" 리눅스 커널은 왜 `high-resolution timer` 를 도입했을까? 가장 큰 이유는 `정확성` 때문이다. 성능이 아무리 좋은 타이머 하드웨어가 있더라도, tick 기반으로 동작하면 정확성이 좋을 수 가 없다. 예를 들어, 10Mhz, 500Mhz 로 동작하는 타이머가 있다고 치자. 직관적으로 500Mhz timer 가 10Mhz timer 보다 더 정확성이 좋다는 것을 알 수 있다. 그러나, 리눅스 커널에서 tick 을 기반으로 2 개의 timers 를 사용할 경우, 성능의 차이가 사라진다(참고로, HZ 를 100 으로 설정하면, 1초에 100 번 tick 이 발생한다는 것을 의미한다. 이것은 시간 10ms 에 한 번 tick 이 발생했다는 뜻이다).
" 그런데, 사실 500Mhz 타이머 같은 경우는 1 초에 `1,000,000(1Mhz) * 500` 번의 주파수를 발생시킬 수 있다. 즉, 1 초에 500,000,000 번의 tick 을 발생시킬 수 있다. 10Mhz 같은 경우도, 1 초에 `1,000,000(1Mhz) * 10` 번의 tick 을 발생시킬 수 있다. 이렇게 좋은 성능을 가진 timers 들을 10ms 에 한 번 tick 을 발생시키게 하면, 하드웨어 고유의 성능을 제대로 사용하지 못하고 있다는 뜻이다(좀 더 구체적으로 설명하면, counter register 에 특정 값을 부여해서 10ms 에 한 번 tick 이 발생하도록 하는 것은 성능 및 정확서을 버리는 것이라고 볼 수 있다).물론, tick 을 기반으로 하면, 하드웨어에 의존하지 않기 때문에 호환성이 좋지만, 기술의 발전을 무시하는 것과 같은 행위다.
" high-resolution framework 은 nano-second 단위 까지의 정확성을 보장해준다(ns 보다 더 빠른 시간은 지원하지 않는다 - 32 비트 한계). hrtimer 가 무조건 nano-second 만 지원한다는 소리는 아니다. milli-second 단위도 지원하며, nano-second 를 지원한다기 보다는 nano-second 까지 지원한다는 소리다. 그리고, hrtimer 는 milli-second 이상의 정확도를 위해서 사용하는 timer 다. 좀 더, 엄밀히 말하면, one-shot mode 를 지원하면 hrtimer 라고 부를 수 있고, 물리적인 timer hardware 가 milli-second 만 까지만 지원하더라도, hardware 적으로 one-shot mode 를 지원한다면, 해당 timer hardware 를 통해 hrtimer 서비스를 이용할 수 가 있다. 참고로, 32-bit CPU 에서는 nano-second 를 저장하기 위해서 unsigned int 사용했다. unsigned int 는 43 억까지 저장할 수 있으며, nano-second 로 단위로 tick 이 발생할 경우, unsigned int 로 43 초 까지는 표현이 가능하다. 64-bit CPU 에서 nano-second 단위로 tick 이 발생하더라도, 64-bit 데이터 타입의 overflow 를 야기하려면, 꾀나 오랜 시간이 걸리게 된다. 그러나, time clock 은 clock source 에서 발생하는 clock speed 로 결정되며, embedded 에서 사용되는 일반적인 clock source 의 clock speed 는 GHz 를 넘지 않기 때문에, unsigned int 만으로도
" 현재 대부분의 타이머에는 2개의 모드가 존재한다.
1. periodic mode 2. one-shot mode
" one-shot mode 는 단발성 타이머 인터럽트로 한 번 발생하면 끝인 타이머다. 만약, 다시 타이머 인터럽트를 발생시키고 싶다면, 반드시 재장전을 해야한다. 멀티 프로세서가 등장하면서, jiffies 를 유지하기 위해 모든 프로세서에게 period mode 를 할 필요는 없어졌다. 하나의 CPU 만 period mode 로 동작하면서, jiffies 유지시키면 됬기 때문이다.(jiffies 가 전역 변수이기 때문에, synchronization 을 위해 하나의 CPU 에서만 access 하도록 한다). 문제는 정확한 시점에 타이머 서비스를 제공받기를 원했으며, 정확성이 요구되는 새로운 타이머가 필요했다. 그러나, 이미 하드웨어는 높은 정확성을 갖추고 있었다. 문제는 소프트웨어였다. 소프트웨어가 milli-second 를 기반으로 하는 tick 을 사용하다보니 오차가 발생했다. 그래서, tick 을 기반으로 하지 않고(ms 단위의 타이머가 아닌), us 및 ns 단위의 on-demand 타이머가 등장했다. 그게 바로, `hrtimer` 다. 아래 그림을 보면 알 수 있다시피, hrtimer 은 tick 기반으로 하지 않고, nano-second 를 사용하기 때문에 불규칙적이면서 정확하다.
" 위에 그림을 보면, 빨깐색 화살표는 high-resolution timer service 이며, 검은색 화살표는 low-resolution timer service 를 의미한다. low-resolution timer service 는 10ms 간격으로 주기적으로 tick 이 발생하는 것을 알 수 있다. 그러나, 15ms 에는 tick 을 발생시킬 수 없다. high-resolution timer service 는 최대 1ns 까지 timer service 를 제공한다. 그래서, low-resolution timer service 에서 제공해주지 못했던 15ms 에서 timer service 를 제공할 수 도 있다. 심지어, 15us 및 15ns 에서도 timer service 를 제공받을 수 있다.
- Relationship between hrtimer and cpuidle
" 뜬금없이 hrtimer 과 CPUidle 의 관계를 왜 얘기할까? hrtimer 는 CPUidle 여부에 따라 동작이 달라지기 때문이다.
1. CPU 가 IDLE 상태인 경우 - hrtimer 는 dyntick mode 로 동작한다. 2. CPU 가 IDLE 상태가 아닌 경우 - hrtimer 는 periodic mode 로 동작한다.
" hrtimer 을 사용한다는 것은 기본적으로 hardware level 에서 one-shot mode 를 지원한다는 것을 의미한다. 이 말은, hardware 에서 one-shot mode 를 지원하지 않을 경우, 리눅스 커널의 hrtimer subsystem 은 사용할 수 없다는 뜻이다. 여기서 궁금한 건 CPU 가 IDLE 상태일 때다. dyntick 이란게 뭘까? 쉽게 필요할 때만 타이머 서비스를 이용하겠다는 뜻이다. 이 말은 기존 timekeeping subsystem(periodic mode) 에서는 timer service 가 필요하지 않을 때도, 강제적으로 timer interrupt 가 발생시켰지만, hrtimer subsystem 에서는 CPU 가 IDLE 상태인 경우, 필요할 때만 timer service 를 받겠다는 뜻이다. 그러나, `역` 은 성립하지 않는다. 즉, 필요할 때만 timer service 를 받겠다고 해서 CPU 가 IDLE 상태로 들어가는 것은 아니다. 즉, dyntick mode 는 반드시 CPU 가 IDLE 상태로 진입해야 함을 전제로 한다.
" 기존 regular kernel timers(milliseconds 만 지원) 들과는 다르게, hrtimers 는 microseconds(us) or nanoseconds(ns) 단위의 period timer service 에서 사용된다. 그리고, hrtimers 는 구체적인 특정 시점이 아닌, 구간 or 범위내에 timer interrupt 를 받아 wakeup 할 수 있는 기능이 있다. 리눅스 커널은 이러한 hrtimers 를 `range hrtiemrs` 이라고 한다. range hrtimers 는 2 종류의 expiration time 을 제공한다.
1. soft expiration time(earliest) 2. hard expiration time(latest)
" range hrtimers 를 사용하면, 커널은 동일 범위내에 있는 hrtimer services(wakeup events) 를 하나의 hrtimer service 로 합쳐서, interrupt 의 발생 횟수를 줄일 수 있다. wake-up interrupt 가 줄어들면 당연히 powr saving 효과를 누릴 수 가 있다. range hrtimer 가 도입되면서 hrtimers 종류가 또한 2 종류로 나뉘게 되었다.
1. normal hrtimer - soft expiration time == hard expiration time 2. range hrtimer - soft expiration time + hard expiration time(delay & slack)
" soft expiration time & hard expiration time 이 같을 경우, 특정 시점에 timer service 를 제공받게 된다. 만약, 다르다면, soft expiration time 을 시작 포인트로 delay(hard expiration time) 범위 안에서 언제든 timer serviec 를 받을 수 있다는 것이다. 예를 들어, range hrtimer A 에 soft expiration time 이 10us 고 hard expiration time 이 5us 라면, range hrtimer A 는 10us ~ 15us 안에 언제든 timer service 를 받을 수 있다는 뜻이 된다.
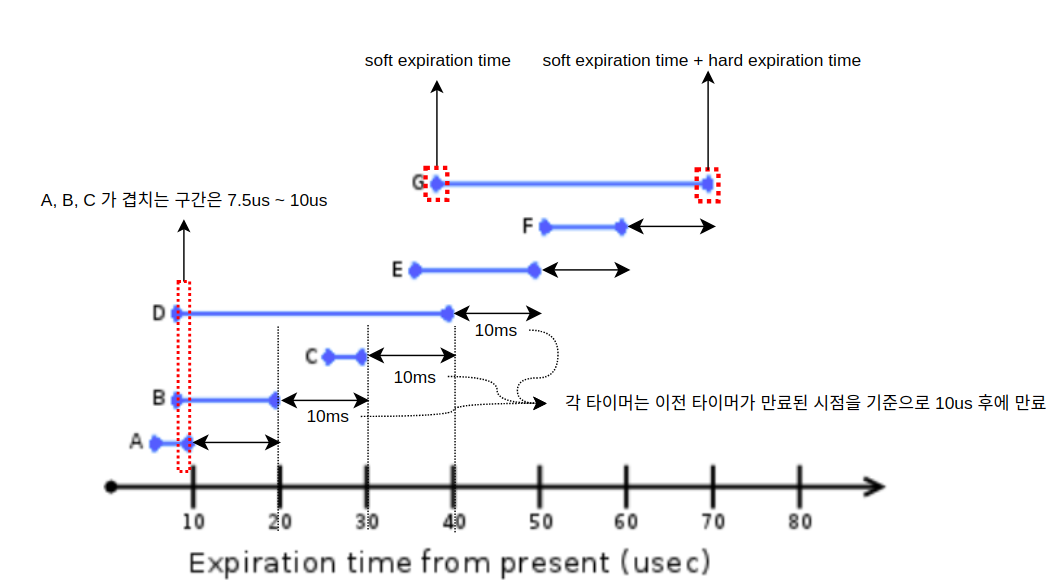
" 예시를 들어보자. 시스템에 A ~ G 타이머가 존재한다고 가정하자. 이 때, 각 타이머는 이전 타이머가 만료된 시점을 기준으로 10us 후에 만료된다고 가정하자. 즉, A 가 10us 에 만료되면, B는 20us 에서 만료된다. 위 그림에서는 hard expiration time 은 규칙적이지만, soft expiration time 는 각기 다름을 알 수 있다.
" A 의 hard expiration time 은 10us 이지만, 5us 이후 부터는 언제든 만료될 수 있다. 즉, 5us ~ 10us 사이에서 언제든 만료될 수 있다. B 는 hard expiration time 는 20us 이지만, 7.5us 이후 부터는 언제든 만료될 수 있다. 즉, 7.5us ~ 20us 사이에서 언제든 만료될 수 있다. 이럴 때, 커널은 A 와 B 가 겹치는 7.5us ~ 10us 사이에서 둘 모두를 만료시킨다. 그러므로, B 같은 20us 에서 timer interrupt 를 발생시킬 필요성이 없어진다.
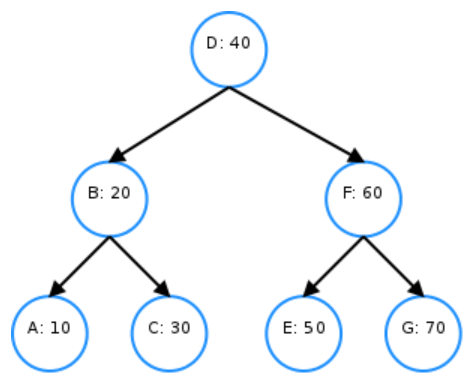
" 그리고, 잘 보면 D 또한, 7.5us ~ 40us 사이에서 언제든 만료될 수 있다. 그렇다면, 커널은 A, B, C의 공통 부분은 7.5us ~ 10us 사이에서 A, B, C 를 모두 만료시킬 수 있다. 예를 들어, 10us 에서 hardware time interrupt 가 발생하면, A, B, C timers 들에 설정된 timer interrupt handlers 들을 호출할 수 있다. 그러나, 사실 D 는 이 시점에 expiration function 이 호출되지 않는다. 그 이유를 알려면, 타이머 인터럽트가 발생했을 때, red-black tree 에서 어떻게 hrtimer 를 searching 하는지를 알아야 한다. 아래 red-black tree 는 hrtimer 들이 hard expiration time 을 key 로 설정하고 저장되는 구조이다.
" 10us 후에 커널에 timer interrupt 발생하면, 리눅스 커널의 hrtimer 코드는 DFS(Depth-first searching) 알고리즘을 통해서 soft expiration time 이 지난 hrtimers 들을 찾는다. DFS 를 사용하기 때문에, 일단 제일 왼쪽 아래 노드를 만날 때 까지 탐색을 진행한다. 즉, A 를 만날 때 까지 다른 노드들은 검사하지 않고 그냥 지나간다. A 가 leaf node 이기 때문에, 여기서 부터 검사를 진행한다. hrtimer 가 red-black tree 에 저장되는 구조는 다음과 같다.
1. 왼쪽 노드가 오른쪽 노드보다 더 빠른 hard expiration time 을 갖는다.
" 이제 위에 시나리오를 다시 가져와 보자. 10us 에서 타이머 인터럽트가 발생하면, 리눅스 커널은 트리를 탐색한다. 이 때, A 와 B 는 동일한 딜레이 구간(7.5us ~ 10us)를 가지고 있기 때문에, 리눅스 커널은 이 둘을 하나로 묶어서 처리할 계획을 한다. 그리고, 또 묶을 수 있는 타이머가 있는지를 탐색한다. 그리고, C 를 발견하게 된다. 그런데, C 는 7.5us ~ 10us 구간에 묶일 수 없는 타이머다. hrtimers tree 에서는 노드가 왼쪽에 있을 수 록, 더 빨리 expired 된다는 것을 전제하기 때문에 더 이상 묶을 수 이는 타이머가 없다고 생각하고 탐색을 종료한다. 그런데, 사실 D 가 여기에 묶일 수 있다. 이와 같은 구조에서는 전체를 탐색하지 않는 이상 D 와 같은 타이머들을 찾기가 어렵다. 즉, 이 구조에서는 C 노드에서 탐색을 종료하기 때문에(D(40us) 는 C(30us) 보다는 뒤에 expire 된다) C 탐색 이후에 D 를 검사하지 않게 된다.
" 가장 쉽게 생각해 볼 수 있는 방법은 뭐가 있을까? soft expiration time 기반으로 만들어진 red-black tree 를 만드는게 가장 먼저 떠오른다. 그런데, 기존에 hard expiration time 트리가 변경되면, soft expiration time 트리도 변경해야 할 것이다. 이렇면, 오버 헤드가 너무 커진다.
" 일반적인 red-black tree 는 key 를 중심으로 동작한다. 즉, 각 노드가 개별적으로 구분되어 있다. 그런데, 우리가 알아볼 slack range 를 위해서는 각 노드를 구분하기 보다는 비슷한 범위에 있는 노드를 하나의 그룹에 묶을 수 있어야 한다. 그래서, Venkatesh 는 `greedy hrtimer walk` 라는 제목의 patch 를 커널에 적용했고, 이 patch 는 기존 red-black tree 를 `augmented red-black tree` 로 변경시켰다. augmented red-black tree 는 2가지 특징을 가지고 있다.
1. 각 노드에는 key 값과 별개로 extra metadata 가 저장된다. 2. 트리가 변경될 때 마다, 하위 노드의 extra metadata 가 상위 노드로 전파된다.
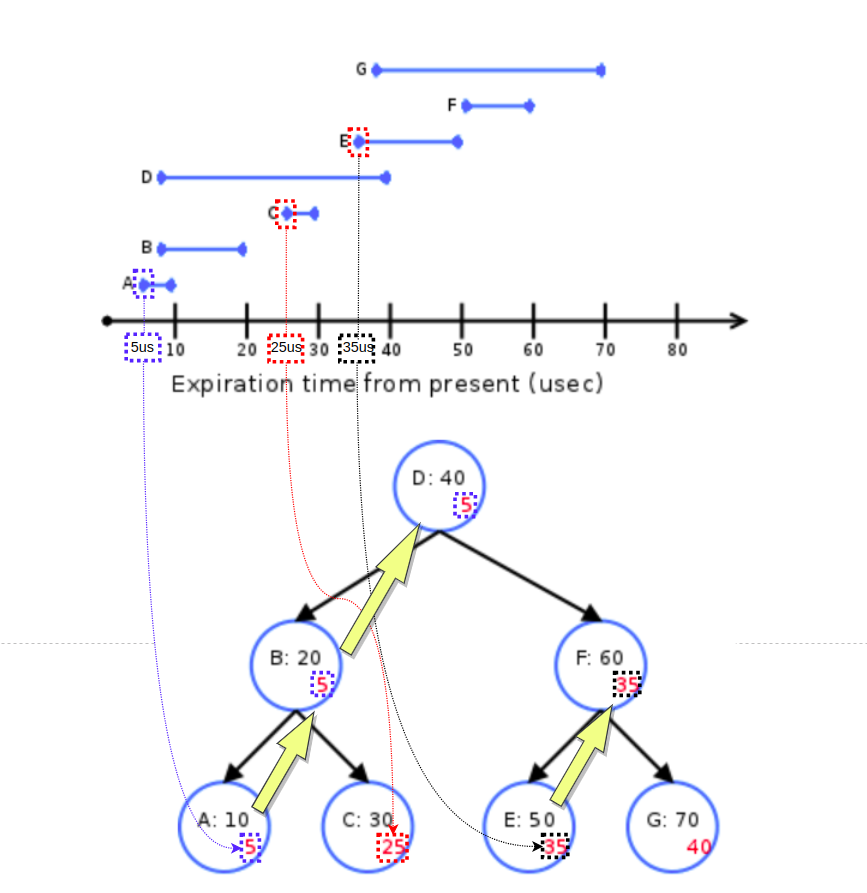
" hrtimer 의 각 노드에 저장되는 extra metadata 는 자신이 속한 서브 트리에서 earliest soft expiration time 을 저장한다.
" 위 트리에서 각 노드의 빨간색 번호는 각 서브 트리의 soonest soft-expiration time 를 의미한다. 예를 들어, D 의 서브 트리에는 A, B, C, D, E, F, G 가 포함된다. 여기서 soonest soft-expiration time 은 A 의 soft-expiration time 이 된다. 그러므로, D 의 extra metadata 는 5 가 된다. B 의 서브 트리에는 A, B, C 가 포함된다. 여기서 soonest soft-expiration time 은 A 의 soft-expiration time(5us) 이 된다. 그러므로, B 또한 extra metadata 는 5 가 된다. F 의 서브 트리에는 E, F, G 가 포함된다. 여기서 soonest soft-expiration time 은 E 의 soft-expiration time 이 된다. 그러므로, F 의 extra metadata 는 35 가 된다. leaf node 들의 soonest soft-expiration time 은 자기 자신의 soonest soft-expiration time 를 갖는다(위 예시에서 leaf node 는 A, C ,E G).
" augmented red-black tree 를 사용할 경우,10us 후에 커널에 timer interrupt 발생한다고 가정했을 때, 탐색은 `F` 에서 끝이난다. 왜냐면, F 노드가 이루는 sub-tree 의 모든 soft expiration times 들은 최소 25us 보다 더 뒤에 발생할 것이기 때문이다. 이렇게 augmented red-black tree 를 사용하면, 오른쪽 sub-tree 를 검색하는 비용을 줄일 수 가 있다.
" C-libary 에는 `sleep()` 이라는 함수가 있다. 이 함수를 호출한 process 는 sleep() 함수에 명시한 seconds 만큼 sleep 을 하게 된다. 그런데, sleep() 함수를 사용할 때, 인자로 `0` 을 전달하는 이상한 코드들이 있다. 왜 이런짓을 하는것일까? user application 에서 이 코드를 사용하는 이유는 kernel space 와는 다르게, user space 에서는 process context switching 을 직접적으로 발생시킬 수 없기 때문이다. 즉, sleep(0) 을 사용하면, 해당 user application 에서 CPU 를 잠깐 동안 반납할 수 있다. user application 에서 이러한 발상은 굉장히 좋은 코딩 방식이다. 특히나, 전반적인 system performance 를 위해서 polling 을 사용하거나 CPU 를 너무 오래 소유하는 applications 들은 반드시 `zero-second sleep` 방식을 사용해서 다른 processes 들에게 CPU 를 양보할 필요가 있다.
" 리눅스에서 sleep(0) 는 항상 process 를 one clock tick 이상 동안 sleep state 로 유지시킨다. 그런데, hrtimers 가 커널에 도입되면서, 동작이 약간 바뀌었다. process 에서 hrtimer 을 기반으로한 sleep(0) 을 호출할 경우, 즉각적으로 리턴해버린다. 즉, process 가 sleep 에 빠지지 않는다는 것이다. 어떻게 하면, hrtimer 을 기반으로한 sleep(0) 을 이전과 유사한 동작으로 사용할 수 있을까? hrtimer 의 time slack 을 사용하는 것이다. time slack 이란 sleep periods 를 확장해서 다수의 processes 들이 동시에 timer interrupt(wake-up) 를 받게하는 테크닉이다. hrtimer 는 nano-second 단위로 동작하기 때문이다. hrtimer 에서 soft expiration time 과 hard expiration time 이 같을 경우, range 가 없기 때문에 sleep(0) 을 사용하면 즉각적으로 반환될 것이다. 그래서, soft expiration time 과 hard expiration time 에 서로 다른 값을 할당해서 range 를 형성하면, sleep(0) 을 호출하더라도 즉각적으로 반환되는 것을 막을 수 있다.
" default time slack 은 50us 다. 사실, 이 값은 대부분의 applications 에서 인지할 수 있는 변화는 아니다. 왜냐면, tick 은 sleep(0) 이 milliseconds 단위로 동작을 했는데, hrtimer 는 microseconds 이다 보니, 이게 sleep 에 들어간 것인지 아닌지를 인식하지 못한다. 그러나, 일부 시스템에서는 power saving 을 위해서 time slack 을 초 단위로 까지 설정하는 경우도 있다. 그러나, power saving 만 생각해서, time slack 을 초 단위로 늘리면, applications 들이 정상적으로 동작하지 않을 확률이 매우 높기 때문에, 주의가 필요하다.