-
[리눅스 커널] Synchronization - RCU OverviewLinux/kernel 2023. 10. 16. 03:26
글의 참고
- https://www.kernel.org/doc/Documentation/RCU/Design/Data-Structures/Data-Structures.html
- https://pdos.csail.mit.edu/6.828/2020/readings/rcu-decade-later.pdf
- https://lwn.net/Articles/262464/
- https://en.wikipedia.org/wiki/Read-copy-update
- http://www.wowotech.net/kernel_synchronization/rcu_fundamentals.html
- http://www.wowotech.net/kernel_synchronization/223.html
- https://www.kernel.org/doc/Documentation/RCU/rcu.txt
- https://zhuanlan.zhihu.com/p/113999842
- UnderStanding The Linux Kernel 3rd Edition
- Linux Device Driver 3rd Edtion
- https://docs.kernel.org/RCU/Design/Requirements/Requirements.html
- https://blog.csdn.net/weixin_34249678/article/details/93185669
- https://www.cnblogs.com/LoyenWang/p/12681494.html
- https://zhuanlan.zhihu.com/p/601755628
- http://lastweek.io/notes/linux/linux-rcu/
- https://docs.kernel.org/RCU/index.html#
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" 이 글은 먼저 RCU 가 `왜 필요한가` 에 초점을 맞췄다. 이미 많은 동기화 기법들이 존재하는데, RCU 라는 새로운 동기화 메커니즘이 필요한 이유에 대해서 알아본다. 그리고, RCU 의 기본적인 원칙과 관련 용어에 대해 정리했다.
- Why is there sychronization mechanism like RCU ?
1. performance issue
" spinlock, rwlock, seqlock 모두 shared data 를 기반으로 동작하는 동기화 메커니즘이다. 만약에, 4개의 CPU가 있다고 가정하자. 이 4개의 CPU는 모두 데이터 A 를 공유한다고 치자. CPU[0]이 공유 데이터 A 에 대한 락을 획득했다. 그런데, 앞에 설명한 3개의 동기화 메커니즘은 크리티컬 섹션에 진입할 때, `락`에 값이 수정되면서 `락`이 걸린다(이 `락`은 모든 CPU`s 들에게 공유되는 전역 변수다). 문제는 CPU[1,2,3]의 캐쉬에 `락` 데이터가 들어가 있다면, 데이터 일관성 때문에 추후에 `락`에 접근할 때 , 각 CPU에서 캐쉬 미스가 발생한다는 것이다. RCU 동기화 메커니즘에서 reader 는 lock-free 이기 때문에 위와 같은 퍼포먼스 이슈가 발생하지 않는다. 같은 lock-free 인 seqlock 과의 차이는 뭘까? seqlock 은 read 시에 counter 를 기준으로 값을 다시 read 해야 하는지 판단한다. 그러나, RCU 는 아예 판단하는 코드가 없다. 왜냐면, RCU 는 기존 동기화 메커니즘과 다르게 read 후에 값이 old 인지 new 인지를 알 수 없기 때문이다. 뒤에서 다시 설명한다.
2. reader & writer can execute concurrently
" spin lock 은 `mutually exclusive` 이기 때문에, reader & writer 에 상관없이 크리티컬 섹션에는 딱 하나의 스레드만 진입할 수 있다. rwlock 은 spin lock 보다는 낫다. 다수의 reader`s 가 크리티컬 섹션에 들어가서 공유 데이터를 read 할 수 있다. 그러나, reader & writer 가 동시에 크리티컬 섹션에 진입하는 것은 허용하지 않는다. 즉, 다수의 reader`s 가 크리티컬 섹션에 진입하면, writer 는 밖에서 대기해야 하고, wrtier 가 크리티컬 섹션에 진입하면, 다수의 reader`s 는 밖에서 대기해야 한다. 아래는 rw spin lock 과 RCU 를 비교한 그림이다.
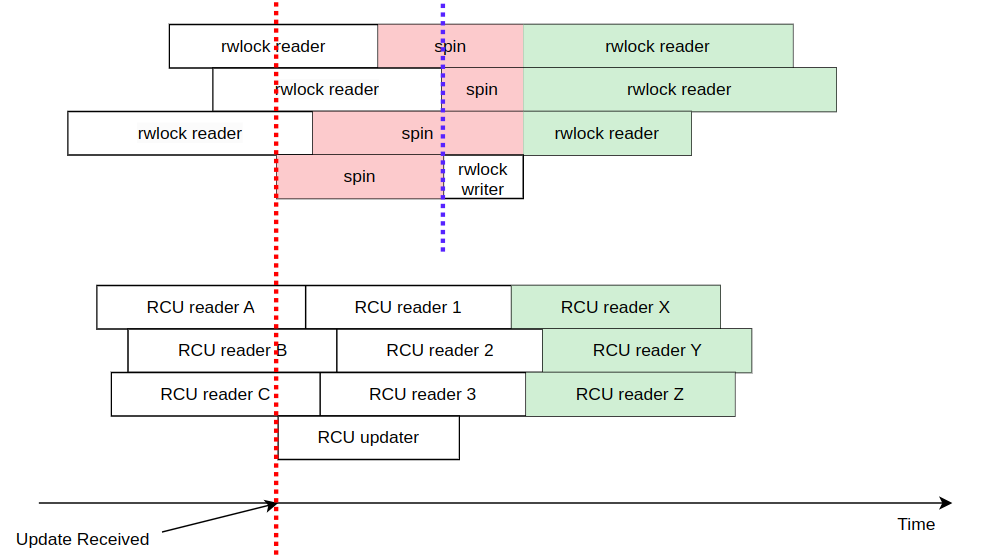
" 3개의 rwlock 이 read 작업을 수행하고 있다. 이 때, 빨간선을 기준으로 rwlock writer 가 크리티컬 섹션에 진입하려고 한다. 그러나, reader`s 들이 있으므로 spin 을 진행한다. 파란선을 기준으로 마지막 rwlock reader 가 크리티컬 섹션에 나오는 시점에 rwlock writer 가 크리티컬 섹션에 진입한다. rwlock wrtier 가 크리티컬 섹션에 있는동안 rwlock reader`s 들은 크리티컬 섹션에 들어갈 수 없다. 이러한 특성 때문에 rwlock 은 `deterministic` 적인 특성을 지닌다. 즉, rwlock writer 를 기준으로 반드시 이전은 old value, 이후는 new value 가 된다는 것이다. 왜냐면, 크리티컬 섹션에 reade & writer 가 같이 작업을 수행하지 못하기 때문이다. 이러한 `deterministic` 적인 특성은 전통적인 동기화 메커니즘의 가장 기본적인 특성이다. 그렇다면, RCU는 어떨까?
" RCU는 크리티컬 섹션에 reader & writer 가 동시에 진입할 수 있다. 당연히, 퍼포먼스 면에서도 RCU가 더 좋다. 그렇다면, 어떻게 크리티컬 섹션에 reader & writer 가 공존할 수 있을까? 위에 그림을 보자. 3개의 RCU reader`s [A, B, C] 들이 크리티컬 섹션에서 데이터를 읽고 있다. 그러다가, 빨간선을 기준으로 RCU writer 가 크리티컬 섹션에 진입한다. 그렇다면, 3개의 RCU reader`s [A, B, C] 들이 크리티컬 섹션에서 빠져나올 때, 어떤 값을 읽게될까? 이 때는 old value 를 읽게된다. 첫 번째 RCU reader 그룹들이 끝나고 두 번째 그룹들이 크리티컬 섹션에 들어왔다. 이 때도 아직 RCU updater 는 여전히 작업중이다. 그렇다면, 3개의 RCU reader`s [1, 2, 3] 들은 어떤 값을 읽게 될까? RCU updater 가 나갔으니, new value 를 읽게될까? 아니다. old value 를 읽게된다. 이걸 통해 알 수 있는 점은 RCU updater 와 같은 시점에 크리티컬 섹션에 있었다면, old value 를 읽게된다는 것을 알 수 있다. 이제 세 번째 그룹이 들어온다. 3개의 RCU reader`s [X, Y, Z] 들은 어떤 값을 읽게될까? 이제는 new value 를 읽게된다.
3. use cases
" spin lock 은 reader & writer 를 구분하지 않는다. 그렇기 때문에, 다수의 reader`s 가 있고, 한명에 writer 가 허용되는 케이스와 같은 `비대칭 구조` 에서는 사용하기 적합하지 않다. 반대도 마찬가지다. 즉, 대칭을 이루는 시스템에서는 사용하기 적합하다. 이런 비대칭 문제는 rwlock 과 seqlock 에서 많이 해소된다. 그러나, seqlock은 다수의 reader`s 가 크리티컬 섹션에 있더라도, writer 가 난입해서 reader 가 읽은 데이터를 무효화 시킬 수 있다. 즉, wrtier 에게 상당히 편향적인 알고리즘이다. rwlock 은 ㄷㅈ롣ㄱ혿겨ㅑ
" spin lock & rwlock 과 같이 여러 동기화 메커니즘이 존재하기 때문에, 상황에 따라서 적합하게 사용하면 될 것처럼 보였지만, 하드웨어의 발전으로 CPU는 점점 더 빨라지는데 반해 메모리 및 스토리지 디바이스의 속도의 발전 속도는 상대적으로 더뎠다. 이러한 속도 차이가 존재하는 상황에서 디스크 드라이버에 액세스 할 때, `shared counter-based lock` 인 spinlock & rw-spinlock 을 사용할 경우 `디스크 대기 시간` 때문에 퍼포먼스 문제가 발생했다. 결국, 멀티 프로세서 아키텍처에서 위와 같은 메커니즘은 더 이상 속도를 퍼포먼스를 충족시켜주지 못한다. 결국, `lock-free` 메커니즘이 필요했고, seqlock 이나 RCU 같은 메커니즘이 등장했다. 그러나, lock-free 가 절대 `은탄환`은 아니다. RCU 가 적용가능한 use case 는 다음과 같다.
1. RCU 메커니즘으로 보호할 수 있는 대상은 오직 `동적 할당` 받은 데이터만 가능하다. 그리고, 이 데이터에 반드시 포인터로 접근할 수 있어야 한다. 왜냐면, RCU 메커니즘이 반드시 앞에 내용을 전제하고 있기 때문이다. 상세 동작은 뒤 섹션에서 다루도록 한다.
2. RCU read-side critical section 에서는 sleep(process context switch) 할 수 없다. 예를 들어, reader 가 rcu_read_lock 함수를 호출하고, process context switch 를 당할 경우, grace period 가 너무 길어지게 된다. 그리고, RCU에서 dead-lock 이 발생하는 유일한 경로는 RCU critical section 내에서 sleep 하는 방법밖에 없다. 예를 들어, synchronize_rcu 함수를 호출한 스레드는 RCU critical section 이 종료되기를 기다리게 된다. 그런데, RCU critical section 내에서 sleep 에 들어 끝나지 않을 경우 계속 기다리게 되므로, dead-lock 이 발생하게 된다. 이외에는 RCU가 dead-lock 을 유도하는 경우는 없다. `rcu_read_lock` 함수의 호출 순서 또한 전혀 고려할 필요가 없다.
3. 주로 write 에서는 퍼포먼스가 고려되지 않지만, 다수의 read 에서 높은 퍼포먼스를 원할 경우에 RCU 가 적합하다.
4. RCU는 mutually exclusive 하지 않기 때문에, read 후에 데이터가 old 일 수도 new 일 수도 있다. 즉, reader 측에서 old 및 new 데이터에 특별히 민감하지 않은 경우에 적합하다.- How does RCU work ?
" RCU 의 핵심적인 동작 메커니즘은 `RCU-protected pointer` 와 `RCU-protected data` 로 나눠볼 수 있다.
1. RCU-protected pointer : RCU-protected data 를 가리키는 포인터를 의미한다.
2. RCU-protected data : RCU-protected pointer 가 가리키는 데이터를 의미한다. 이 데이터는 모든 RCU reader`s 들이 공유한다. 이 데이터는 반드시 동적 할당으로 생성되야 한다.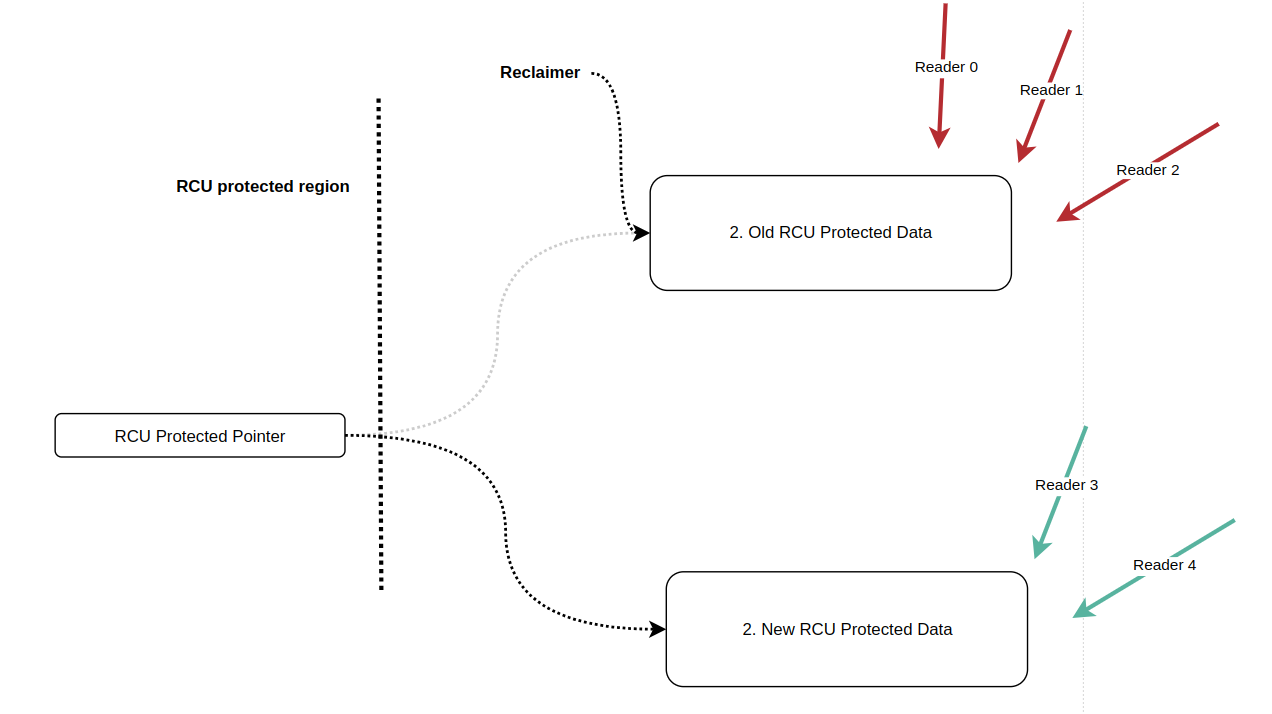
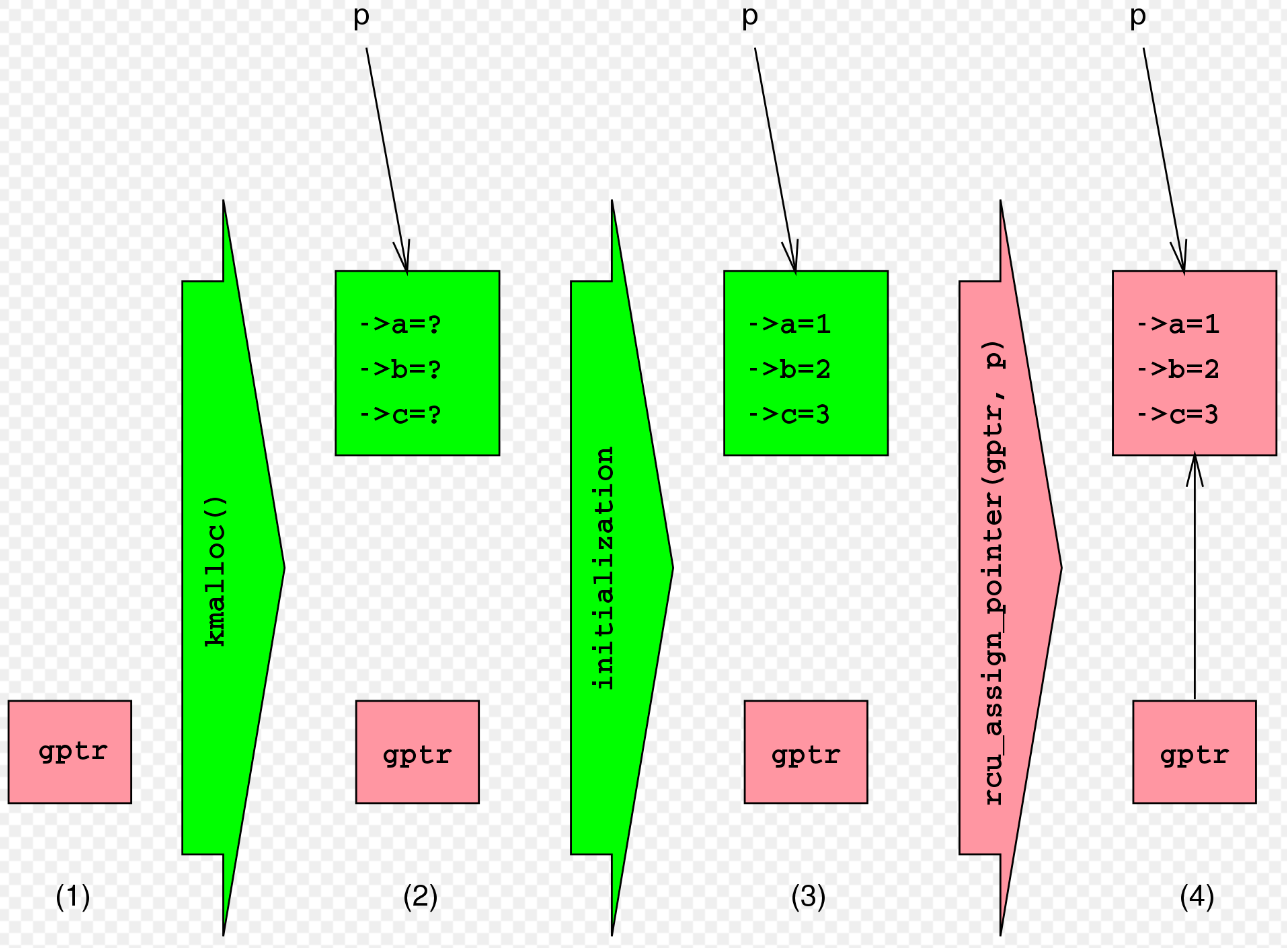
" 그리고, RCU-protected data(shared data) 에 액세스하는 객체로는 data 를 update 하는 `RCU updater` 와 `RCU reader` 가 있다. RCU 또한 seqlock과 비슷하지만, 복사본을 만든다는 점에서 다르다. 예를 들어, seqlock 에서는 reader & writer 가 크리티컬 섹션에 같이 있을 경우에 writer 가 하나뿐인 공유 데이터를 직접적으로 수정해버리니, reader 입장에서는 이전 데이터가 사라져 버린거나 마찬가지다. 그러나, RCU는 reader & writer 가 크리티컬 섹션에 같이 있을 경우에, writer 는 새로운 메모리를 하나 할당받아서, 공유 데이터를 해당 영역에 복사한다. 그렇면, reader 가 바라보는 공유 데이터와 writer 가 바라보고 있는 데이터는 서로 다른 데이터가 된다. RCU 는 위와 같이 데이터 복사를 통해 동기화 문제를 해결한다. 아래 4 단계를 통해서 RCU 동기화 메커니즘에 좀 더 구체적으로 알아보자.
1. updater 는 업데이트에 할 새로운 데이터를 메모리 할당한다.
2. 기존 데이터를 새로운 데이터에 카피한다(i.e memcpy, 즉, 말 그대로 데이터를 카피한다). 이 때, 기존의 데이터를 참조하고 있는 포인터를 어딘가에 저장해둔다(for reclaim).
3. updater 는 복사된 새로운 데이터를 수정한다.
4. 외부로 노출된 전역 포인터에 복사된 새로운 데이터를 참조하도록 한다. 이제부터 RCU reader 가 데이터를 요청할 경우, 새로운 포인터를 읽게 된다." 포인터의 교체는 `atomic operation` 이기 때문에, reader`s 들에게는 반드시 old 혹은 new 중에 하나만 보여지도록 보장한다(포인터로 교체되기 때문에, 교체중인 데이터는 외부로 노출될 수 가 없다). 만약, 포인터를 통해서 exchange 하지 않고, 일일히 데이터를 update 하는 것(i.e memcpy) 이었다면, 다른 동기화 메커니즘(i.e spinlock) 이 필요했을 것이다. 아래 그림은 updater 입장에서 데이터를 새롭게 추가할 때, 순서도를 나타낸다. 그런데, 약간 다를 수 있다. 실제로는 old data 를 new data 에 카피하는 내용도 포함되어야 하지만, 아래 순서도에서는 생략된 것 같다. 녹색은 reader 에서 접근하지 못하는 데이터를 의미하고, 빨간색은 reader 에서도 접근이 가능하다는 것을 의미한다. `p` 는 reader 가 가리키는 포인터를 의미한다.
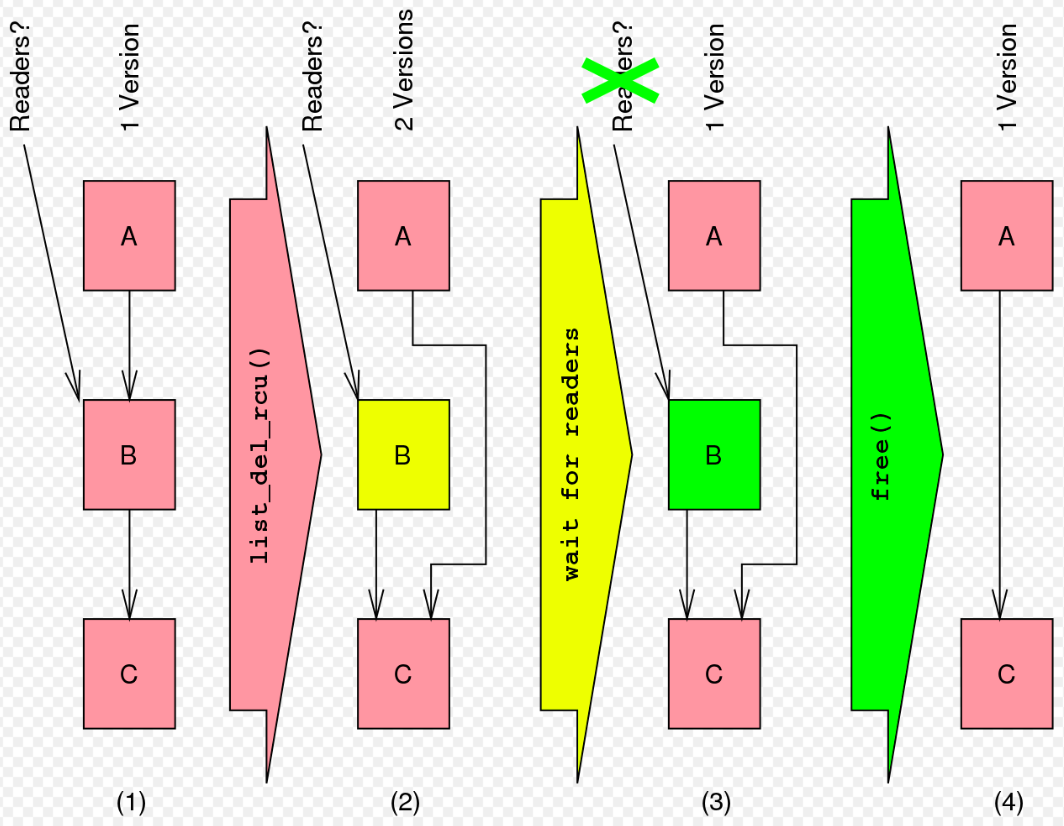
https://en.wikipedia.org/wiki/Read-copy-update#" 이번에는 연결 리스트의 삭제 과정에 대해 알아보자. (1) 단계에서는 리스트에 A,B,C 노드가 들어있다. 빨간색 노드는 RCU reader 에서 액세스가 가능하다는 것을 의미한다. (2) 단계는 `list_del_rcu()` 함수를 통해서 연결 리스트의 B 노드를 제거한것이다. list_del_rcu() 함수를 호출한 시점을 기준으로 RCU reader`s 가 2개로 나뉜다(노란색(B) 노드는 old RCU reader 들에게는 보이고, new RCU reader 들에게는 보이지 않는 것을 의미한다).
1. list_del_rcu() 호출 전 B 노드를 참조하는 RCU reader : 여기에 속하는 RCU reader 들에게는 리스트를 탐색하면, A->B->C 를 모두 탐색할 수 있다.
2. list_del_rcu() 호출 후 B 노드를 참조하는 RCU reader : 여기에 속하는 RCU reader 들에게는 리스트를 탐색하면, B 는 탐색되지 않고, A-> C 를 탐색하게 된다." (3) 단계는 기존 B 노드를 참조하고 있는 RCU reader 들이 release 하기를 기다리는 구간이다(`wait for readers`). 이 때, list_del_rcu() 함수가 호출된 이후에 리스트를 참조하는 RCU reader 들은 기다릴 필요가 없다. 왜냐면, 이 RCU reader 들이 참조하는 리스트에는 B 노드가 없기 때문이다. B 노드가 녹색이 되었다는 것은 old RCU reader 들이 더 이상 B 노드를 참조하고 있지 않다는 것을 의미한다. 그러므로, (4) 단계는 B 노드를 free 하기 안전한 시점이라 볼 수 있다.
https://en.wikipedia.org/wiki/Read-copy-update#- RCU type in linux
" 리눅스 커널에서 RCU는 3가지 종류로 나뉜다.
1. Classic RCU(RCU-sched) : Non-preemptible RCU 를 의미한다. 즉, RCU read-side critical sections 에서 선점되지 않는다.
2. RCU-bh : bh는 `bottom-half` 의 약자로 이 기법은 커널 2.6.9 에서 소개되었다. 기존 RCU-sched 에서는 soft interrupt 가 많이 발생할 경우, 그 만큼 grace period 도 길어지게 된다. RCU-bh 는 이와 같은 케이스에서 성능 향상을 높이기 위해 만들어졌다고 한다.
3. RCU-preempt : real-time RCU 라고 부르며, 커널 2.6.26 에서 소개되었다. RCU-preempt 는 RCU read-side critical sections 에서도 다른 프로세스에게 선점되는 것을 허용한다. 이 기능을 사용하고 싶다면, CONFIG_PREMMPT_RCU 컨피그를 설정하고 컴파일하면 된다." RCU를 나누는 기준은 구현되는 자료 구조로도 나눌 수 있다.
1. TINY RCU : 싱글 프로세서 기반의 아키텍처를 타겟으로 구현되어져 있다. CONFIG_TINY_RCU 컨피그에 의존한다.
2. TREE RCU : 트리 자료 구조를 사용해서 RCU를 구현. 수 십개 이상의 프로세서가 존재하는 큰 시스템에 적용하기 위해 만들어짐. CONFIG_TREE_RCU 컨피그에 의존한다.- RCU interfaces
" RCU interface 는 크게 2 가지 종류로 나눌 수 있다.
1. RCU reader
1. rcu_read_lock : reader 가 사용하는 API 로 RCU-protected data 가 크리티컬 섹션에 있는 동안에는 회수(reclaimed)되지 않기 위해 크리티컬 섹션에 진입하기 전에 사용한다. 즉, 이 API 는 크리티컬 섹션을 지정하는 API 가 아니다. reclaim 을 방지하기 위해 사용된다.
2. rcu_read_unlock : reader 가 사용하는 API 로 reclaimer 에게 RCU read-side critical section 을 종료했음을 알린다. 주의할 점은 RCU read-side critical section 이 nested / overlapping 될 수 있기 때문에 모든 reader 가 끝난뒤에나 reclaim 이 가능하다.
3. rcu_dereference(gp) : reader 가 사용하는 API 로 RCU-protected pointer 를 fetch 한다. fetch 라고 한 이유는 말 그대로 딱 그 시점에서 꺼내오는 것이다. 그래서 이게 old 인지 new 인지 알 수 가 없다.
2. RCU Updater
1. rcu_assign_pointer(gp, p) : updater 가 사용하는 API 로 RCU-protected pointer 가 new value 를 가리키도록 한다.
2. synchronize_rcu : reclaimer 가 사용하는 API 로 old RCU-protected data 를 reclaim 하기 위해서 모든 old
RCU-protected data 에 대한 레퍼런스를 가진 RCU read-side critical section 이 종료될 때 까지, BLOCK 한다. 주의할 점은 synchronize_rcu 함수가 호출된 이후에 생성된 RCU read-side critical section 에 대해서는 고려하지 않는다.
`CPU 1` 에서 synchronize_rcu 에 진입한 시점부터 `CPU 0`의 rcu_read_unlock 함수가 호출되기 만을 기다린다. `CPU 2`의 rcu_read_lock 은 CPU 2 이후에 호출되었기 때문에 고려 대상이 아니다. 그래서, CPU 1 이 synchronize_rcu 를 exit 한 시점이 CPU 0 이 rcu_read_unlock 함수를 호출한 이후인 것을 알 수 있다.
이렇게 rcu_read_unlock 을 기다리는 동안에 BLOCK 을 하는 `동기` 방식 말고도, all ongoing RCU read-side critical sections 들이 완료된 후에 자동으로 콜백 함수가 호출되는 방식 또한 존재한다. 리눅스 커널에서 이 콜백 함수를 `call_rcu` 라고 부른다.
3. call_rcu : 이 함수는 synchronize_rcu() 함수와는 달리 callback 을 등록해서 block 하지 않고, reclaim 시점이 될 때 까지 비동기적으로 기다린다. callback 함수는 old RCU-protected data 에 대한 레퍼런스를 가진 RCU read-side critical section 이 종료될 때, 알아서 호출된다.- What is grace period and quiescent state ?
" RCU 메커니즘에서 reader 가 크리티컬 섹션에 진입해있는 동안에 updater 가 진입해서 값을 변경할 수 있다. 이 때, reader 는 old data 에 대한 참조를 가지고 있게되고, updater 는 old data 에 대한 참조를 제거하기 위해서 모든 reader`s 들이 old data 에 대한 참조를 release 할 때 까지 대기해야 한다. 문제는 old data 에 대한 참조를 가지고 있는 모든 reader`s 가 언제 release 하는지를 알 기가 어렵다는 것이다. 이렇게, RCU updater 가 old data reference 를 제거하는 순간부터 마지막 old data reference 를 가지고 있는 reader 가 크리티컬 섹션을 나가는 지점까지를 `grace period(GP)` 라고 한다. 아래에서 그림에서 grace period 는 removal 와 reclaim 사이가 된다. `reclaim` 는 updater 가 atomic operation 을 통해 포인터를 교체함으로써 old reference 를 removed 한 것을 의미하고, `reclaim` 는 old reference 를 실제 free 하는 시점을 의미한다.
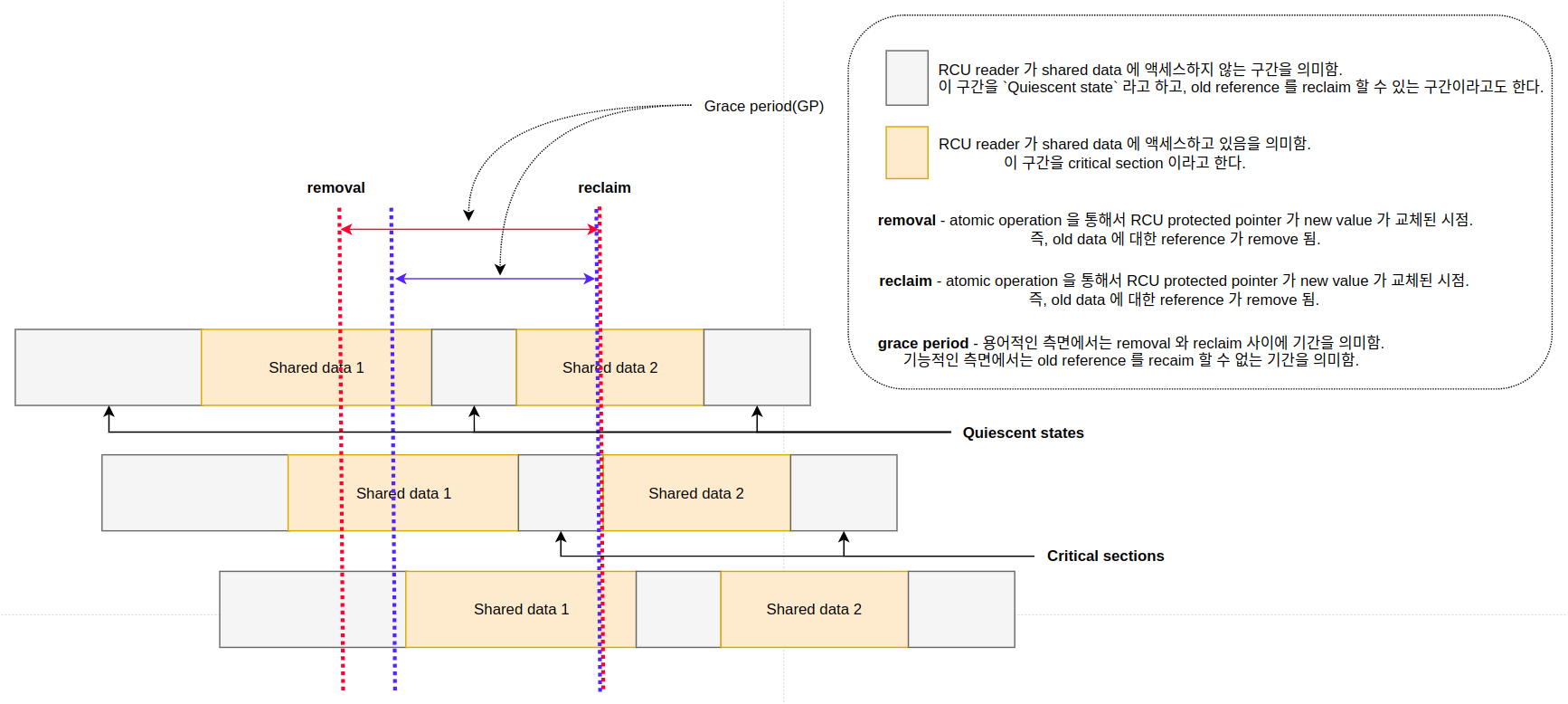
" RCU reader 가 shared data 에 액세스하지 않는 구간을 `Quiescent state` 라고 한다. 이 구간은 old reference 를 reclaim 할 수 있는가에 대한 조건을 사용된다. 참고로, RCU 가 어려운 이유는 GP 와 Quiescent state 를 어떻게 파악해야 하는지가 굉장히 어렵기 때문이다.
'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Synchronization - Per-CPU Overview (0) 2023.10.18 [리눅스 커널] Interrupt - Softirq (0) 2023.10.18 [리눅스 커널] Synchronization - sequential locks (0) 2023.10.11 [리눅스 커널] LDM - uevent (0) 2023.10.03 [리눅스 커널] Timer - timekeeping (0) 2023.10.03