-
[리눅스 커널] Performance - CPU optimization basicLinux/kernel 2023. 11. 6. 01:18
글의 참고
- https://www.redhat.com/sysadmin/tune-linux-tips
- https://zhuanlan.zhihu.com/p/98556131
- https://manpages.ubuntu.com/manpages/impish/man1/lstopo.1.html
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
: 이 글은 몇 가지 주제를 선정해서 리눅스 기반의 server-side 에서 어떻게 CPU 퍼포먼스를 최적화 하는지에 대해 알아본다.
1. Timer
2. Interrupt
3. Process- Types of system topology [참고1]
: 현대의 시스템 아키텍처는 멀티 프로세서를 기반으로 한다. 일반적으로 사용되는 멀티 프로세서 아키텍처 2가지로 나뉜다.
1. Symmetric Multi-Processor (SMP) topology
" SMP 토폴로지는 모든 CPU`s 가 동일 시점에 메모리에 접근할 수 있는 있다는 것이 핵심이다. 반대로, 메모리를 모든 CPU`s 가 공유하다보니 `serialized memory accesses` 를 강제된다. 즉, 동일 주소를 갖는 메모리 주소에 접근할 때, CPU 는 순서대로 접근해야 한다. 이러한 이유로 대부분의 서버 시장에서는 NUMA 구조를 채택하고 있다.
2. Non-Uniform Memory Access (NUMA) topology
" 일반적으로, 멀티 프로세서 구조에서 NUMA 를 이용하면, SMP 보다 더 좋은 퍼포먼스를 낼 수 있다. NUMA 는 다수의 프로세서를 물리적으로 하나의 socket 이라는 독립된 공간안에 묶는다. 즉, 그룹핑하는 것이다. 이 NUMA 에서는 socket 을 node 라고 부른다. node 안에는 로컬 메모리가 존재하는데, 동일 node 안에 존재하는 프로세서들은 로컬 메모리에 액세스해야 퍼포먼스가 좋아진다. 즉, remote memory 액세스를 최소화하고, local memory 액세스를 최대화하는 것이 NUMA 를 이용한 퍼포먼스 최적화다.: SMP 와 NUMA 아키텍처의 차이는 다음과 같다.
SMP NUMA 

: 실습에 필요한 몇 가지 툴을 설치해야 한다(based on Ubuntu 18.04).
1. sudo apt install numactl
2. sudo apt install hwloc # for `lstopo`
3. Install `perf`
- sudo apt install linux-tools-common
- sudo apt install linux-tools-5.4.0-150-generic: 현재 시스템 토폴로지를 한 번 확인해보자.
# numactl --hardware available: 1 nodes (0) node 0 cpus: 0 1 2 3 4 5 6 7 node 0 size: 7868 MB node 0 free: 363 MB node distances: node 0 0: 10: 프로세서 아키텍처에 대한 정보를 가져오려면 `lscpu` 명령어를 사용해볼 수 있다. 여기에 CPUs, threads, cores, sockets 그리고 NUMA nodes 에 대한 정보를 출력한다.
# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 158 Model name: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz Stepping: 9 CPU MHz: 1514.948 CPU max MHz: 3800.0000 CPU min MHz: 800.0000 BogoMIPS: 5599.85 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 6144K NUMA node0 CPU(s): 0-7 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities: 현재 시스템의 NUMA 아키텍처 정보를 보고싶다면, `lstopo` 명령어를 사용해볼 수 있다. 그리고, 이 툴은 그래픽한 환경을 제공한다. `lstopo` 의 결과는 아래와 같다.
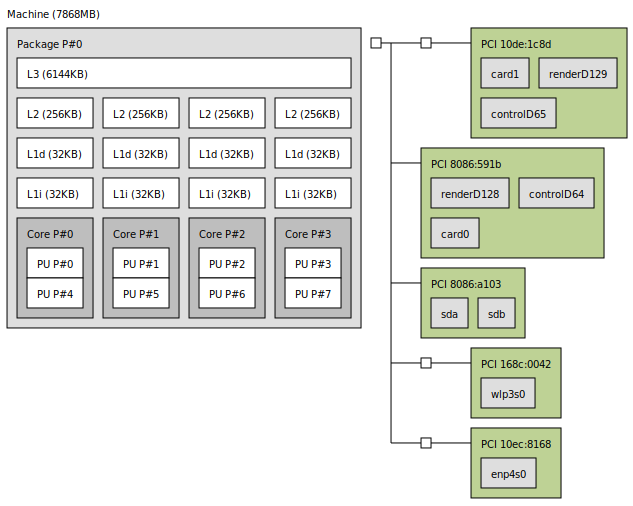
: `PU P#` 는 thread 를 의미한다. 즉, hyper-threaded 를 나타낸다. 결국, 위에 다이어그램은 4 cores, 2 threads 를 나타낸다(물리적으로는 4개의 cores 만 존재한다)
1. L#i : instruction cache 를 의미한다.
2. L#d : data cache 를 의미한다.
3. L1 : level 1 cache 를 의미한다.
4. L2 : level 2 cache 를 의미한다.
5. L3 : level 3 cache 를 의미한다.: 그런데, 위에 구조는 NUMA 일까? 아쉽게도 NUMA 가 아니다. 그냥 일반적인 SMP 구조다. 어떻게 알 수 있을까? `numactl --hardware` 명령어를 입력해보면 알 수 있다. 시스템 아키텍처가 물리적으로 NUMA 구조를 지원한다면, node 가 여러 개여야 한다. 1개만 있다면, NUMA 구조가 아니다[참고1]
NUMA enabled NUMA disabled # numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 8157 MB
node 0 free: 88 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 8191 MB
node 1 free: 5176 MB
node distances:
node 0 1
0: 10 20
1: 20 10available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11
node 0 size: 65525 MB
node 0 free: 17419 MB
node distances:
node 0
0: 10: 그리고, `lstopo` 명령어로도 알 수 있다. NUMA 를 지원하다면, 아래와 같이 `Socket` 이라고 표현되야 하지만, 지원하지 않는다면, 일반적으로 `Package` 라고 명시된다.

- Configuring kernel tick time
: 현대의 리눅스 커널은 대부분 tickless kernel 로 동작한다. tickless 는 원래 power saving 을 위해 등장한 메커니즘이다. CPU 가 idle 상태가 되면 주기적인 타이머를 종료해서 전력 소비를 줄이는 것이다. CPU 가 주기적으로 wake-up 을 할 필요가 없으므로, deep-sleep 을 이전보다 더 쉽고, 더 오래 진입할 수 있게 되면서 전력 소비를 줄이게 되는 원리다. 그런데, 리눅스에서 tickless 는 2가지 종류가 있다.
1. tickless(dynamic tick)
2. full-tickless: 이 글에서 `full-tickless` 를 사용해서 어떻게 CPU 퍼포먼스가 증가하는지에 대해 알아볼 것이다.
1. Procedure
1. 특정 코어에서 dynamic tickless 를 활성화 시키려면, `nohz_full` 커널 파라미터에 CPU 번호를 입력해야 한다. 16 코어에서 0 번을 제외한 1 ~ 15번 코어에서 dynamic tickless 를 활성화 하려면, 아래와 같이 입력한다. 참고로, grubby 명령어는 x86 진영에서 사용되는 부트 로더들에게 적용되는 명령어다.
위 명령어가 실행되면, 모든 timekeeping 작업들은 0 번 코어가 전담하게 된다. 첨언을 하자면, `nohz_full` 은 엄밀히 말해서 tickless 중에서도 `full-tickless` 라고 하는 포퍼먼스에 최적화된 메커니즘이다. 한 개의 CPU 만 timekeeping 을 관리하고, 나머지 CPU 는 1 초에 최소 한 번의 tick 만을 받는다. 그리고, adaptive-ticks CPU`s 들은 runnable process 가 하나만 존재할 경우, timer tick 을 disable 할 수 있다. 즉, 프로세스 스케줄링을 하지 않는다고 볼 수 있다. 선점되지 않기 때문에 하나의 작업을 굉장히 빨리 처리할 수 가 있다. 그래서, 이 메커니즘은 real-time application 및 HPC 와 어울린다.# grubby --update-kernel=ALL --args="nohz_full=1-15"
By default, no CPU will be an adaptive-ticks CPU. The "nohz_full=" boot parameter specifies the adaptive-ticks CPUs. For example, "nohz_full=1,6-8" says that CPUs 1, 6, 7, and 8 are to be adaptive-ticks CPUs. Note that you are prohibited from marking all of the CPUs as adaptive-tick CPUs: At least one non-adaptive-tick CPU must remain online to handle timekeeping tasks in order to ensure that system calls like gettimeofday() returns accurate values on adaptive-tick CPUs. (This is not an issue for CONFIG_NO_HZ_IDLE=y because there are no running user processes to observe slight drifts in clock rate.) Therefore, the boot CPU is prohibited from entering adaptive-ticks mode. Specifying a "nohz_full=" mask that includes the boot CPU will result in a boot-time error message, and the boot CPU will be removed from the mask. Note that this means that your system must have at least two CPUs in order for CONFIG_NO_HZ_FULL=y to do anything for you.
- 참고 : https://www.kernel.org/doc/Documentation/timers/NO_HZ.txt
2. 시스템 부트-업 시점에, 수동으로 `rcu` 스레드를 non-latency sensitive core 인 CPU[0] 에 이동시켜야 한다.
왜 rcu 스레드를 CPU[0] 에 옮길까? 다른 CPU 에서 tick 이 disable 되기 때문이다. RCU grace period 및 quiescent state 를 파악하기 위해서는 timer 가 필요하다. 그런데, CPU[0] 만 타이머가 동작하니, RCU 관련 작업을 모두 CPU[0] 에 옮기는 것이다.# for i in `pgrep rcu[^c]` ; do taskset -pc 0 $i ; done 2. Verification steps
1. 시스템이 reboot 되면, dynticks 이 활성화 되었는지 체크한다.
만약, dynatick tickless 가 설정되지 않을 경우, journalctl -xe | grep dynticks 명령어를 입력했을 때, 아무것도 출력되지 않는다.# journalctl -xe | grep dynticks
Mar 15 18:34:54 rhel-server kernel: NO_HZ: Full dynticks CPUs: 1-15.
" full-tickless 가 정상적으로 동작하는지 확인하기 위해서 아래 명령어를 입력한다. 이 명령어는 CPU[1] 이 3초 동안 sleep 일 때, 몇 번의 tick 이 발생하는지를 측정한다.
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 sleep 3
" defailt kernel timer 설정을 사용하면, 대략 3107 번의 ticks 이 발생한 것을 확인할 수 있다.
" full-tickless 설정으로 변경하고 결과를 확인하면 4번만 tick 이 발생한 것을 알 수 있다. full-tickless 도 1초에 최소 한 번은 tick 이 발생하기 때문에, 3초 동안 4번 정도의 tick 이 발생한 것을 알 수 있다.# perf stat -C 0 -e irq_vectors:local_timer_entry taskset -c 0 sleep 3
Performance counter stats for 'CPU(s) 0':
3,107 irq_vectors:local_timer_entry
3.001342790 seconds time elapsed
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 sleep 3
Performance counter stats for 'CPU(s) 1':
4 irq_vectors:local_timer_entry
3.001544078 seconds time elapsed- Overview of an interrupt request [참고1 참고2 참고3 참고4 참고5 참고6 참고7]
" 인터럽트는 현재 실행중 인 프로그램을 일시 중지 시키기 때문에, high interrupt rate 는 시스템 퍼포먼스에 큰 영향을 줄 수 있다. 인터럽트를 처리하는 데 소요되는 시간을 줄일 수 있는 몇 가지 방법이 있다.
1. interrupt affinity
2. by sending a number of lower priority interrupts in a batch (coalescing a number of interrupts)" interrupt requests 는 `smp_affinity` 라는 속성을 가지고 있다. 이 속성은 해당 인터럽트를 어떤 프로세서에서 처리해야 될 지를 결정한다. 애플리케이션 퍼포먼스를 향상을 위해서는 interrupt affinity 를 설정하고, 특정 코어에서만 처리하도록 해야 한다. 이러한방식은 cache
" `/proc/interrupts` 파일은 IRQ 번호, 각 코어에서 처리된 인터럽트, 인터럽트 타입, 인터럽트를 처리할 핸들러 이름이 출력한다. interrupt requests 는 `smp_affinity` 라는 속성을 가지고 있다. 이 속성은 interrupt affinity 와 application`s thread affinity 를 특정 CPU`s 들에게 할당함으로써 applicaton performance 를 높일 수 있다. 성능이 올라가는 이유는 특정 interrupt 와 application thread 가 cache line 을 공유하도록 만들기 때문이다.
" 각 interrupt affinity 는 `/proc/irq/${IRQ_NUMBER}/smp_affinity` 파일에 저장되어있다. 이 값은 root user 를 통해서만 변경이 가능하다. 예를 들어, AHCI 드라이버의 interrupt affinity 를 설정하기 위해서는 먼저 AHCH 드라이버가 사용하는 IRQ number 를 알아야 한다.
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 127: 12022 0 0 1563938 0 0 0 0 IR-PCI-MSI 376832-edge ahci[0000:00:17.0]" 이제 127번에 대응하는 smp_affinity 파일을 찾는다. smp_affinity 값은 16진수 값이고, 각 비트는 CPU 에 대응한다. 즉, AHCI 는 이미 CPU[3] 번에 interrupt affinity 를 갖고 있는 것이다. 만약, smp_affinity 가 0xff 라면 IRQ 는 모든 프로세서에서 서비스 될 수 있다는 것을 의미한다.
$ cat smp_affinity 08" 여기서 주의할 점이 있다. `/proc/irq/${IRQ_NUMBER}/smp_affinity_list` 파일에 명시된 CPU 로만 interrupt affinity 를 설정할 수 있다. 아래에서 볼 수 있다시피, IRQ 127 번은 CPU[3] 에게만 affinity 할 수 있다. 즉 다른 코어로는 변경이 불가능하다. 이게 하드웨어적으로 불가능한 케이스들이 존재한다.
$ cat smp_affinity_list 3" smp_affinity 를 출력했을 때, 아래와 같이 나오는 경우가 있다. 이건 뭘까? `,` 는 CPU 개수를 32개 단위로 나눈것을 의미한다. 즉, 아래 코드는 총 64개의 CPU 가 존재하며, IRQ 40 은 모든 코어에서 서비스가 될 수 있다는 것을 의미한다.
$ cat /proc/irq/40/smp_affinity ffffffff,ffffffff" 그러나, process affinity 와 달리 interrupt affinity 는 `득` 보다는 `실` 이 많을 수 있다. 일반적으로, 인터럽트 핸들러가 사용하는 메모리 양이 상당히 적기 때문에, 특정 CPU 에 affine 시킨다고해서 큰 cache hit rate 가 일어나지는 않는다. 인터럽트 핸들러가 메모리를 적게 사용한다는 것을 어떻게 알 수 있을까? 아키텍처에 의존적인 부분이긴 하지만, 대개의 인터럽트 핸들링 절차는 이전 커널 프로세스의 스택을 공유하게 된다. 인터럽트가 발생하면, 인터럽트 핸들러는 선점당한 커널 스레드의 스택을 공유해서 인터럽트를 처리한다. 이렇게 하는 이유는 일반적으로 인터럽트 핸들링 절차가 메모리를 많이 사용하지 않기 때문에, stackoverflow 를 걱정하지 않아도 되기 때문이다. 물론, interrupt nesting 이 발생하면 문제가 될 수 있지만, 리눅스에서는 이 부분을 허용하지 않는다.
" 그렇다면, interrupt affinity 는 다수의 인터럽트를 하나의 코어에 affine 시키고, 나머지 코어들은 자유롭게 해주면 어떨까? 인터럽트를 핸들링하는 코어가 그렇지 않은 다른 코어들에 비해 굉장히 busy 하다는 것을 가정하면, 가끔 인터럽트 핸들링 코어에서 bottle neck 현상이 발생하는 것을 알 수 있을것이다. 왜냐면, 모든 인터럽트를 자신이 처리하는데, 거기에 프로세스까지 할당되니 로드가 너무 몰리는 것이다.
" 모든 인터럽트 핸들링을 CPU[0] 이 할 때, 이 문제는 더욱 심각해진다. 왜냐면, 기존 single-core 때부터 CPU[0] 에게 여러 가지 일을 몰빵하는 경향이 있기 때문이다. 거기에 인터럽트 처리까지 맡게 될 경우, 병목 현상은 불가피하다. 그렇다면, interrupt affinity 가 좋다는 건가 나쁘다는 건가? 일반적인 경우에는 적절하게 분배를 하는 것으로 판단된다. 그러나, interrupt affinity 도 cache hit rate 를 높이기 위해서 하는 것이기 때문에, 인터럽트가 반복적으로 발생하는 케이스에서는 특정 CPU 에게 특정 인터럽트를 affine 시켜볼 수 있다. 예를 들어, NIC interrupt 같은 경우는 `짧은 시점 & 상당히 빈번하게` 발생하기 때문에 해당 인터럽트를 특정 CPU 에 affine 할 경우, cache hit rate 가 상당히 높아지기 때문에 좋은 퍼포먼스를 나올 수 있다.
- process optimization
" 리눅스에는 더 많은 CPU 를 확보해서 애플리케이션이 더 좋은 퍼포먼스 및 효율적으로 동작할 수 있도록 하는 많은 방법들이 존재한다.
1. `nice & renice` 커맨드를 통해서 priority 를 튜닝한다.
2. 애플리케이션을 한 개 혹은 여러 CPU 에게 바인딩한다. 이 방식은 `CPU pinning` 혹은 `CPU affinity` 라고도 한다." 두 번째 방법을 통해서 특정 스레드 & 프로세스 & 애플리케이션을 특정 CPU`s 들에서만 동작하도록 제한함으로써, 더 많은 `cache warmth` , `cache hits` 을 일으킬 수 있다. 결과적으로, 전반적인 퍼포먼스가 증가할 수 있게된다. CPU affinity 를 통해 얻을 수 있는 이점을 정리하면 다음과 같다.
1. cache performance 최적화
2. (동일 시점이 아니라는 가정하에서) 다수의 스레드가 동일 데이터에 액세스할 때, 이들 모두를 동일 프로세서에서 실행한다면 cache miss 를 최소화할 수 있다.1. priority tuning
" application performance 의 CPU usage 를 증가시키는 가장 간단한 방법은 `nice` 커맨드를 통해 프로세스의 우선 순위를 변경하는 것이다. nice 가 양수면 낮은 우선 순위를 나타나며, 음수면 높은 우선 순위를 나타낸다. 그리고, nice 값이 클 수록 우선 순위가 낮아지며, 낮을 수 록 우선 순위가 높아진다. 사실, 이 방식은 오래전부터 있어왔지만 여전히 효율적인 방법이다.
" 그런데, nice 를 통해서 어떻게 퍼포먼스를 최적화 할 수 있을까? 모든 프로세스는 CPU 에서 실행될 때, 특정 시간동안만 동작할 수 있도록 제한된 시간을 할당받는다. 이 할당받는 시간을 `time slice` 라고 한다. 그리고, 실제로 프로세스가 CPU 동작한 전체 시간을 `virtual time` 이라고 한다. 리눅스 커널의 CFS 알고리즘은 모든 프로세스들에게 최대한 동일한 시간을 할당하려고 노력한다. 그래서, 리눅스는 각 프로세스의 virtual time 을 기록하고, 이 값을 기준으로 run-queue 에 있는 모든 프로세스들에게 time-slice 를 할당한다. 예를 들어, A 프로세스가 다른 프로세스들보다 virtual time 이 클 경우, CPU 를 많이 점유했다는 뜻이된다. 그러므로, 다음 스케줄링에서 A 프로세스는 다른 프로세스들 보다 적은 time slice 를 할당받게 된다.
" `renice & nice` 명령어를 통해서 `renice +10 PID` 를 실행하면, 해당 프로세스에게 수동으로 virtual time 을 추가하는 것과 같다(nice 값에 양수가 추가되므로, 우선 순위가 낮아짐). 이 시점부터 커널은 해당 프로세스가 런큐에 있는 다른 프로세스보다 더 많은 virtual time 을 소유했다는 것을 알고 더 적은 time slice 를 할당하게 된다. 결국, 해당 프로세스는 renice 명령어 이후에 CPU 사용 시간을 적게 할당 받게되면서 작업 처리가 늦어지게 된다. 여기서 중요한 점은 nice 가 프로세스 자체의 우선 순위라기 보다는 프로세스가 할당받은 시간의 양을 의미한다는 것을 알 수 있다. 다른 프로세스를 선점하는 것이 아니다. 그리고, 우선 순위가 높다고 빈번히 스케줄링 되는 것도 아니다. CFS 에서 프로세스의 자체 우선 순위는 존재하지 않는다. 우선 순위는 시간의 할당양이 된다.
# pidof gedit 3584 # renice +10 3584 3584 (process ID) old priority 0, new priority 10 # renice -10 3584 renice: failed to set priority for 3584 (process ID): Permission denied # sudo renice -10 3584 [sudo] password for yohda: 3584 (process ID) old priority 10, new priority -10 # renice -0 3584 3584 (process ID) old priority -10, new priority 0 #: 위와는 반대로 `renice -10 PID` 를 실행하면, 해당 프로세스에게 수동으로 virtual time 을 빼는것과 같다(nice 값에 음수가 추가되므로, 우선 순위가 높아짐). 이 시점부터 커널은 해당 프로세스가 런큐에 있는 다른 프로세스보다 더 적은 virtual time 을 소유했다는 것을 알고 많은 time slice 를 할당하게 된다. 결국, 해당 프로세스는 renice 명령어 이후에 CPU 사용 시간을 많이 할당 받게되면서 더 빨리 작업이 마무리된다. 그리고, 위에서 볼 수 있다시피 우선 순위를 내리는 작업은 권한이 필요없지만, 우선 순위를 높이려면 권한이 필요하다.
2. process binding (==CPU Affinity, CPU Pinned)
: 사실, 대부분의 경우는 CPU affinity 를 사용하지 않아도 퍼포먼스가 나쁘지 않다. 그런데, 일부 케이스에서는 CPU affinity 를 적용했을 때, 퍼포먼스가 월등히 좋아지는 경우가 있다. 예를 들어, 많은 양의 메모리를 사용하는 프로세스(memory-intensive process) 에게 CPU affinity 를 적용하면, cache hit 을 높여서 전반적인 퍼포먼스가 증가하는 것을 확인할 수 있다.

https://www.redhat.com/sysadmin/tune-linux-tips: 위 그림에서 3개의 애플리케이션(X, Y, Z)들이 6개의 CPU 에서 실행되고 있는 것을 볼 수 있다. default 환경에서 스케줄러는 사용 가능한 모든 CPU 를 사용해서 가능한 빨리 X, Y, Z CPU 에게 할당한다. default 환경에서 색깔이 중구난방으로 퍼져 있는 것을 볼 수 있을 것이다. 이건 CPU 캐쉬에 X, Y, Z 에 대한 정보가 모두 들어있음을 의미한다. 이럴 경우, cache miss rate 가 상당히 높아진다.
: CPU Pinned 환경에서는 특정 애플리케이션은 특정 CPU`s 들에게 고정되어 할당된다. 이럴 경우, 위 그림에서 볼 수 있다시피 cache hit rate 가 높아짐을 알 수 있다. 즉, CPU cache hit rate 를 증가시키기 위해서 특정 스레드를 특정 CPU`s 들에서만 스케줄링 되도록 해야한다. `taskset` 명령어를 사용하면 된다.
# pidof gedit 3992 # taskset -pc 1 3992 pid 3992's current affinity list: 0-7 pid 3992's new affinity list: 1: gedit 의 기존 CPU affinity 가 0-7 인것을 확인할 수 있다. 즉, gedit 은 모든 CPU`s 들에게 스케줄링 되는 것이다. 당연히, CPU cache hit 은 좋을 수 가 없다. `taskset -pc 1 3992` 를 실행하면, CPU[1] 에게만 스케줄링 되도록 한다. 그러나, 이 방법은 영구적이지 않다. 즉, 컴퓨터가 재부팅하거나 프로세스가 죽으면, PID 가 바뀌면서 이전에 설정한 작업들도 모두 무효가 된다. 그렇다면, 영구적으로 적용하고 싶은 경우에는 어떻게 해야 할까? 바로 `drop-in` 파일을 사용하면 된다.
'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Interrupt - IRQ domain (0) 2023.11.07 [리눅스 커널] Kernel command-line parameters (0) 2023.11.06 [리눅스 커널] cache - basic (1) 2023.11.04 [리눅스 커널] Scheduler - Basic (0) 2023.10.30 [리눅스 커널] Interrupt - Tasklet (0) 2023.10.28