-
[리눅스 커널] Synchronization - Per-CPU OverviewLinux/kernel 2023. 10. 18. 19:47
글의 참고
- https://www.kernel.org/doc/Documentation/this_cpu_ops.txt
- https://www.makelinux.net/ldd3/chp-8-sect-5.shtml
- http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch11lev1sec10.html
- http://www.wowotech.net/linux_kenrel/per-cpu.html
- https://zhuanlan.zhihu.com/p/260986194
- https://thinkiii.blogspot.com/2014/05/a-brief-introduction-to-per-cpu.html
- http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch11lev1sec12.html
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" Per-CPU 변수를 사용하는 첫 번째 이유는 프로세서 들간에 동시성을 보장받기 위해서다. 예를 들어, Per-CPU 데이터는 다른 CPU들과 공유하지 않기 때문에 lock 이 필요가 없다. 당연히, lock 이 필요없으니 퍼포먼스는 자연스럽게 따라오게 된다. Per-CPU 변수를 사용하는 두 번째 이유는 `캐쉬 힛(cache hit)` 을 높이기 위해서다. 캐쉬를 사용하는 것이 포퍼먼스에 좋다는 것은 누구나 아는 사실이다. 그런데, 캐쉬만 사용한다고 해서 무조건 성능이 좋아지는 것은 아니다. 캐쉬 미스의 확률이 높다면, 퍼포먼스가 더 떨어질 수 도 있다. L1 캐쉬는 각 CPU 마다 개별적으로 갖는 캐쉬다. 이 캐쉬는 2가지로 명령어 캐쉬와 데이터 캐쉬로 나뉜다. 그리고, L2 캐쉬는 모든 CPU가 공유하는 캐쉬다.

" 위 그림에서 빨간색으로 표시된 부분은 모든 CPU가 공유하는 데이터 `A` 의 주소라고 가정하자. 여기서 CPU[0]이 A의 값을 변경할 경우, 시스템은 캐쉬 동기화를 위해 데이터 A 에 대응하는 CPU들의 모든 L1 캐쉬 라인이 무효가 된다. 당연히 이러한 행동이 퍼포먼스에 영향을 준다. 이 변수를 Per-CPU 타입으로 선언하면 어떻게 될까? 더 이상 CPU들끼리 데이터를 공유하지 않기 때문에, `cache invalid`는 덜 발생하게 될 것이다. 그러나, 메모리를 이전보다 더 사용하게 된다. 그리고, 여러 CPU 들 간에 동시성 문제는 해결할 수 있지만, 여전히 한 CPU 내에서 여러 태스크들간에 동시성 문제를 해결해주지는 않는다. 확실한 건 다른 CPU 때문에 cache invalid 가 발생할 일은 줄어든다는 것이다.

" 그리고, 당연한 얘기겠지만 Per-CPU 변수는 다른 CPU 에게 스케줄링되지 못한다. 즉, Per-CPU 변수는 자동으로 자신이 속한 CPU 에게 Affinity 된다고 볼 수 있다. 그리고, 현재 리눅스 커널은 Per-CPU 변수에 액세스할 때 preemption 을 비활성화 한다. 즉, 다른 태스크들에게 선점되는 것을 막는다. Per-CPU 변수를 사용하더라도 lock 을 사용할 수 밖에 없다는 것이 안타깝지만, 그래도 lock 메커니즘 중에서는 `disable preemption`은 상대적으로 비용이 적은 메커니즘이라고 볼 수 있다.
- Per-CPU architecture
" Per-CPU 변수는 총 3가지로 나눌 수 있다. 그래서, 주소 영역도 3가지로 나뉜다. 이 글에서는 `Static In-kernel Per-CPU` 만 설명한다.
1. Static Per-CPU Variable
- In-kernel
- moudle
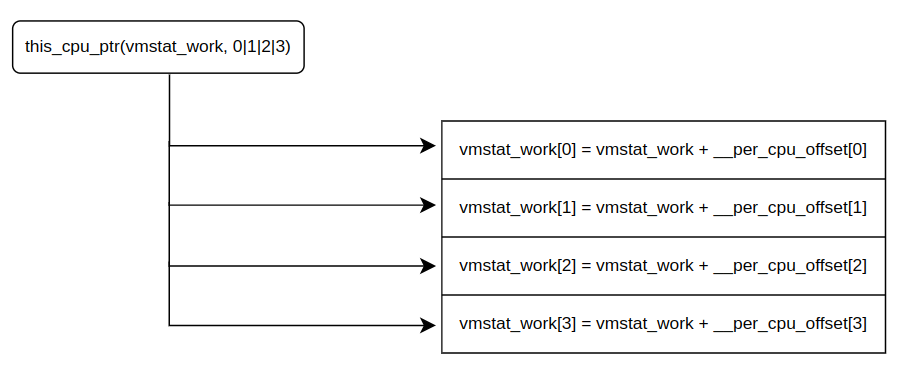
2. Dynamic Per-CPU Variable" static Per-CPU 변수를 선언하면, 컴파일러는 해당 변수들을 모두 per-cpu 섹션에 저장한다. static per-cpu 영역은, __per_cpu_start / __per_cpu_end 심볼로 둘러쌓여있다. 아래 per-cpu 섹션을 보면 `vmstat_work` 변수가 하나 선언되어 있는 것을 볼 수 있다. 그런데, 궁금증이 생겼다. vmstat_work 는 `static DEFINE_PER_CPU(struct delayed_work, vmstat_work)` 로 선언되었다. 이 말은 CPU가 4개 존재한다면, vmstat_work 도 per-cpu 섹션에 4개 존재해야 하는거 아닌가? 그런데, 한 개밖에 보이지가 않는다. 나머지 3개는 어디에 있을까?
// https://thinkiii.blogspot.com/2014/05/a-brief-introduction-to-per-cpu.html 0000000000000000 D __per_cpu_start ... 000000000000f1c0 d lru_add_drain_work 000000000000f1e0 D vm_event_states 000000000000f420 d vmstat_work 000000000000f4a0 d vmap_block_queue 000000000000f4c0 d vfree_deferred 000000000000f4f0 d memory_failure_cpu ... 0000000000013ac0 D __per_cpu_end [15] .vvar PROGBITS ffffffff81698000 00898000 00000000000000f0 0000000000000000 WA 0 0 16 [16] .data..percpu PROGBITS 0000000000000000 00a00000 0000000000013ac0 0000000000000000 WA 0 0 4096 [17] .init.text PROGBITS ffffffff816ad000 00aad000 000000000003fa21 0000000000000000 AX 0 0 16" vmstat_work 는 코드상에서는 배열과 같이 선언된다. 예를 들어, CPU가 4개 있는데 시스템이라면, vmstat_work 의 메모리 공간은 다음과 같다. 즉, vmstat_work[0] == 0x0000_0000_0000_0f420, vmstat_work[1] == 0x0000_0000_0000_0f440, vmstat_work[2] == 0x0000_0000_0000_0f460, vmstat_work[2] == 0x0000_0000_0000_0f480 이다.
" 모든 CPU의 static Per-CPU 영역의 사이즈는 `__per_cpu_end - __per_cpu_start` 가 된다. 이 영역안에서 각 CPU의 Per-CPU 영역에 접근하기 위해서는 `__per_cpu_offset` 를 사용하면 된다.
// include/asm-generic/vmlinux.lds.h - v6.5 /** * PERCPU_INPUT - the percpu input sections * @cacheline: cacheline size * * The core percpu section names and core symbols which do not rely * directly upon load addresses. * * @cacheline is used to align subsections to avoid false cacheline * sharing between subsections for different purposes. */ #define PERCPU_INPUT(cacheline) \ __per_cpu_start = .; \ *(.data..percpu..first) \ . = ALIGN(PAGE_SIZE); \ *(.data..percpu..page_aligned) \ . = ALIGN(cacheline); \ *(.data..percpu..read_mostly) \ . = ALIGN(cacheline); \ *(.data..percpu) \ *(.data..percpu..shared_aligned) \ PERCPU_DECRYPTED_SECTION \ __per_cpu_end = .;" 우리가 DEFINE_PER_CPU 매크로를 통해 생성하는 Per-CPU 변수들은 위에 `data..percpu` 섹션에 생성된다. 그걸 어떻게 알 수 있을까? 바로 뒤에서 알아본다.
- Define static per-cpu variable
" `DEFINE_PER_CPU` 매크로를 통해서 어떻게 Per-CPU 변수가 생성되는지를 분석한다. DEFINE_PER_CPU 매크로의 type은 생성할 변수의 data type을 나타낸다. 그리고, name은 변수 이름을 나타낸다.
// include/linux/percpu-defs.h - v6.5 #define DEFINE_PER_CPU(type, name) \ DEFINE_PER_CPU_SECTION(type, name, "")" DEFINE_PER_CPU_SECTION 매크로는 인자로 전달된 type, name, sec 을 통해서 Per-CPU section 에 변수를 생성한다. `sec` 은 section 의 약자다.
// include/linux/percpu-defs.h - v6.5 #if defined(ARCH_NEEDS_WEAK_PER_CPU) || defined(CONFIG_DEBUG_FORCE_WEAK_PER_CPU) .... #else /* * Normal declaration and definition macros. */ .... #define DEFINE_PER_CPU_SECTION(type, name, sec) \ __PCPU_ATTRS(sec) __typeof__(type) name #endif" __typeof__ 연산자는 인자로 전달된 변수의 데이터 타입을 반환한다. 예를 들어, `int x;` 에서 `__typeof__(x)`는 int 를 반환한다. 결국, `__typeof__ (type) name` 을 통해서 변수가 생성된다.
" `__PCPU_ATTRS` 매크로는 생성된 변수가 어떤 Per-CPU 섹션에 생성될지를 결정한다.
// include/linux/percpu-defs.h - v6.5 #define __PCPU_ATTRS(sec) \ __percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \ PER_CPU_ATTRIBUTES" __attribute__((section("name"))) 은 해당 코드를 `name` 섹션에 배치되도록 한다. 예를 들어, 아래 Function_Attributes_section_0 은 `.text` 섹션이 아닌,`new_section` 라는 섹션에 배치된다.
// https://developer.arm.com/documentation/dui0472/k/Compiler-specific-Features/--attribute----section--name-----function-attribute void Function_Attributes_section_0 (void) __attribute__((section ("new_section"))); void Function_Attributes_section_0 (void) { static int aStatic =0; aStatic++; }" `__percpu` 흔히 `tag` 라고 불리며, __percpu 속성이 설정된 포인터 변수는 percpu memory region 을 가리키게 된다. percpu memroy region 은 위에서 `PER_CPU_BASE_SECION sec` 을 통해서 생성된 섹션을 의미한다.
Similarly, we have __percpu attribute, which is mainly used to indicate memory is allocated in percpu region. The __percpu pointers in kernel are supposed to be used together with functions like per_cpu_ptr() and this_cpu_ptr(), which perform necessary calculation on the pointer's base address.
....
- 참고 : https://patchwork.kernel.org/project/netdevbpf/patch/20220304191657.981240-3-haoluo@google.com/#24769426// include/linux/compiler_types.h - v6.5 /* sparse defines __CHECKER__; see Documentation/dev-tools/sparse.rst */ #ifdef __CHECKER__ /* address spaces */ # define __percpu __attribute__((noderef, address_space(__percpu))) .... #else /* __CHECKER__ */ .... # define __percpu BTF_TYPE_TAG(percpu) ...." 여기서 address_space() 의 정체가 뭘까? 이 친구들은 또한 `attribute` 의 종류 중 하나다. 그런데, GCC 속성은 아니다. 이들은 `Sparse attribute` 라고 해서 오직 `Sparse` 에게만 의미가 있다(빌드 시 __CHECKER__ 플래그를 설정하지 않으면, Sparse 는 의미가 없다). 예를 들어, C언어 에서는 리틀, 빅 엔디안 변수를 구분할 수 있는 방법이 없다. 그런데, 아래와 같이 Sparse 가 지원하는 `__bitwise` 속성을 사용하면 리틀 및 빅 엔디안을 구분할 수 있다. 참고로, __bitwise 속성을 사용함으로써 아래의 2개의 타입이 다르다는 것을 컴파일러에게 알려준다. 그리고, 2개를 혼용해서 사용할 경우, 경고를 한다.
// https://en.wikipedia.org/wiki/Sparse typedef __u32 __bitwise __le32; typedef __u32 __bitwise __be32;" `address_space(__percpu)` 는 포인터 변수가 __percpu 메모리로 지정된 영역에 있음을 나타낸다. Sparse는 __percpu 메모리 영역에 있는 데이터를 일반 커널 영역에 포인터가 참조할 경우에, 경고를 일으킨다[참고1]. 그리고, 직접적으로 __percpu 영역에 있는 `dereferencing` 할 경우에도 경고를 한다. 그러므로, get_cpu_var / put_cpu_var 함수를 통해서 간적접으로 __percpu 변수에 접근해야 한다.
" 그리고, `PER_CPU_ATTRIBUTES` 는 empty value 인 것을 확인할 수 있다. 그렇다면, PER_CPU_BASE_SECTION 은 뭘까?
// include/asm-generic/percpu.h - v6.5 #ifndef PER_CPU_BASE_SECTION #ifdef CONFIG_SMP #define PER_CPU_BASE_SECTION ".data..percpu" #else #define PER_CPU_BASE_SECTION ".data" #endif #endif #ifndef PER_CPU_ATTRIBUTES #define PER_CPU_ATTRIBUTES #endif" PER_CPU_BASE_SECTION 은 위에서 볼 수 있다시피, `.data..perpcu` 혹은 `.data` 섹션을 나타낸다. 현대의 거의 대부분의 CPU 아키텍처는 SMP 를 기반으로 하기 때문에, `data..percpu` 섹션에 per-cpu 데이터가 저장된다.
" 그런데, 궁금한 점이 생겼다. percpu.h 파일은 왜 `asm-generic/` 폴더에 있을까? 그리고, 이 폴더는 정체가 뭘까? 먼저, asm 은 assembler 의 줄임말이다. 어셈블리어는 아키텍처 종속적인 코드를 의미하며, 이 말은 하드웨어와 깊은 연관이 있다는 뜻이다. 즉, asm-generic/ 폴더에 있는 파일들은 아키텍처 종속적이며 하드웨어와 깊은 연관이 있는 코드들이 작성되어 있다. 그러나, 아키텍처마다 공통적으로 지원해야 하는 하드웨어 기능들이 분명히 있다. 예를 들어, 현대의 모든 CPU는 페이징을 지원하고 있다. 페이즈 사이즈는 대개 2048 혹은 4096 바이트다. 이와 같이, 아키텍처 종속적인이지만, 공통적인 기능을 asm-generic/ 폴더에 넣는다.
" 그렇다면, asm/ 과 asm-generic/ 의 차이는 뭘까? 예를 들어, `include/asm-generic/tlb.h` 과 `arch/arm/include/asm/tlb.h` 의 차이는 뭘까? arch/${ARCH}/include/asm/ 폴더에 들어있는 헤더 파일들은 말 그대로 아키텍처 종속적인 코드들이 있는곳이다. 여기서는 인터페이스가 통일되어 있지 않다. 그리고, 일반적으로 arch/${ARCH}/include/asm/ 폴더에 있는 파일들이 include/asm-generic/ 폴더에 있는 파일들을 include 해서 사용한다. 왜냐면, include/asm-generic/ 폴더에 있는 파일들이 common 한 파일들이기 때문이다[참고1].
- Two problems in kernel preemption
" Per-CPU 데이터를 사용해서 코드를 작성할 때, 2 가지 주의할 점이 있다.
1. 프로세서들 간에 선점을 막아야 한다.
2. 한 개의 프로세서 내부의 쓰레드 간에 선점을 막아야 한다." 예를 들어, CPU[0] 에서 process A 가 `yohda_percpu()` 함수를 실행중이다. 이 때, process A 에게는 `cpu` 변수는 0 일 것이다. 그런데, process A가 `my_percpu[cpu]++` 코드를 실행하기 전에 CPU[1] 에게 선점당했다고 치자. CPU[1] 에서 `cpu` 변수는 1 이여야 한다. 왜냐면, yohda_percpu() 함수를 실행중인 process A 는 현재 CPU[1] 에서 실행 중이기 때문이다. 그런데, process A 의 스택에는 cpu 변수가 이미 0 으로 저장되어 있다. 즉, CPU[1] 에서 CPU[0] 의 Per-CPU 변수를 수정하고 있는 것이다.
// http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch11lev1sec10.html void yohda_percpu(void){ int cpu; cpu = get_cpu(); my_percpu[cpu]++; printk("my_percpu on cpu=%d is %lu\n", cpu, my_percpu[cpu]); }" 두 번째로, 동일 프로세서에서 서로 다른 쓰레드간에 선점도 문제가 된다. 예를 들어, printk 에 출력되는 my_percpu[cpu] 의 값은 무조건 순차적으로 증가해야 한다고 가정하자. process A가 `my_percpu[cpu]++;` 를 실행한 후에 my_percpu[cpu] 의 값이 1이 됬다. 이제 출력만 하면 된다. 그런데, 프로세스 A 가 printk 문을 실행하기전에 process B 에게 선점당했다. 그런데, 여기서 문제가 발생한다. process B 또한 yohda_percpu() 함수를 호출하는 것이다. process B 는 `my_percpu[cpu]++;` 코드를 실행한 후 printk 문을 실행했다. 이 때, 1(process A) 보다 2(process B) 가 먼저 출력되는 상황이 발생한다.
" 위와 같은 상황들은 모두 선점을 막지못해 발생한 문제라고 볼 수 있다. 그런데, 인터럽트를 막지 않아도 될까? 다른 프로세서에 의한 선점을 막은 상황이라고 가정한다면, 인터럽트가 발생해도 안전하다고 볼 수 있다. 인터럽트가 발생하고 리턴하는 시점에, 커널 스페이스로 리턴한다면(유저 스페이스는 제외), need_resched & preempt_count 를 확인한다. 이 때, need_resched 가 true 고 preempt_count 가 0 라면, 우선 순위가 더 높은 프로세스를 실행할 수 있다는 뜻이다. 즉, 선점을 해도 안전하다는 뜻이다. 그러나, preempt_count 가 0 이 아니라면, 이전 프로세스가 임의의 lock 을 잡고 있다는 뜻이고, 인터럽트에 의한 선점당한 프로세스를 완전히 선점하는 것은 안전하지 않다는 뜻이다. 이런 경우, 인터럽트가 리턴되는 시점에, 인터럽트에 의한 선점당했던 프로세스로 리턴하게 된다.
" 즉, preempt_count 만 disable 한다면, interrupt 에 의해 선점당했던 process 가 interrupt 이후에도 계속 해당 processor 에서 실행을 이어나갈 수 있음을 의미한다. 결론적으로, Per-CPU 데이터는 인터럽트 및 프로세스 컨택스트에서 안전하다고 볼 수 있다. 그러나, Per-CPU 데이터를 사용중 인 영역에서는 절대 SLEEP 하면 안된다(즉, schedule() 계열의 함수를 사용하면 안된다). 왜냐면, SLEEP 에서 깨어난 프로세스가 다른 프로세서에서 실행될 가능성이 있기 때문이다.
" get_cpu_ptr / put_cpu_ptr 함수는 서로 pair 로 preemption 을 disable / enable 한다. preempt 가 보장되지 않은 상황에서 get_cpu_ptr 함수를 호출해서 preempt 를 허용하지 않게 한 뒤 Per-CPU 데이터를 수정한다. 수정을 끝내면 다시 preemption 을 활성화하기 위해 put_cpu_ptr 함수를 호출한다.
// include/linux/percpu-defs.h - v6.5 #define get_cpu_ptr(var) \ ({ \ preempt_disable(); \ this_cpu_ptr(var); \ }) #define put_cpu_ptr(var) \ do { \ (void)(var); \ preempt_enable(); \ } while (0)- How to get Per-CPU variable ?
" 커널에서 Per-CPU 관련 가장 많이 사용되는 함수가 `this_cpu_ptr()` 함수다. 이 함수는 CPU 번호를 인자로 받아서 Per-CPU 포인터를 반환한다. 먼저, SHIFT_PERCPU_PTR 매크로는 `ptr(첫 번째 인자) + my_cpu_offset(두 번째 인자)` 를 반환한다. SHIFT_PERCPU_PTR 매크로는 내부적으로 RELOC_HIDE 를 호출하는데 여기서 `__ptr + off` 를 확인할 수 있다. 즉, SHIFT_PERCPU_PTR 매크로가 실제 Per-CPU 포인터 변수를 반환하는 기능을 맡고있다. `__verify_pcpu_ptr` 매크로는 인자로 전달된 ptr 이 percpu pointer 인지를 검사한다.
// include/linux/compiler-gcc.h - v6.5 #define RELOC_HIDE(ptr, off) \ ({ \ unsigned long __ptr; \ __asm__ ("" : "=r"(__ptr) : "0"(ptr)); \ (typeof(ptr)) (__ptr + (off)); \ }) // include/linux/percpu-defs.h - v6.5 /* * Add an offset to a pointer but keep the pointer as-is. Use RELOC_HIDE() * to prevent the compiler from making incorrect assumptions about the * pointer value. The weird cast keeps both GCC and sparse happy. */ #define SHIFT_PERCPU_PTR(__p, __offset) \ RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset)) .... #ifdef CONFIG_DEBUG_PREEMPT #define this_cpu_ptr(ptr) \ ({ \ __verify_pcpu_ptr(ptr); \ SHIFT_PERCPU_PTR(ptr, my_cpu_offset); \ }) #else #define this_cpu_ptr(ptr) raw_cpu_ptr(ptr) #endif" my_cpu_offset 은 각 Per-CPU 영역의 base address를 반환한다. my_cpu_offset 는 `per_cpu_offset(smp_processor_id())` 로 치환된다.
// include/asm-generic/percpu.h - v6.5 /* * Determine the offset for the currently active processor. * An arch may define __my_cpu_offset to provide a more effective * means of obtaining the offset to the per cpu variables of the * current processor. */ #ifndef __my_cpu_offset #define __my_cpu_offset per_cpu_offset(raw_smp_processor_id()) #endif #ifdef CONFIG_DEBUG_PREEMPT #define my_cpu_offset per_cpu_offset(smp_processor_id()) #else #define my_cpu_offset __my_cpu_offset #endif" 각 Per-CPU 의 base address 는 __per_cpu_offset 변수에 저장되어 있다. 이 주소는 링커스크립트 & Per-CPU 메모리 매니지먼트 모듈에 의해 만들어진다. __per_cpu_offset 에 각 CPU 번호를 주면, Per-CPU base address 를 준다는 것만 알면된다.
// include/asm-generic/percpu.h - v6.5 /* * per_cpu_offset() is the offset that has to be added to a * percpu variable to get to the instance for a certain processor. * * Most arches use the __per_cpu_offset array for those offsets but * some arches have their own ways of determining the offset (x86_64, s390). */ #ifndef __per_cpu_offset extern unsigned long __per_cpu_offset[NR_CPUS]; #define per_cpu_offset(x) (__per_cpu_offset[x]) #endif" Per-CPU 메모리 매니지먼트 모듈이 __per_cpu_offset 을 초기화하는 코드는 아래와 같다.
// mm/percpu.c - v6.5 unsigned long __per_cpu_offset[NR_CPUS] __read_mostly; EXPORT_SYMBOL(__per_cpu_offset); void __init setup_per_cpu_areas(void) { unsigned long delta; unsigned int cpu; .... delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start; for_each_possible_cpu(cpu) __per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu]; }- How to read Per-CPU variable ?
" Per-CPU 연산 함수들은 대개 매크로가 상당히 복잡하게 엉켜있다. 그래서 예시를 통해 중간 과정에서 생성되는 결과물들을 관찰하는것이 중요하다.
// include/linux/percpu-defs.h - v6.5 /* * Operations for contexts that are safe from preemption/interrupts. These * operations verify that preemption is disabled. */ #define __this_cpu_read(pcp) \ ({ \ __this_cpu_preempt_check("read"); \ raw_cpu_read(pcp); \ })// include/linux/percpu-defs.h #define raw_cpu_read(pcp) __pcpu_size_call_return(raw_cpu_read_, pcp)// include/linux/percpu-defs.h - v6.5 #define __pcpu_size_call_return(stem, variable) \ ({ \ typeof(variable) pscr_ret__; \ __verify_pcpu_ptr(&(variable)); \ switch(sizeof(variable)) { \ case 1: pscr_ret__ = stem##1(variable); break; \ case 2: pscr_ret__ = stem##2(variable); break; \ case 4: pscr_ret__ = stem##4(variable); break; \ case 8: pscr_ret__ = stem##8(variable); break; \ default: \ __bad_size_call_parameter(); break; \ } \ pscr_ret__; \ })" typeof 연산자는 인자로 전달된 변수의 타입을 반환한다. 일반 변수와 포인터 변수까지도 구분해준다.
#include <stdio.h> int main() { int a; short b; short *c; char *ch; typeof(a) per; typeof(b) per1; typeof(c) per2; typeof(ch) per3; printf("sizeof:%d\n", sizeof(per)); // 4 printf("sizeof:%d\n", sizeof(per1)); // 2 printf("sizeof:%d\n", sizeof(per2)); // 8 printf("sizeof:%d\n", sizeof(per3)); // 8 return 0; }" 만약에, 아래와 같이 __this_cpu_read 함수가 호출될 경우 최종 결과물은 어떻게 될까? 핵심은 __pcpu_size_call_return 매크로가 어떻게 변환되는지를 알아야 한다.
static void wakeup_softirqd(void) { /* Interrupts are disabled: no need to stop preemption */ struct task_struct *tsk = __this_cpu_read(ksoftirqd); if (tsk) wake_up_process(tsk); }({ \ struct task_struct *pscr_ret__; \ __verify_pcpu_ptr(&(ksoftirqd)); \ switch(sizeof(ksoftirqd)) { \ case 1: pscr_ret__ = raw_cpu_read_1(ksoftirqd); break; \ case 2: pscr_ret__ = raw_cpu_read_2(ksoftirqd); break; \ case 4: pscr_ret__ = raw_cpu_read_4(ksoftirqd); break; \ case 8: pscr_ret__ = raw_cpu_read_8(ksoftirqd); break; \ default: \ __bad_size_call_parameter(); break; \ } \ pscr_ret__; \ })" 아래 코드를 보고 조금 이상한 감을 느껴야 한다. raw_cpu_read_* 계열 함수들은 모두 raw_cpu_generic_read 함수를 호출한다. 즉, 모두 동일한 함수를 호출한다. 그런데, 전달하는 인자마저 동일하다. 이럴거면 왜 raw_cpu_read_[1|2|4|8] 로 나눴을까?
// include/asm-generic/percpu.h #ifndef raw_cpu_read_1 #define raw_cpu_read_1(pcp) raw_cpu_generic_read(pcp) #endif #ifndef raw_cpu_read_2 #define raw_cpu_read_2(pcp) raw_cpu_generic_read(pcp) #endif #ifndef raw_cpu_read_4 #define raw_cpu_read_4(pcp) raw_cpu_generic_read(pcp) #endif #ifndef raw_cpu_read_8 #define raw_cpu_read_8(pcp) raw_cpu_generic_read(pcp) #endif" 미래에 사용될 수 있기 때문에 미리 나눠놓은 것이라고밖에 볼 수 없을 듯 싶다. 즉, 추후에는 변수의 사이즈까지 고려해야 하는 최적화가 필요한 상황이 올 수 도 있기 때문에 미리 나눠놓은 듯 싶다. 왜냐면, x86 이 실제로 그렇게 하고 있기 때문이다.
// arch/x86/include/asm/percpu.h - v6.5 #define raw_cpu_read_1(pcp) percpu_from_op(1, , "mov", pcp) #define raw_cpu_read_2(pcp) percpu_from_op(2, , "mov", pcp) #define raw_cpu_read_4(pcp) percpu_from_op(4, , "mov", pcp)// include/asm-generic/percpu.h - v6.5 #define raw_cpu_generic_read(pcp) \ ({ \ *raw_cpu_ptr(&(pcp)); \ })" 또 다른 주목할 부분은 raw_cpu_generic_read 매크로 함수 내부에 `*raw_cpu_ptr(&pcp))` 구조에 있다.
1. 왜 `&(pcp)` 를 전달할까 ?
2. 왜 반환값에 `*` 을 사용했을까 ?" 위의 질문에 대한 대답은 이 섹션 마지막을 확인하자.
" arch_raw_cpu_ptr 은 최종적으로 SHIFT_PERCPU_PTR 을 호출한다. 이걸 통해 위에서 raw_cpu_generic_read 함수에 `일반 변수`와 `포인터 변수`가 전달되었을 때, 차이를 알아보자.
#ifdef CONFIG_SMP #define raw_cpu_ptr(ptr) \ ({ \ __verify_pcpu_ptr(ptr); \ arch_raw_cpu_ptr(ptr); \ }) #else #define raw_cpu_ptr(ptr) per_cpu_ptr(ptr, 0) #endif// include/asm-generic/percpu.h - v6.5 /* * Arch may define arch_raw_cpu_ptr() to provide more efficient address * translations for raw_cpu_ptr(). */ #ifndef arch_raw_cpu_ptr #define arch_raw_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, __my_cpu_offset) #endif1. 왜 `&(pcp)` 를 전달할까 ? 각 Per-CPU 마다 영역이 나눠져 있다. 자신이 할당된 영역을 찾기위해서는 `자신의 주소`에 자신에게 맞는 __per_cpu_offset[x] 이 더해져야 한다. 즉, 자신의 주소를 알아야 하기 때문에 주소를 전달하는 것이다.
2. 왜 반환값에 `*` 을 사용했을까 ? 최종적으로, SHIFT_PERCPU_PTR 에서 반환되는 값이 주소이기 때문이다. __this_cpu_read 함수를 호출한 개발자가 원하는 값은 주소가 아니다. 주소에 들어있는 값을 원한다.
- 일반 변수 :
1. &(일반 변수) == 일반 변수의 주소
2. *&(일반 변수) == 일반 변수 = 일반 변수가 저장하고 있는 값
- 포인터 변수 :
1. &(포인터 변수) == 포인터 변수의 주소
2. *&(포인터 변수) == 포인터 변수 == 포인터 변수가 가리키고 있는 주소값'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Scheduler - Basic (0) 2023.10.30 [리눅스 커널] Interrupt - Tasklet (0) 2023.10.28 [리눅스 커널] Interrupt - Softirq (0) 2023.10.18 [리눅스 커널] Synchronization - RCU Overview (0) 2023.10.16 [리눅스 커널] Synchronization - sequential locks (0) 2023.10.11