATCH, SCHED_IDLE " SCHED_DEADLINE 은 자동으로 제일 강한 우선 순위를 갖기 때문에, 인터럽트를 제외한 그 누구도 선점하지 못한다. SCHED_FIFO 와 SCHED_RR 은 우선 순위가 높긴 하지만, 그래도 디테일한 우선 순위를 조정이 가능하다. 반면에, time-sharing policies 들은 우선 순위를 변경하지 못한다. 대신에 nice 값을 변경해서 실행 점유율을 높일 수 는 있다.
" 아래 소스 코드는 리눅스 커널에 정의된 6개의 스케줄링 정책을 보여준다. 그런데, SCHED_OTHER 이 보이지 않는다. SCHED_OTHER 과 SCHED_NORMAL 은 동일한 의미로 사용된다. 단지, 유저 스페이스에서 SCHED_OTHER 을 사용하고(POSIX 계열), 커널 스페이스에서는 SCHED_NORMAL 을 사용한다.
// include/uapi/linux/sched.h - v6.5 /* * Scheduling policies */ #define SCHED_NORMAL 0 #define SCHED_FIFO 1 #define SCHED_RR 2 #define SCHED_BATCH 3 /* SCHED_ISO: reserved but not implemented yet */ #define SCHED_IDLE 5 #define SCHED_DEADLINE 6" 그러나, 하나의 scheduling class 는 여러 개의 scheduling strategy 에 대응될 수 있다. 예를 들어, real-time scheduler 는 우선 순위를 기준으로 프로세스를 선택할 것이다. 그리고, 프로세스가 생성될 때 마다, 프로세스에게 할당될 scheduling strategy 를 할당해야 한다.
Scheduling Class Scheduling policies Comment stop_sched_class stop_sched_class 는 스케줄링 정책이 없다. 유저 스페이스에서 볼 때, stop_sched_class 의 priority value 는 99 와 같다. 그러나, 이 클래스에는 우선 순위라는 개념이 없다. 그냥 가장 강력한 우선 순위를 갖는다고 보면 된다. 이 클래스는 cpu migration 를 담당하는 커널 스레드(migration/%u)에서만 사용되고 있다. dl_sched_class SCHED_DEADLINE 스레드에 SCHED_DEADLINE 을 설정하면, dl_sched_class 가 사용된다. stop_sched_class 다음으로 우선 순위가 높다. rt_sched_class SCHED_FIFO, SCHED_RR 스레드에 SCHED_FIFO, SCHED_RR 를 설정하면, rt_sched_class 가 사용된다. dl_sched_class 다음으로 우선 순위가 높다. 실제 우선 순위를 변경가능한 범위가 rt_shced_class 다. fair_sched_class SCHED_OTHER, SCHED_BATCH, SCEHD_IDLE idle_sched_class idle_sched_class 는 idle_task(swapper/%d)에 의해서만 선택되는 클래스다. 이 스레드는 각 CPU 런큐에 실행 가능한 스레드가 없을 경우에 실행된다. 참고로, SCHED_IDLE 정책과 idle_task 는 전혀 다른 개념이다. 그렇기 때문에, idle_sched_class 와 SCHED_IDLE 도 다른 개념이라 볼 수 있다. : 스케줄러가 다음에 실행 할 프로세스를 선택할 때, scheduling class 의 우선 순위를 기준으로 `pick_next_task` 함수를 호출한다. 그러므로, SCHED_FIFO 정책이 설정된 프로세스는 SCHED_NORMAL 정책이 설정된 프로세스보다 항상 먼저 실행될 수 밖에 없다.
// kernel/sched/core.c - v6.5 static inline struct task_struct *pick_task(struct rq *rq) { const struct sched_class *class; struct task_struct *p; for_each_class(class) { p = class->pick_task(rq); if (p) return p; } BUG(); /* The idle class should always have a runnable task. */ }// kernel/sched/sched.h - v6.5 /* Defined in include/asm-generic/vmlinux.lds.h */ extern struct sched_class __sched_class_highest[]; extern struct sched_class __sched_class_lowest[]; .... #define for_each_class(class) \ for_class_range(class, __sched_class_highest, __sched_class_lowest)2. static vs dynamic [참고1 참고2 참고3]
: 리눅스에서 우선 순위는 여러 가지 측면에서 분류가 가능하다. 그 중에서 static 과 dynamic 측면에서 우선 순위를 바라볼 필요가 있다. 리눅스 내부적으로 우선 순위를 1 ~ 139 로 나누고 있으며, 1 ~ 99 는 statis priority, 100 ~ 139 는 dynamic priority 로 나눈다. 여기서 숫자가 작을 수 록 높은 우선 순위를 나타낸다. static 과 dynamic 을 나누는 기준은 스케줄러가 수정이 가능한지 여부로 판단한다.
5.4.1 Static Task Prioritization and the nice() System Call
.... Apart from its initial value and modifications via the nice() system call, the scheduler never changes a task’s static priority. Static priority is the mechanism through which users can modify task’s priority, and the scheduler will respect the user’s input (in an albeit relative way). A task’s static priority is stored in its static_prio variable. Where p is a task, p->static_prio is its static priority.
- 참고 : https://www.inf.ed.ac.uk/teaching/courses/os/prac/linux_cpu_scheduler.pdf
5.4.2 Dynamic Task Prioritization
The Linux 2.6.8.1 scheduler rewards I/O-bound tasks and punishes CPU-bound tasks by adding or subtracting from a task’s static priority. The adjusted priority is called a task’s dynamic priority, and is accessible via the task’s prio variable (e.g. p->prio where p is a task).
- 참고 : https://www.inf.ed.ac.uk/teaching/courses/os/prac/linux_cpu_scheduler.pdf: static priority 는 2가지 타입이 존재한다.
1. SCHED_FIFO : 이 정책은 `first-in-first-out` 메커니즘을 기반으로 만들어졌다. 만약, 시스템에 SCHED_FIFO 스레드가 존재할 경우, 다른 작업들을 선점하고 자기의 일을 마무리 할 때 까지 실행된다. SCHED_FIFO 스레드는 time slice 가 없다.
2. SCHED_RR : SCHED_FIFIO 와 거의 유사하다. 그러나, SCHED_RR 스레드는 time slice 를 기반으로 동작하며, 항상 SCEHD_FIFO 에 의해서 선점된다. SCHED_RR 스레드는 priority 를 기반으로 스케줄링되고, 할당받은 time slice 를 모두 소진했는데, 일을 마무리 하지 못할 경우, priorty queue 의 맨 뒤로 이동한다." 아래 표는 리눅스 커널의 priority range 에 따른 스케줄링 정책을 매핑해본 것이다.
kernel priority scheduling policy -1 SCHED_DEADLINE & 일부 태스크 0 SCHED_FIFO, SCHED_RR (highest) 1 ↑ 2 ↑ ... real-time scheduling 97 ↓ 98 SCHED_FIFO, SCHED_RR (lowest) 100 SCHED_OTHER, SCHED_BATCH (highest) 101 ↑ 102 ↑ ... time-share scheduling 119 ↑ 120 SCHED_OTHER (default value) 121 ↓ .... time-share scheduling 138 ↓ 139 SCHED_OTHER, SCHED_BATCH (min) - Priority of ordinary process
: CFS 는 `Completely Fair Scheduler` 의 약자다. CFS 는 멀티 프로세서 환경에서 가장 이상적인 스케줄링을 지향하고 있다. 즉, `완벽하게 평등한 스케줄링` 이라는 의도로 만들어졌다. CFS 와 이전 스케줄러의 핵심적인 차이는 CFS 에서는 `time slice` 라는 개념이 없다는 것이다. 대신 `CPU 사용 시간 비율` 이라는 개념을 도입했다. 예를 들어, 2개의 동일한 우선 순위를 갖는 프로세스가 하나의 CPU 에서 동작할 경우, 각 CPU 에게 50%의 CPU usage time 을 할당한다. 이러한 방식은 CFS 가 만들어진 의도에 부합한다고 볼 수 있다.
: 그런데, 위의 예시는 프로세스들이 동일한 우선 순위일 경우를 가정한다. 만약, 우선 순위가 같은데, 서로 다른 가중치를 두고 싶다면 어떻게 해야 할까?
1. `weight` 라는 개념을 도입한다. weight 은 각 프로세스의 우선 순위를 나타낸다. 각 프로세스는 weight 을 기준으로 CPU time 을 할당받는다. 예를 들어, process A 와 B 가 있다고 가정하자. A 는 1024 weight 을, B 는 2048 weight 을 갖는다. 이 때, process A 는 `1024 / ( 1024 + 2048 )` 로 33.3 %를 할당받는다. process B 는 `2048 / ( 1024 + 2048 )` 로 66.7% 를 할당 받는다.
예시에서도 볼 수 있다시피, weight 이 클수록 더 많은 CPU time 을 할당받는다. 결국 아래와 같은 공식이 만들어 짐을 알 수 있다.

2. `nice` 라는 개념을 도입한다. nice 는 weight 가 1:1 대응 관계를 이루고 있다. 즉, 하나의 nice 값은 하나의 weight 값에 대응한다는 뜻이다. nice 값은 특정 숫자로 표현되며, 범위는 [-20, 19] 를 갖는다. nice 는 값이 작을 수 록, 더 큰 우선 순위를 갖는다. nice 와 weight 은 1:1 대응된다고 했으니, nice 가 작을 수 록, 더 큰 weight 으로 변환이 된다는 뜻이다.: 위에 내용들에 부합되는 스케줄링 정책은 SCHED_OTHER & SCHED_BATCH 다. 즉, nice 와 weight 은 time-sharing scheduling 을 사용하는 스케줄링 정책에서만 적용된다고 볼 수 있다. 리눅스 커널에서 제공하는 nice 값은 아래와 같다.
// kernel/sched/core.c - v6.5 /* * Nice levels are multiplicative, with a gentle 10% change for every * nice level changed. I.e. when a CPU-bound task goes from nice 0 to * nice 1, it will get ~10% less CPU time than another CPU-bound task * that remained on nice 0. * * The "10% effect" is relative and cumulative: from _any_ nice level, * if you go up 1 level, it's -10% CPU usage, if you go down 1 level * it's +10% CPU usage. (to achieve that we use a multiplier of 1.25. * If a task goes up by ~10% and another task goes down by ~10% then * the relative distance between them is ~25%.) */ const int sched_prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, };: nice 를 weight 으로 변환하는 공식은 다음과 같다. 여기서 1.25 라는 값은 매번 프로세스가 nice 값을 1씩 감소시킬 때 마다, 10%의 CPU time 을 더 얻기 위해서는 지수로 1.25 를 사용해야 한다. `weight 1024` 는 `nice 0` 에 대응된다. weight 1024 는 특별히 NICE_0_LOAD 라고 부르며, 디폴트로 대부분의 프로세스는 NICE_0_LOAD 값을 갖는다.

: nice 값이 1 이 증가할 때마다, CPU 점유율이 10% 증가한다는 것은 nice 값이 크게 증가하면 리얼 타임 스케줄링과 비슷해진다는 것을 의미한다. 왜냐면, nice 값이 굉장히 클 경우, CPU 점유율이 그만큼 증가하므로, 일을 완전히 처리할 때 까지 CPU 를 계속 점유하기 때문이다(리얼 타임 스케줄링은 일이 끝날 때 까지 실행된다). 그런데, 차이는 존재한다. 리얼 타임 스케줄링은 선점이 되지 않는다. 그러나, time-sharing 은 선점을 보장할 수 없기 때문에, 레이턴시가 생길 수 있다.
- Scheduling period
" 2개의 프로세스가 있다고 가정하자. 각 프로세스에게 10ms 를 할당할 경우, 전체 스케줄링 주기는 20ms 다. 만약, 5개의 프로세스가 존재한다면, 스케줄링 주기는 50ms 가 된다. 이번에는 거꾸로 생각해보자. 스케줄링 주기가 6ms 일 때, 프로세스가 2개 라면 어떨까? 이 때, 각 프로세스는 3ms 씩을 할당받는다. 만약, 프로세스가 6개라면, 각 프로세스는 1ms 를 할당받는다. 결과적으로, 프로세스가 수가 늘어날 수 록, time slice 를 작게 할당받게 된다. 만약, 프로세스가 너무 자주 스케줄링되면, 컨택스트 스위칭 오버헤드가 그 만큼 더 커지게 될 것이다. 이 말은 CFS 스케줄러의 스케줄리 주기가 고정이면 안된다는 것을 의미한다. 왜냐면, 프로세스가 수가 점점 증가하는데, 스케줄링 주기가 고정이라면, 각 프로세스에게 할당되는 time slice 가 작아지면서 그 만큼 컨택스트 스위칭이 더욱 빈번하게 발생하게 될 것이다.
// kernel/sched/fair.c - v6.5 /* * Targeted preemption latency for CPU-bound tasks: * * NOTE: this latency value is not the same as the concept of * 'timeslice length' - timeslices in CFS are of variable length * and have no persistent notion like in traditional, time-slice * based scheduling concepts. * * (to see the precise effective timeslice length of your workload, * run vmstat and monitor the context-switches (cs) field) * * (default: 6ms * (1 + ilog(ncpus)), units: nanoseconds) */ unsigned int sysctl_sched_latency = 6000000ULL; .... /* * Minimal preemption granularity for CPU-bound tasks: * * (default: 0.75 msec * (1 + ilog(ncpus)), units: nanoseconds) */ unsigned int sysctl_sched_min_granularity = 750000ULL; .... static unsigned int sched_nr_latency = 8;" 결국, 스케줄링 주기가 동적으로 변해야 한다는 것을 의미한다. 판단 기준은 다음과 같다. 결국, 아래와 같이 스케줄링 주기가 동적으로 변경되는 이유는 각 태스크에게 최소 작업 시간을 보장해주기 위해서다. CFS 에서는 이 값을 `minimum granularity time` 라고 한다. CFS 에서 minimum granularity time 은 0.75ms 이다. 즉, CFS 를 통해 스케줄링되는 모든 태스크는 최소 0.75ms 는 할당받는다는 뜻이다.
1. 현재 실행가능한 태스크 개수 <= 8 : 스케줄링 주기를 6ms 로 고정
2. 현재 실행가능한 태스크 개수 > 8 : 현재 실행가능한 태스크 개수 * 0.75ms" nr_running 은 현재 시스템에 존재하는 TASK_RUNNING 상태의 태스크 개수를 의미한다. enqueue_task 함수가 호출될 때마다, 1씩 증가한다. dequeue_task 함수가 호출되면 1씩 감소한다. sched_nr_latency 은 CFS 에서 default 로 설정한 스케줄링 주기인 6ms 를 보장하는 태스크 개수를 의미한다. 즉, CFS 에서는 태스크 개수가 8개 까지는 스케줄링 주기를 6ms 로 고정한다는 뜻이다. 즉, TASK_RUNNING 태스크가 8개면, 각 태스크에게 할당되는 time slice 가 0.75ms 된다. CFS 는 여기까지는 컨택스트 스위칭에 대한 오버헤드를 견딜만 하다고 판단하는 것이다. nr_running 이 sched_nr_latency 보다 커지면, 스케줄링 주기가 보장되지 않는다. 결국, default scheduling delay 를 더 늘려야 한다(nr_running * sysctl_sched_min_granularity).
// kernel/sched/fair.c - v6.5 /* * The idea is to set a period in which each task runs once. * * When there are too many tasks (sched_nr_latency) we have to stretch * this period because otherwise the slices get too small. * * p = (nr <= nl) ? l : l*nr/nl */ static u64 __sched_period(unsigned long nr_running) { if (unlikely(nr_running > sched_nr_latency)) return nr_running * sysctl_sched_min_granularity; else return sysctl_sched_latency; }- Virtual time
" CFS 는 완전히 공평한 스케줄링을 목적으로 만들어진 알고리즘이다. 어떻게 하면, `완전히` 공평한 스케줄링을 할 수 있을까? 예를 들어, CPU 가 1개 인데, 실행 가능한 태스크가 2개 라고 치자. 이 때, 가장 심플한 스케줄링 방법은 각 태스크에게 10초를 할당하면 공평하다고 말할 수 있을 것 같다. CFS 에서 특별한 점은 각 태스크의 실행 시간을 누적해서 가지고 있다는 점이다. CFS 는 이 누적된 값을 통해서 각 태스크에게 공정한 시간을 할당하게 된다.
" 예를 들어, 스케줄링 주기가 6ms 이고 동일한 우선 순위를 갖는 태스크 A, B 가 있을 때, 각 태스크는 3ms 씩 CPU 를 점유할 수 있다. 그런데 만약에 여기에 weight 이 적용되면 어떻게 될까? 태스크 A, B 의 weight 이 각각 1024, 820 일 경우(nice 값으로 환산하면 0, 1), 태스크 A, B 의 time slice 는 다음과 같다.
1. 6 * 1024 / (1024 + 820) = 3.3ms => CPU usage : (3.3 / 6) * 100% = 55%
2. 6 * 820 / (1024 + 820) = 2.7ms => CPU usage : (2.7 / 6) * 100% = 45%" `Priority of ordinary process` 섹션에서 우리가 nice 를 공부할 때, nice 값이 1 감소하면, CPU usage 가 10% 증가한다고 했다. 그래서, nice 값이 0 인 태스크 A 의 CPU usage 는 55%, 태스크 B 의 CPU usage 는 45% 를 나타낸다. 즉, nice 값에 감소에 따라 time slice 가 10% 증가한것을 볼 수 있다. 그렇다면, CFS 가 말하는 `완전히` 공평한 스케줄링이라는 것이 어떤 의미일까? 위에 내용만 보면 결과적으로 2개의 태스크의 time slice 가 서로 다르다. CFS 는 여기서 `virtual time` 이라는 개념을 도입한다. virtual time 을 놓고보면 위에 2.7ms 와 3.3ms 는 동일한 값이다. 대신 앞에 값들은 virtual time 으로 변환해줘야 한다.

" 태스크 A 의 virtual time 을 계산해보면, `3.3 * (1024 / 1024) = 3.3ms` 인것을 알 수 있다. 이걸 통해 알 수 있는 점은 nice 값이 0 인 경우, actual time 과 virtual time 이 동일하다는 것이다. 태스크 B 의 virtual time 은 `2.7 * (1024 / 820) = 3.3ms` 이다. 태스크 A, B 가 weight 이 서로 달랐지만, 결과적으로 virtual time 이 동일하다는 것을 확인했다. 즉, CFS 는 각 태스크에게 공정한 actual time 이 아닌, 공정한 virtual time 을 보장하는 것이다. 그렇다면, next running task 를 선택할 때, 어떤 태스크를 선택할까? efwefewerg 왜 ? ㄷㄹㄷㄱ허932ㅓ 이해가 안가네 virtual time 이 가장 적은 태스크를 선택하기만 하면 된다. ewf
" 그런데, 위와 같이 나눗셈 연산은 소수를 만들뿐만 아니라, 연산 속도도 좋지 못하다. 그래서, CFS 는 clock source & clock event 에서 봤던 방식과 동일한 방식으로 vritual time 을 구한다. 즉, 먼저 값을 확장해서 소수점이 정수 자리로 오게 만든다(왼쪽 쉬프트). 그리고, 계산을 진행한다. 이후에 다시 원복한다(오른쪽 쉬프트). 그런데, 동적으로 변하는 값과 정적인 값들을 구분해야 한다.
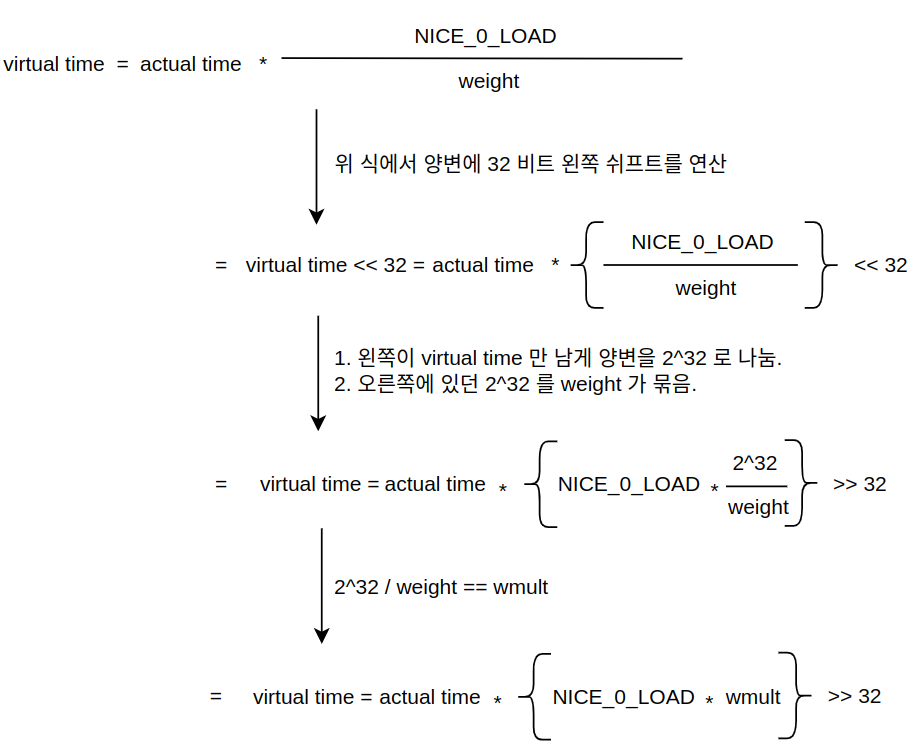
" weight 값은 이미 sched_prio_to_weight 배열을 통해서 정적으로 정해져있다. 그렇다면, wmult 또한 동적으로가 아닌, 정적으로 미리 값을 계산해놓을 수 있다.
// kernel/sched/core.c - v6.5 /* * Inverse (2^32/x) values of the sched_prio_to_weight[] array, precalculated. * * In cases where the weight does not change often, we can use the * precalculated inverse to speed up arithmetics by turning divisions * into multiplications: */ const u32 sched_prio_to_wmult[40] = { /* -20 */ 48388, 59856, 76040, 92818, 118348, /* -15 */ 147320, 184698, 229616, 287308, 360437, /* -10 */ 449829, 563644, 704093, 875809, 1099582, /* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326, /* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587, /* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126, /* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717, /* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153, };" sched_prio_to_wmult 배열은 아래의 공식으로 구할 수 있다.
- sched_prio_to_wmult[i] = 2^32 / sched_prio_to_weight[i]
" 프로세스의 weight 정보만 별도로 관리하는 구조체가 있다. `struct load_weight` 구조체는 각태스크의 weight & inv_weight 데이터를 가지고 있다.
// kernel/sched/sched.h - v6.5 struct load_weight { unsigned long weight; u32 inv_weight; };" 그렇다면, actual time 을 virtual time 으로 바꾸는 함수는 어떤 함수일까?
// kernel/sched/fair.c - v6.5 /* * delta_exec * weight / lw.weight * OR * (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT * * Either weight := NICE_0_LOAD and lw \e sched_prio_to_wmult[], in which case * we're guaranteed shift stays positive because inv_weight is guaranteed to * fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22. * * Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus * weight/lw.weight <= 1, and therefore our shift will also be positive. */ static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw) { u64 fact = scale_load_down(weight); u32 fact_hi = (u32)(fact >> 32); int shift = WMULT_SHIFT; int fs; __update_inv_weight(lw); if (unlikely(fact_hi)) { fs = fls(fact_hi); shift -= fs; fact >>= fs; } fact = mul_u32_u32(fact, lw->inv_weight); fact_hi = (u32)(fact >> 32); if (fact_hi) { fs = fls(fact_hi); shift -= fs; fact >>= fs; } return mul_u64_u32_shr(delta_exec, fact, shift); }" 리눅스 커널은 각 프로세스를 `struct task_struct` 로 표현한다. 그렇다면, 프로세스 스케줄링에서 스케줄링 단위는 상식적으로 프로세스여야 한다. 그런데, task grouping 메커니즘이 등장하면서, 다수의 태스크를 하나의 그룹으로 묶을 수 있게 되었다. 이제 스케줄러는 프로세스 뿐만이 아니라, 프로세스 그룹까지도 스케줄링 대상으로 설정해야 했다. 결국, 프로세스와 프로세스 그룹을 추상화시킬 수 있는 새로운 구조체가 필요했다. 그게 바로 `struct sched_entity` 구조체다.
// kernel/sched/sched.h - v6.5 struct sched_entity { struct load_weight load; struct rb_node run_node; unsigned int on_rq; .... u64 sum_exec_runtime; u64 vruntime; .... };- load : 스케줄러 엔터티의 weight & inv_weight 관련 정보를 저장하고 있다.
- rb_node : 이 필드를 통해 런큐에 연결된다.
- on_rq : 스케줄러 엔터티가 런큐에 enqueue 되면, 이 값이 1 이 된다. 그리고, dequeue 되면, 이 값은 0 이 된다.
- sum_exec_runtime : 스케줄러 엔터티가 실행된 total actual time.
- vruntime : 스케줄러 엔터티가 실행된 total virtume time.- Why does CFS use rb-tree ? [참고1 참고2]
" 자료 구조를 선택할 때는 `메모리 연속성` 에 대해 고려해봐야 한다. 예를 들어, 1,000,000,000 개의 데이터를 저장해야 하는데, array 를 사용할 때와, linked list 를 사용할 때 차이가 뭘까? 참고로, 모두가 아는 사이즈의 차이를 얘기하는게 아니다.
- array 는 contiguous memory 를 기반으로 하지만, linked list 는 non-contiguous memory 를 기반으로 한다.
" 만약, array 가 int 타입이라면, 4 * 1,000,000,000 는 2^31 보다 큰 값이다. 메모리가 8GB 라고 가정할 때, 저렇게 큰 사이즈를 RAM 에 연속적인 영역에 할당이 가능할까? 쉽지 않다. 그러나, 연속적이지 않고, 4 * 1,000,000,000 가 4KB 단위로 여러 곳에서 흩어져 있으면 어떨까? 연속적으로 할당받는 것보다 부담이 훨씬 덜 할 것이다(물론, 외부 단편화가 발생할 우려가 상당히 높다).
" 본론으로, 돌아와서 왜 CFS 는 rb-tree 를 사용할까? 먼저, min-heap 과 한 번 비교해보자. min-heap 같은 경우 O(1) 시간 복잡도를 갖는다고 하는데, 왜 min-heap 을 쓰지 않을까? 리눅스에서 min-heap 이 배열로 구현되어 있기 때문이다. 즉, 연속적인 메모리 할당을 기반으로 동작하는 알고리즘이다. CFS 는 process scheduling 알고리즘이다. process scheduling 알고리즘은 기본적으로 어마 무시한 processes 및 threads 를 관리할 수 있다는 것을 가정해야 한다. 즉, 굉장히 많은 `struct sched_entity` 를 관리해야 한다는 것이다. 많은 양의 processes 및 threads 를 연속적인 메모리에 할당하는 것은 쉽지 않다.
" 그렇다면, operations 들의 performance 면에서는 어떨까? thread 가 runnable 에서 blocked 상태로 전환될 경우, runqueue 에서 제거되어야 한다. 이 때, 시간 복잡도는 다음과 같다(remove 연산에서도 rb-tree 가 성능이 더 좋음을 알 수 있다).
- rb-tree : O(log(n))
- heap : O(n)" 물론, querying(look-up) 연산은 heap 이 O(1) 이기 때문에 더 좋지만, 스레드를 제거해야 하는 경우도 있고(O(log(n))), vruntime 을 업데이트 해야하는 경우(O(log(n)))도 있기 때문에, 다양한 use cases 들을 고려해서 rb-tree 를 사용하는 것이다.
" 그렇다면, 같은 계열의 balanced tree 인 AVL 은 어떨까? 2 개의 트리는 여러 가지 측면에서 거의 유사하다. 그러나, operation 에서 차이가 발생한다. AVL 은 look-up 쪽에서 퍼포먼스가 더 앞서지만, rb-tree 는 insert 와 remove 쪽에서 더 앞선다고 한다. 거기다가, 2개의 tree 모두 balance 를 유지하기 위한 extra memory 가 사용하는데, 이 사이즈가 rb-tree 가 더 작다.
- Runqueue
" 런큐는 `struct rq` 구조체를 통해 표현되며, Per-CPU 타입으로 선언되어 있다. 즉, CPU 마다 런큐를 가지고 있다. 각 스케줄링 클래스 또한 자신의 런큐를 가지고 있다. 예를 들어, `struct cfs_rq` 구조체는 CFS 스케줄링 클래스 런큐를 나타낸다. `struct rt_rq` 구조체는 리얼 타임 런큐를 나타낸다. `struct dl_rq` 구조체는 데드라인 런큐를 나타낸다.
struct rq { .... struct cfs_rq cfs; struct rt_rq rt; struct dl_rq dl; .... };// include/linux/rbtree_types.h - v6.5 /* * Leftmost-cached rbtrees. * * We do not cache the rightmost node based on footprint * size vs number of potential users that could benefit * from O(1) rb_last(). Just not worth it, users that want * this feature can always implement the logic explicitly. * Furthermore, users that want to cache both pointers may * find it a bit asymmetric, but that's ok. */ struct rb_root_cached { struct rb_root rb_root; struct rb_node *rb_leftmost; };" `struct cfs_rq` 구조체는 말 그대로 `CFS runqueue` 를 의미한다. CFS 런큐는 빠른 검색 속도를 위해서 `struct rb_root_cached` 구조체를 사용한다. 이 구조체는 루트 노드와 가장 왼쪽 노드를 참조함으로써, CFS 가 즉각적으로 다음 프로세스를 선택할 수 있게 해준다.
// kernel/sched/sched.h - v6.5 /* CFS-related fields in a runqueue */ struct cfs_rq { struct load_weight load; unsigned int nr_running; .... u64 min_vruntime; .... struct rb_root_cached tasks_timeline; .... };- load : 런큐에 들어있는 모든 스케줄링 엔터티 weight 의 총합
- nr_running : 런큐에 들어있는 스케줄링 엔터티 개수
- min_vruntime : 런큐에 들어있는 스케줄링 엔터티중에서 가장 적은 virtual time
- tasks_timeline : virtual time" CFS 는 virtual time 을 기준으로 red-black tree 를 정렬한다. 즉, 런큐(rb-tree)에 삽입되어 있는 모든 runnable task 들은 자신의 virtual time 을 기준으로 정렬되어 있다고 보면된다. 왼쪽으로 갈 수록 virtual time 이 작아지고, 오른쪽으로 갈 수록 커진다. CFS 의 재미있는 특징은 시간이 흐를수록, 왼쪽에 있던 프로세스는 점점 오른쪽으로 이동하고, 오른쪽에 위치해 있던 프로세스는 천천히 왼쪽으로 이동한다는 것이다. CFS 는 가장 왼쪽에 있는 프로세스를 다음 실행할 프로세스로 선택하기 때문에, 런큐에 있는 모든 프로세스는 언젠가는 반드시 최소 한 번은 CPU 를 점유하게 된다는 것을 의미한다(왜냐면, 초기에는 오른쪽에 있었는데 시간이 지날수 록, 점점 왼쪽으로 이동할 것이기 때문이다).

" 이 글을 정리하자. 리눅스의 모든 프로세스는 struct task_struct 구조체로 표현할 수 있다. 그러나, 각 스케줄링 클래스는 직접적으로 struct task_struct 를 스케줄링 하지 않는다. 대신에, struct sched_entity 를 스케줄링한다.

'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Performance - CPU optimization basic (0) 2023.11.06 [리눅스 커널] cache - basic (1) 2023.11.04 [리눅스 커널] Interrupt - Tasklet (0) 2023.10.28 [리눅스 커널] Synchronization - Per-CPU Overview (0) 2023.10.18 [리눅스 커널] Interrupt - Softirq (0) 2023.10.18