-
xv6 - Init process프로젝트/운영체제 만들기 2023. 7. 12. 15:18
글의 참고
- book-rev11.pdf
- https://github.com/mit-pdos/xv6-public
- https://pdos.csail.mit.edu/6.828/2022/xv6.html
글의 전제
- 32비트 x86 기반의 xv6 rev-11을 내 나름대로 분석한 내용이다.
글의 내용
- Abstracting physical resources
: 유저 애플리케이션이 하드웨어 직접적으로 접근해서 사용하면 운영체제를 거처셔 접근할 때보다 성능면에서 더 좋은 퍼포먼스를 낼 수 바께 없다. 그리고 성능 및 레이턴시에 대한 예측이 수월해지기 때문에 최적화 또한 상대적으로 쉬워진다. 그래서 실제로 OS가 없는 펌웨어들은 OS가 들어가는 펌웨어보다 성능면에서 훨씬 좋다.
The first question one might ask when encountering an operating system is why have it at all? That is, one could implement the system calls in Figure 0-2 as a library, with which applications link. In this plan, each application could even have its own library tailored to its needs. Applications could directly interact with hardware resources and use those resources in the best way for the application (e.g., to achieve high or predictable performance). Some operating systems for embedded devices or real-time systems are organized in this way.
The downside of this library approach is that, if there is more than one application running, the applications must be well-behaved. For example, each application must periodically give up the processor so that other applications can run. Such a cooperative time-sharing scheme may be OK if all applications trust each other and have no bugs. It’s more typical for applications to not trust each other, and to have bugs, so one often wants stronger isolation than a cooperative scheme provides.: 그러나, OS가 삽입되는 펌웨어에서 애플리케이션들끼리 서로 신뢰하는 것은 좋지 못한 결과를 만든다. 예를 들어, 싱글 프로세서에서 A와 B라는 프로세스가 있을 때, A가 프로세서를 독점하게 될 경우, B는 아무것도 못하게 될 수 있다. `xv6`는 일반적인 관점에서 애플리케이션들끼리 서로를 신뢰하는 것은 더 많은 버그를 발생시킬 여지가 많다고 한다. 그래서 현대의 운영체제들은 각 프로세스들에게 더욱 더 강력하게 `고립`시킨다. 그러나, 애플과 같이 폐쇠적이면서 자체 SW 을 개발하는 회사에서는 `cooperative` 방식으로 프로세스 스케줄링 한다고 알고 있다.
- User mode, kernel mode and system calls
Strong isolation requires a hard boundary between applications and the operating system. If the application makes a mistake, we don’t want the operating system to fail or other applications to fail. Instead, the operating system should be able to clean up the failed application and continue running other applications. To achieve strong isolation, the operating system must arrange that applications cannot modify (or even read) the operating system’s data structures and instructions and that applications cannot access other process’s memory
Processors provide hardware support for strong isolation. For example, the x86 processor, like many other processors, has two modes in which the processor can execute instructions: kernel mode and user mode. In kernel mode the processor is allowed to execute privileged instructions. For example, reading and writing the disk (or any other I/O device) involves privileged instructions. If an application in user mode attempts to execute a privileged instruction, then the processor doesn’t execute the instruction, but switches to kernel mode so that the software in kernel mode can clean up the application, because it did something it shouldn’t be doing. Figure 0-1 in Chapter 0 illustrates this organization. An application can execute only user-mode instructions (e.g., adding numbers, etc.) and is said to be running in user space, while the software in kernel mode can also execute privileged instructions and is said to be running in kernel space. The software running in kernel space (or in kernel mode) is called the kernel.: 프로세스는 하드웨어 차원에서 지원해주는 강력한 `고립` 기능을 통해서 유저 레벨 애플리케이션들이 커널 영역에 접근할 수 없게 만든다. 심지어, 같은 유저 레벨 애플리케이션들 끼리라도 서로의 영역에 접근할 수 없게 만든다. 이런 기능은 하드웨어가 지원해주는 메모리 관리 기법(세그멘테이션, 페이징)을 사용해서 만들어진다. 현재 대부분의 OS는 페이징을 통해 접근 권한 검사와 프로세스 고립을 지원해준다.
: 예를 들어, x86 기준으로 유절 레벨로 코드의 흐름이 바뀔 경우, 코드 및 데이터 세그먼테이션을 유저 레벨 세그먼테이션으로 재설정하게 된다. 이 때, CPL이 3으로 설정된다. 그런데, `xv6` 같은 경우 프로세스 하나 당 하나의 페이지 테이블을 갖는다. 2GB는 유저 영역, 나머지 2GB는 커널 영역으로 할당된다. 이 때, 각 페이지마다 권한을 설정할 수 가 있다(PTE.US[2]). 그래서 페이지에 접근할 때 마다, 현재 CPL을 검사해서 이 페이지에 접근 권한이 있는지를 체크한다. 유저 영역에서 `0xFF22_32DF`는 당연히 허용하지 않는다. 왜냐면, `0xFF22_32DF` 영역은 커널 영역이기 때문이다(`0xFF22_3000` PTE의 2번째 비트가 아마 `0`일 것이기 때문이다).
: 페이지 테이블에 직접 접근해서 페이지 설정을 변경하는 것은 어떨까? 페이지 테이블은 반드시 커널 영역에 존재해야 한다. 페이지 테이블뿐만이 아니다. 반드시 모든 시스템 자료 구조들은 유저 레벨에서 접근할 수 없는 커널 영역에 상주하고 있어야 한다.
: 유저 모드에서 시스템 콜을 호출하면 커널 모드로 전환된다. 그리고, 유저 레벨에서 요청한 시스템 콜의 엔트리 포인트로 점프하게 된다. 즉, 유저 레벨에서 `SYSTEM CALL <2> <123>`와 같은 형식으 호출하면 커널은 제일 앞에 번호를 파악해서 유저 레벨에서 어떤 기능을 요청하는지를 확인한다. `2`이 FILE I/O 작업이라고 치자. 그렇면, 커널은 FILE I/O 작업에 매개변수로 전달된 `123`을 인자로 전달해서 작업을 처리한다. 여기서 핵심은 유저 레벨은 `2`번 기능에 대한 정확한 엔트리 포인트를 모른다는 것이다.
An application that wants to read or write a file on disk must transition to the kernel to do so, because the application itself can not execute I/O instructions. Processors provide a special instruction that switches the processor from user mode to kernel mode and enters the kernel at an entry point specified by the kernel. (The x86 processor provides the `int` instruction for this purpose.) Once the processor has switched to kernel mode, the kernel can then validate the arguments of the system call, decide whether the application is allowed to perform the requested operation, and then deny it or execute it. It is important that the kernel sets the entry point for transitions to kernel mode; if the application could decide the kernel entry point, a malicious application could enter the kernel at a point where the validation of arguments etc. is skipped.
- Process overview
: 대부분의 운영체제와 `xv6`도 그렇지만, 대부분의 `고립`의 단위는 프로세스다. 중요한 건 `고립`의 단위는 프로세스지만, `작업`의 단위는 스레드다(`고립`은 대게 `페이지 테이블`과 관련이 깊다). `고립`이라는 말은 먼저 `보안`적으로 굉장히 중요하다. 그리고, `고립`을 시킴으로써 프로세스가 마치 시스템의 모든 자원을 혼자 `독점`하고 있게끔 착각하게 만든다.
The unit of isolation in xv6 (as in other Unix operating systems) is a process. The process abstraction prevents one process from wrecking or spying on another process’s memory, CPU, file descriptors, etc. It also prevents a process from wrecking the kernel itself, so that a process can’t subvert the kernel’s isolation mechanisms. The kernel must implement the process abstraction with care because a buggy or malicious application may trick the kernel or hardware in doing something bad (e.g., circumventing enforced isolation). The mechanisms used by the kernel to implement processes include the user/kernel mode flag, address spaces, and time-slicing of threads.
To help enforce isolation, the process abstraction provides the illusion to a program that it has its own private machine. A process provides a program with what appears to be a private memory system, or address space, which other processes cannot read or write. A process also provides the program with what appears to be its own CPU to execute the program’s instructions.
Xv6 uses page tables (which are implemented by hardware) to give each process its own address space. The x86 page table translates (or ‘‘maps’’) a virtual address (the address that an x86 instruction manipulates) to a physical address (an address that the processor chip sends to main memory).
Xv6 maintains a separate page table for each process that defines that process’s address space. As illustrated in Figure 1-2, an address space includes the process’s user memory starting at virtual address zero. Instructions come first, followed by global variables, then the stack, and finally a ‘‘heap’’ area (for malloc) that the process can expand as needed.: 재미있는 건 이 2개의 개념은 모두 `페이지 테이블` 개념에서 나오게 된다. 각 프로세스는 자신만의 페이지 테이블을 가짐으로써 다른 프로세스의 메모리에 접근할 수 없게 된다. 그리고, 페이지 테이블의 `디맨딩 페이지` 기법을 통해서 자신이 혼자 시스템의 리소스를 모두 독점하고 있다는 착각에 빠지게 만든다(물론, 사실 이 기법은 `멀티 태스킹` 기법까지 추가되어야 한다).

: 각 프로세스가 가지고 있는 페이지 테이블은 커널 영역 뿐만 아니라, 유저 영역까지 매핑하고 있다. 예를 들어, 프로세스가 시스템 콜을 호출한다고 치자. 시스템 콜을 호출한 것이라면, 해당 프로세스는 유저 프로세스 일 것이다. 이 프로세스는 결국 커널 프로세스로 바뀌게 된다. 이 때, 프로세스의 페이지 테이블 매핑이 바뀌게 된다. 시스템 콜은 해당 프로세스의 커널 영역에서 실행된다.
`xv6` 커널에서 프로세스가 가지고 있는 정보 중 가장 중요시 여기는 3가지 정보가 있다. 바로 `페이지 테이블`, `프로세스 스택`, `프로세스 상태`다.
Each process’s address space maps the kernel’s instructions and data as well as the user program’s memory. When a process invokes a system call, the system call executes in the kernel mappings of the process’s address space. This arrangement exists so that the kernel’s system call code can directly refer to user memory. In order to leave plenty of room for user memory, xv6’s address spaces map the kernel at high addresses, starting at 0x80100000.
The xv6 kernel maintains many pieces of state for each process, which it gathers into a struct proc (2337). A process’s most important pieces of kernel state are its page table, its kernel stack, and its run state. We’ll use the notation p->xxx to refer to elements of the proc structure.: 각 프로세스는 여러 개의 `작업` 단위를 가지고 있다. 예를 들어, 서버 프로그래밍에서 서버는 여러 클라이언트들과 개별적인 채널을 가지고 통신을 한다. 이 때, 서버에서 각 클라이언트들에게 스레드(작업)를 하나씩 할당하게 된다. 이렇게 하면, 서버는 여러 클라이언트들과 마치 동시에 통신하는 것과 같은 효과를 들게 만든다. 즉, `멀티 태스킹`을 하는 것이다. 그런데, 이 스레드들도 개별적인 메모리를 가지고 있어야 한다. 왜냐면, 모든 클라이언트가 서로 다르기 때문에, 그에 대응하는 스레드도 각 클라이언트에 맞는 별도의 실행 흐름 및 데이터가 달라질 것이다. 그래서, 스레드마다 별도의 메모리 영역이 필요하다. 그게 바로 `스택`이다. 근데, 이건 누가 제공해주는 것인가? 이걸 제공해주는 주체가 `프로세스`다. 즉, 프로세스라는 큰 공간안에 여러 스레드가 살아가고 있는 것이다.
Each process has a thread of execution (or thread for short) that executes the process’s instructions. A thread can be suspended and later resumed. To switch transparently between processes, the kernel suspends the currently running thread and resumes another process’s thread. Much of the state of a thread (local variables, function call return addresses) is stored on the thread’s stacks. Each process has two stacks: a user stack and a kernel stack (p->kstack). When the process is executing user instructions, only its user stack is in use, and its kernel stack is empty. When the process enters the kernel (for a system call or interrupt), the kernel code executes on the process’s kernel stack; while a process is in the kernel, its user stack still contains saved data, but isn’t actively used. A process’s thread alternates between actively using its user stack and its kernel stack. The kernel stack is separate (and protected from user code) so that the kernel can execute even if a process has wrecked its user stack.
: 각 프로세스는 2개의 스택 영역을 갖는다.
유저 스택 영역" 프로세스가 유저 영역의 코드를 실행하면, 그 시점에는 유저 스택 영역만 사용한다.
커널 스택 영역" 시스템 콜 및 인터럽트로 인해 프로세스가 커널 모드로 바뀌면, 해당 프로세스의 커널 스택 영역만을 사용한다.: 이렇게 스택을 나누면 뭐가 좋을까? 운영 체제에서 `스택` 이라는 영역은 단순히 FILO 자료 구조를 의미하는게 아니다. `스택`은 현재 프로세스 및 스레드의 실행 상태를 나타낸다. 이 의미는 굉장히 중요하다. 위에서 프로세스안에 A, B스레드가 존재한다고 가정하자. 스택이 각 스레드마다 존재할 경우, A 스레드가 망가져도 B 스레드에는 영향을 주지 않게 된다.
: 유저 프로세스가 시스템 콜을 호출하면, 먼저 프로세서가 유저 스택을 커널 스택으로 스위치한다. 그리고, 권한 레벨을 변경(CPL3 -> CPL0)하고 시스템 콜을 처리하기 위해 해당 시스템 콜 엔트리 포인트로 점프한다. 그리고, 시스템 콜 처리가 완료되면 다시 유저 모드로 복귀해야 한다. 이 때, 권한 레벨을 다시 낮추고(CPL0 -> CPL3) 커널 스택을 다시 유저 스택으로 스위칭한다. 그리고, 시스템 콜 명령어를 실행했던 바로 이후에 명령어로 복귀한다.
When a process makes a system call, the processor switches to the kernel stack, raises the hardware privilege level, and starts executing the kernel instructions that implement the system call. When the system call completes, the kernel returns to user space: the hardware lowers its privilege level, switches back to the user stack, and resumes executing user instructions just after the system call instruction.
A process’s thread can ‘‘block’’ in the kernel to wait for I/O, and resume where it left off when the I/O has finished. `p->state` indicates whether the process is allocated, ready to run, running, waiting for I/O, or exiting. `p->pgdir` holds the process’s page table, in the format that the x86 hardware expects. xv6 causes the paging hardware to use a process’s `p->pgdir` when executing that process. A process’s page table also serves as the record of the addresses of the physical pages allocated to store the process’s memory: 부트 로더를 통해 0x8010_0000 이상으로 곧바로 로드하지 않는 이유와 0x8000_0000이 아닌, 0x8010_0000으로 로드하는 이유에 대해 설명한다. RAM에 여유가 없을 경우, 상위 절반을 사용할 수 없다는 내용과 [0xA0000:0x100000]은 BIOS에서 I/O 디바이스 관련하여 예약한 영역이라 0x8000_0000으로 곧바로 커널을 로드하지 못한다는 것이다.
When a PC powers on, it initializes itself and then loads a boot loader from disk into memory and executes it. Appendix B explains the details. Xv6’s boot loader loads the xv6 kernel from disk and executes it starting at entry (1044). The x86 paging hardware is not enabled when the kernel starts; virtual addresses map directly to physical addresses.
The boot loader loads the xv6 kernel into memory at physical address 0x100000. The reason it doesn’t load the kernel at 0x80100000, where the kernel expects to find its instructions and data, is that there may not be any physical memory at such a high address on a small machine. The reason it places the kernel at 0x100000 rather than 0x0 is because the address range 0xa0000:0x100000 contains I/O devices.: `xv6`는 프로세스의 고립에 대한 상당히 강조하는 것 같다. 프로세스의 고립은 가상 메모리 및 페이지 테이블과 관련이 깊다. 프로세스 생성 과정에 대해 설명하는 데, 상당히 구체적이다. 아래 내용에서 또 중요한 부분은 `allocproc`은 새로운 프로세스를 생성할 때마다 호출되지만, `userinit`은 첫 번째 프로세스를 생성할 때만 호출된다는 점이다.
Now we’ll look at how the kernel creates user-level processes and ensures that they are strongly isolated.
After main (1217) initializes several devices and subsystems, it creates the first process by calling userinit (2520). Userinit’s first action is to call allocproc. The job of allocproc (2473) is to allocate a slot (a struct proc) in the process table and to initialize the parts of the process’s state required for its kernel thread to execute. Allocproc is called for each new process, while userinit is called only for the very first process. Allocproc scans the proc table for a slot with state UNUSED (2480-2482). When it finds an unused slot, allocproc sets the state to EMBRYO to mark it as used and gives the process a unique pid (2469-2489). Next, it tries to allocate a kernel stack for the process’s kernel thread. If the memory allocation fails, allocproc changes the state back to UNUSED and returns zero to signal failure.1" 첫 번째 프로세스는 `userinit` 함수를 통해 생성된다. 이 함수안에서는 실제 프로세스 생성을 위해 `allocproc`을 호출한다.
2" `alloproc`은 `프로세스 테이블`에서 `UNUSED` 상태인 프로세스(struct proc)를 할당한다. 여기서 프로세스 테이블은 캐쉬같은 역할을 한다. 매번 프로세스를 생성할 때마다, FREE 메모리를 찾기 귀찮이므로 초기에 일정 크기의 메모리를 할당받아서 거기에 많은 프로세스들을 미리 만들어 놓는 것을 의미한다. 흔히 `프로세스 풀`이라고도 한다. 그리고 프로세스 테이블에 있는 프로세스들의 초기 상태는 `UNUSED`가 된다. 즉, 사용이 가능한 프로세스를 의미한다.
3" `allocproc`은 프로세스 테이블에서 사용 가능한 새로운 프로세스를 찾으면, 초기화를 진행한다. 초기화는 `UNUSED`를 `EMBRYO` 상태로 바꾸고, `PID`를 할당한다. 그리고 프로세스 고유의 스택 영역을 위해서 커널 스택의 일부를 할당한다.
4" 만약, 메모리 할당이 실패하면 프로세스의 상태를 `UNUSED`로 바꾸고 실패했다는 의미로 `0`를 리턴한다.
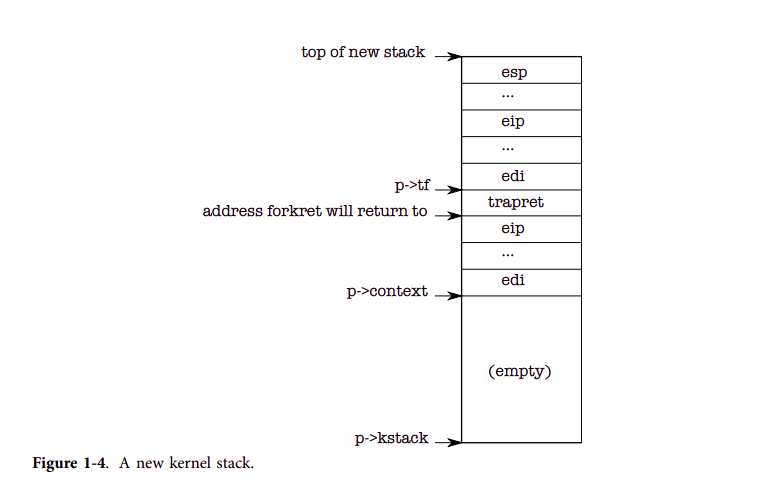
Now allocproc must set up the new process’s kernel stack. allocproc is written so that it can be used by fork as well as when creating the first process. allocproc sets up the new process with a specially prepared kernel stack and set of kernel registers that cause it to ‘‘return’’ to user space when it first runs. The layout of the prepared kernel stack will be as shown in Figure 1-4. allocproc does part of this work by setting up return program counter values that will cause the new process’s kernel thread to first execute in forkret and then in trapret (2507-2512). The kernel thread will start executing with register contents copied from p->context. Thus setting p- >context->eip to forkret will cause the kernel thread to execute at the start of forkret (2853). This function will return to whatever address is at the bottom of the stack. The context switch code (3059) sets the stack pointer to point just beyond the end of p->context. allocproc places p->context on the stack, and puts a pointer to trapret just above it; that is where forkret will return. trapret restores user registers from values stored at the top of the kernel stack and jumps into the process (3324). This setup is the same for ordinary fork and for creating the first process, though in the latter case the process will start executing at user-space location zero rather than at a return from fork.
: `xv6`에서 새로운 프로세스가 생성되면, 그 프로세스는 무조건 유저 영역까지 가게된다. 그 이유는 `forkret`과 `trapret` 함수 때문이다. `xv6`의 모든 프로세스는 `forkret`이 실행된 후 반한되면 자동으로 `trapret`이 실행되는 구조를 가지고 있다. `trapret`은 커널에서 생성된 프로세스가 유저 프로세스로 가기까지의 과정이 된다.
: 스택은 위에서 아래로 내려오는 구조이므로, 시작 주소를 `top of new stack`으로 보고 스택의 LIMIT을 `p->stack`으로 보는 것이 맞다. 나중에 `프로세스 파트`에서 보겠지만, 아래에서 보이는 프로세스의 스택 영역은 말 그대로 새로 생성된 프로세스의 스택을 말한다. 그러나, 프로세스가 실행되다 보면 스택에 여러 가지 데이터가 쌓인다. 그래서 아래의 `trapframe`, `trapret`, `context` 가 저장되는 순서 및 포맷은 지켜지지만, 무조건 스택의 TOP에 위치하지는 않게된다.
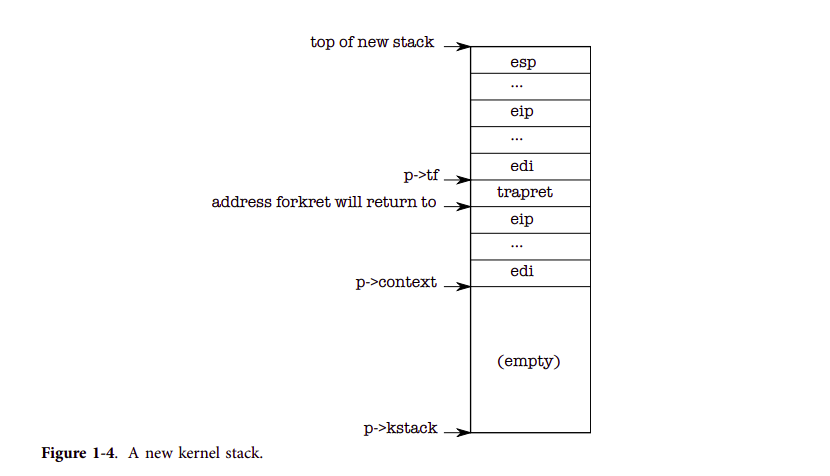
: 위의 그림을 이해하려면, `allocproc` 함수에서 프로세스 스택 레이아웃을 어떻게 설정하는지 알아야 한다. `xv6`의 프로세스 생성은 `allocproc`이 담당한다. 이 함수의 핵심은 프로세스의 스택 설정을 어떻게 하냐이다. 일단 제일 먼저 `kalloc`을 통해 4096B 사이즈의 스택을 할당받는다. 성공하면, `p->kstack`에는 프로세스의 스택 시자 주소가 할당받게 된다. 그리고 `sp = p->stack + KSTACKSIZE`를 통해서 sp 변수가 스택의 끝 부분을 가리키도록 한다. 그리고 순서대로 `trapframe`, `trapret`, `context` 영역을 할당한다.
//PAGEBREAK: 32
// Look in the process table for an UNUSED proc.
// If found, change state to EMBRYO and initialize
// state required to run in the kernel.
// Otherwise return 0.
static struct proc*
allocproc(void)
{
struct proc *p;
char *sp;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == UNUSED)
goto found;
release(&ptable.lock);
return 0;
found:
p->state = EMBRYO;
p->pid = nextpid++;
release(&ptable.lock);
// Allocate kernel stack.
if((p->kstack = kalloc()) == 0){
p->state = UNUSED;
return 0;
}
sp = p->kstack + KSTACKSIZE;
// Leave room for trap frame.
sp -= sizeof *p->tf;
p->tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp -= 4;
*(uint*)sp = (uint)trapret;
sp -= sizeof *p->context;
p->context = (struct context*)sp;
memset(p->context, 0, sizeof *p->context);
p->context->eip = (uint)forkret;
return p;
}: `allocproc`은 프로세스의 스택을 모두 설정한 후에, `p->context->eip` 에 `forkret` 함수를 설정한다. 즉, 모든 프로세스는 스케줄러에 의해서 실행되면 제일 먼저 실행되는 함수가 무조건 `forkret` 이라는 함수가 된다. `forkret` 함수는 다음과 같다.
// A fork child's very first scheduling by scheduler()
// will swtch here. "Return" to user space.
void forkret(void)
{
static int first = 1;
// Still holding ptable.lock from scheduler.
release(&ptable.lock);
if (first) {
// Some initialization functions must be run in the context
// of a regular process (e.g., they call sleep), and thus cannot
// be run from main().
first = 0;
iinit(ROOTDEV);
initlog(ROOTDEV);
}
// Return to "caller", actually trapret (see allocproc).
}: 첫 번째로 생성된 프로세스만이 `iinit`과 `initlog`를 호출한다. (`iinit`과 `initlong`는 이 글을 참고하자) 다른 프로세스들은 `forkret`에서 아무것도 하지 않고, 바로 반환을 하게된다. 그런데, 이 부분이 굉장히 중요하다. `xv6`에서 프로세스 스택 구조를 다시 보면, `eip` 위에 존재하는 값은 `trapret`이다. 즉, `xv6`에서 생성된 모든 프로세스들은 `forkret` 함수가 반환되면 무조건 `trapret`의 진입점으로 가게 되어있다. `forkret`를 실행시키는 원리는 `eip`를 바꾸는 것이지, 함수 호출이 아니기 때문에 x86의 함수 호출 규약인 `cdecl`을 따를 필요가 없다.
#include "mmu.h"
# vectors.S sends all traps here.
.globl alltraps
alltraps:
# Build trap frame.
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# Set up data segments.
movw $(SEG_KDATA<<3), %ax
movw %ax, %ds
movw %ax, %es
# Call trap(tf), where tf=%esp
pushl %esp
call trap
addl $4, %esp
# Return falls through to trapret...
.globl trapret
trapret:
popal
popl %gs
popl %fs
popl %es
popl %ds
addl $0x8, %esp # trapno and errcode
iret: `trapret` 심볼이 실행되는 원리는 알려면, 먼저
: 유저 모드 소프트웨어가 커널 모드로 전환하는 방법은 3가지가 있다 : `시스템 콜`, `인터럽트`, `익셉션`. 유저 모드에서 커널 모드로 전환되면, 프로세서 및 `xv6`는 커널 프로세스의 스택에 시스템 콜을 요청한 유저 프로세스의 컨택스트 정보들을 저장한다.
As we will see in Chapter 3, the way that control transfers from user software to the kernel is via an interrupt mechanism, which is used by system calls, interrupts, and exceptions. Whenever control transfers into the kernel while a process is running, the hardware and xv6 trap entry code save user registers on the process’s kernel stack.
userinit writes values at the top of the new stack that look just like those that would be there if the process had entered the kernel via an interrupt (2533-2539), so that the ordinary code for returning from the kernel back to the process’s user code will work. These values are a struct trapframe which stores the user registers. Now the new process’s kernel stack is completely prepared as shown in Figure 1-4.: 위에 `userinit write values at ...` 내용은 실제 `userinit` 함수를 봐야 이해할 수 있다. 초기에 `allocproc`을 통해 프로세스를 하나 할당받고, `setupkvm`을 통해 프로세스 페이지 테이블을 할당받는다. 그리고 나서 `p->tf->XXXX` 관련 코드들이 `userinit write values at ...` 부분에서 말하는 내용이다. `tf`가 trapframe을 의미하는데, trapframe은 각 프로세스 스택에 가장 높은 곳(`p->kstack + KSTACKSIZE`)에 저장되기 때문이다. 중요한 건, 최초의 프로세스라고 해도 유저 레벨 프로세스이다 보니 권한을 전부 `유저 권한`을 주고 있는 것에 주목하자.
//PAGEBREAK: 32
// Set up first user process.
void
userinit(void)
{
struct proc *p;
extern char _binary_initcode_start[], _binary_initcode_size[];
p = allocproc();
initproc = p;
if((p->pgdir = setupkvm()) == 0)
panic("userinit: out of memory?");
inituvm(p->pgdir, _binary_initcode_start, (int)_binary_initcode_size);
p->sz = PGSIZE;
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;
p->tf->eip = 0; // beginning of initcode.S
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
}: 그리고 눈 여겨볼 점은 `allocporc`에서 할당된 프로세스는 `struct context`에 eip가 있고, 와 `userinit`에서 할당된 프로세스는 `struct context`와 `struct trapframe` 2개의 구조체 모두에 eip가 존재한다. 그 의미는 다음과 같다.
1" struct context : eip - `xv6`에서 스케줄러의 의해서 컨택스트 스위칭이 발생하면, struct context의 eip 변수를 사용해서 어디서부터 프로세스를 실행시킬 지 결정한다.
2" struct trapframe : eip - 인터럽트 및 트랩이 발생하면(타이머 제외), 이전 흐름으로 복귀하기 위해서 struct trapframe의 eip 변수를 사용한다.: 그러면, `userinit`에 `p->tf->eip = 0`은 무슨 뜻일까? 최초의 유저 프로세스인 `initproc`은 0번지를 실행하게 된다. 그 0 번지의 내용은 `initcode.S`에 들어있다.
: `initcode.S` 부터는 링커가 나오기 시작하면서 조금 복잡하다.
The first process is going to execute a small program (initcode.S; (8400)). The process needs physical memory in which to store this program, the program needs to be copied to that memory, and the process needs a page table that maps user-space addresses to that memory
userinit calls setupkvm (1818) to create a page table for the process with (at first) mappings only for memory that the kernel uses. We will study this function in detail in Chapter 2, but at a high level setupkvm and userinit create an address space as shown in Figure 1-2.
The initial contents of the first process’s user-space memory are the compiled form of initcode.S; as part of the kernel build process, the linker embeds that binary in the kernel and defines two special symbols, _binary_initcode_start and _binary_initcode_size, indicating the location and size of the binary. Userinit copies that binary into the new process’s memory by calling inituvm, which allocates one page of physical memory, maps virtual address zero to that memory, and copies the binary to that page (1886).: 아래는 `xv6 makfile`의 파일의 내용이다. `initcode` 타겟을 보면, initcode.S 파일을 입력 파일로 받는 것이 보인다. 그리고 링커를 통해 `-Ttext 0`을 주고 있는데, 이건 해당 파일을 text 섹션의 시작 주소를 `0`으로 잡는다는 얘기다. 링커는 기본 주소를 VMA로 인식하기 때문에 페이징이 처리되더라도 저 텍스트 섹션은 0번지에 위치하게 된다. 그리고 `-e start`를 통해서 initcode.S 안에 `start` 심볼을 엔트리 포인트로 잡았다. 그래서 위에서 최초 유저 스페이스 프로세스의 시작 코드가 initcode.S라고 하고 있다. 이건 커널 빌드 프로세스에 결정된다는 내용도 있다.
...
...
entryother: entryother.S
$(CC) $(CFLAGS) -fno-pic -nostdinc -I. -c entryother.S
$(LD) $(LDFLAGS) -N -e start -Ttext 0x7000 -o bootblockother.o entryother.o
$(OBJCOPY) -S -O binary -j .text bootblockother.o entryother
$(OBJDUMP) -S bootblockother.o > entryother.asm
initcode: initcode.S
$(CC) $(CFLAGS) -nostdinc -I. -c initcode.S
$(LD) $(LDFLAGS) -N -e start -Ttext 0 -o initcode.out initcode.o
$(OBJCOPY) -S -O binary initcode.out initcode
$(OBJDUMP) -S initcode.o > initcode.asm
kernel: $(OBJS) entry.o entryother initcode kernel.ld
$(LD) $(LDFLAGS) -T kernel.ld -o kernel entry.o $(OBJS) -b binary initcode entryother
$(OBJDUMP) -S kernel > kernel.asm
$(OBJDUMP) -t kernel | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > kernel.sym
...
...: 문제는 `_binary_initcode_start`과 `_binary_initcode_size`가 도대체 어디에 선언되어 있느냐 인데, 이건 `objcopy` 툴을 통해서 생성된다.
-B bfdarch
--binary-architecture=bfdarch
Useful when transforming a raw binary input file into an object file. In this case the output architecture can be set to bfdarch. This option will be ignored if the input file has a known bfdarch. You can access this binary data inside a program by referencing the special symbols that are created by the conversion process. These symbols are called _binary_objfile_start, _binary_objfile_end and _binary_objfile_size. e.g. you can transform a picture file into an object file and then access it in your code using these symbols.
- 참고 : https://sourceware.org/binutils/docs-2.18/binutils/objcopy.html: 그리고 `kernel` 타겟에서 링커에 `-b` 옵션을 준 것을 확인해야 한다.
-b input-format
--format=input-format
ld may be configured to support more than one kind of object file. If your ld is configured this way, you can use the `-b' option to specify the binary format for input object files that follow this option on the command line. Even when ld is configured to support alternative object formats, you don't usually need to specify this, as ld should be configured to expect as a default input format the most usual format on each machine. input-format is a text string, the name of a particular format supported by the BFD libraries. (You can list the available binary formats with `objdump -i'.) See section BFD. You may want to use this option if you are linking files with an unusual binary format. You can also use `-b' to switch formats explicitly (when linking object files of different formats), by including `-b input-format' before each group of object files in a particular format. The default format is taken from the environment variable GNUTARGET. See section Environment Variables. You can also define the input format from a script, using the command TARGET; see section Option Commands.
- 참고 : https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_node/ld_3.html#SEC3'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
AT & T 문법 (0) 2023.07.15 xv6 - System Call & Traps (0) 2023.07.12 [xv6] Page tables 상세 분석 1 (0) 2023.07.12 TSS (0) 2023.07.06 [x86] Unreal mode (0) 2023.06.28