-
[리눅스 커널] PM QoS - CPU latency QoS frameworkLinux/kernel 2023. 9. 11. 13:22
글의 참고
- https://docs.kernel.org/power/pm_qos_interface.html
- https://docs.kernel.org/admin-guide/pm/cpuidle.html
- https://lwn.net/Articles/384146/
- https://medium.com/@divy.jain6200/cpu-latency-and-approaches-to-minimize-cpu-latency-80ae14aa118c
- https://zhuanlan.zhihu.com/p/561000691
- https://access.redhat.com/articles/65410
- http://www.wowotech.net/pm_subsystem/pm_qos_overview.html
- https://blog.csdn.net/feelabclihu/article/details/116810959
- https://www.cnblogs.com/linhaostudy/p/17068712.html
- https://blog.csdn.net/xiezhi123456/article/details/80623330
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- PM QoS
: `QoS`는 `Quality Of Service`의 약자로 `좋은 품질`로 해석할 수 있다. 여기서 `좋은 품질`이란 무엇을 의미할까? 일반적으로, 소비 전력과 성능은 반비례한다. 즉, 소비 전력이 좋으면 성능이 않좋고, 성능이 좋으면 소비 전력이 좋지 않다. 그러나, 사용자들에게 중요한 부분은 `성능`과 관련이 깊다. 그래서, 먼저 파워가 성능에 어떤 영향을 미치는지 부터 알아보자. 크게 2가지가 있다.
1. Recovery latency(time overhead) : 시스템이 절전 모드 상태에서 풀-파워 모드로 전환하는 과정에서 `오버헤드`가 발생한다. 심지어, 시스템 절전 모드가 아니라, `Power-Off` 라면 더 큰 `오버헤드`가 따른다. 일반적으로, 시스템이 더 강한 절전 모드가 될 수록, 더 많은 `Recovery Latency`가 발생한다.
2. Lower power supply(performance overhead) : 낮은 전력 공급은 결과적으로 낮은 퍼포먼스와 낮은 네트워크 스루풋을 유발한다. DVFS가 전형적인 예시가 된다.: 위와 같이 2가지 문제로 인해 시스템 전체에 응답성이 저하되면서, 결국 사용자의 실시간 요구에 제대로 대응하지 못하는 결과를 초래하게 된다. 위의 문제들이 발생하는 이유가 뭘까? `Low Power Mode(LPM)` 로 진입할 조건이 되면, 즉각적으로 들어가 버리기 때문이다. `PM QoS`는 여기서 등장한다. 즉, `LPM`으로 들어갈 조건이 되더라도, 즉각적으로 진입하지 않고 요구 조건 및 제약 사항이 모두 충족될 때만, `LPM`으로 들어가는 것이다. 이게 `PM QoS`가 하는 일이다.
The power management quality of service (PM QoS) framework in the Linux kernel allows kernel code and user space processes to set constraints on various energy-efficiency features of the kernel to prevent performance from dropping below a required level.
- 참고 : https://docs.kernel.org/admin-guide/pm/cpuidle.html: 리눅스 커널에서는 크게 2가지 `Power Management` 관리 기법이 존재한다(`System` vs `Device`). PM QoS 또한 이에 대응하여 2가지 프레임워크가 존재한다. 이 글에서는 `CPU latency QoS framework` 대해서만 다룬다.
1. CPU latency QoS framework : 시스템 레벨에서 발생하는 `Latency`로 `CPU & DMA Latency`가 있다.
2. PM QoS per-device latency and flags framework : 각 디바이스 별로 `from LPM to Active` 까지 전환하는데 발생하는 `Resume Latency`가 존재한다. 심지어, `From Power-Off to Active` 까지는 더 오랜 `Resume Latency`가 발생할 수 있다.: 그런데, `CPU latency` 라는 것이 뭘까? CPU가 어떤 작업을 완료하는데 걸린 시간의 양을 의미한다. `CPUidle`에서 말하는 `CPU latency`가 바로 `from deep-sleep to full-power` 에 걸린 시간의 양을 의미한다.
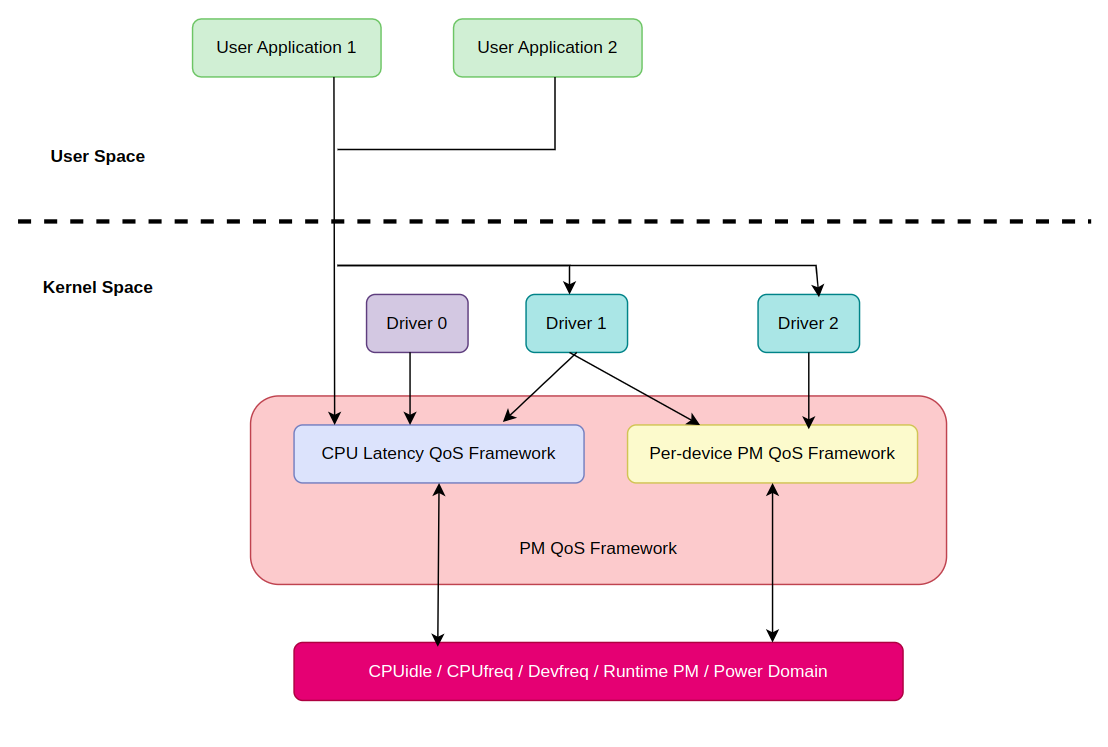
- PM QoS data structure
: `PM QoS`에서 가장 중요한 자료 구조는 `struct pm_qos_constraints` 구조체다.
//include/linux/pm_qos.h - v6.5 .... enum pm_qos_type { PM_QOS_UNITIALIZED, PM_QOS_MAX, /* return the largest value */ PM_QOS_MIN, /* return the smallest value */ }; /* * Note: The lockless read path depends on the CPU accessing target_value * or effective_flags atomically. Atomic access is only guaranteed on all CPU * types linux supports for 32 bit quantites */ struct pm_qos_constraints { struct plist_head list; s32 target_value; /* Do not change to 64 bit */ s32 default_value; s32 no_constraint_value; enum pm_qos_type type; struct blocking_notifier_head *notifiers; }; struct pm_qos_request { struct plist_node node; struct pm_qos_constraints *qos; }; ....: `struct pm_qos_constraints` 구조체 필드의 정보는 아래와 같다.
1. list : 모든 `CPU latency QoS request` 들을 관리하는 리스트.
2. target_value : 현재 시스템의 가장 강력한 `CPU latency QoS request`
3. default_value : 새로운 `CPU latency QoS request`가 들어올 때, 이 값으로 초기화된다.
4. no_constraint_value : 이 변수는 `CPU latency QoS request` 들을 관리하는 리스트가 비어있다는 것을 의미한다.
5. type : 이 값에 따라 `target_value`에 작성된 값이 `하한` 으로 계산해야 하는지, 혹은 `상한(MAX)` 으로 계산해야 하는지를 판별한다.
6. notifiers : 새로운 `CPU latency QoS request` 가 `추가/변경/제거` 될 때, 이 변수에 연결된 `notifier` 콜백들이 호출된다. 그러나, `커널 버전 6.5`에서 글로벌 `CPU latency QoS list`에 `notifier callback`을 등록할 방법이 없다. 뒤에서 다시 설명한다.: `struct pm_qos_type` 구조체 정보는 아래와 같다.
1. PM_QOS_MAX : `상한`을 의미한다. 즉, `struct pm_qos_constraints.target_value` 를 넘으면 안된다는 뜻이다.
2. PM_QOS_MIN : `하한`을 의미한다. 즉, `struct pm_qos_constraints.target_value` 보다 낮으면 안된다는 뜻이다.- CPU latency QoS framework
: `CPU latency QoS framework`는 시스템 전역적으로 `QoS` 를 관리한다고 보면 된다. 참고로, 커널 4.x 버전까지는 `CPU latency QoS`라는 이름을 사용하지 않았다[참고1 참조2]. 그 때는 `PM QoS classes` 라는 이름을 사용했었다. 제공하는 인터페이스는 2가지로 나뉜다.
1. 커널 레벨 : 커널 레벨에서 동작하는 모든 요소(드라이버, 커널 스레드 등)들에게 `함수`를 제공한다. 커널 레벨의 드라이버, 커널 스레드는 PM QoS class framework가 제공하는 API를 통해 자신의 constraints를 PM QoS framework에 알릴 수 있다.
2. 유저 레벨 : 유저 레벨에서 동작하는 모든 요소들은 `/dev/*`를 통해서 액세스가 가능하다. 유저 레벨의 애플리케이션들은 `/dev/**`를 통해서 자신의 constraints를 PM QoS framework에 알릴 수 있다.: 먼저 커널 레벨부터 알아보자.
- Kernel-level CPU latency QoS framework
: 먼저, 커널 레벨에서 제공되는 `CPU latency QoS framework API`s` 는 아래와 같다. `CPU latency QoS framework`는 `CONFIG_CPU_IDLE` 기능과 땔려야 땔 수가 없다. `CPUidle` 기능이 비활성화되면, 이 기능도 의미가 없다. `CPU latency QoS framework`는 별도의 CONFIG가 없다. 즉, `CPUidle` 서브-시스템에게 `CPU latency QoS`는 `optional`이 아닌, `mandatory`다.
// include/linux/pm_qos.h - v6.5 ..... #ifdef CONFIG_CPU_IDLE s32 cpu_latency_qos_limit(void); bool cpu_latency_qos_request_active(struct pm_qos_request *req); void cpu_latency_qos_add_request(struct pm_qos_request *req, s32 value); void cpu_latency_qos_update_request(struct pm_qos_request *req, s32 new_value); void cpu_latency_qos_remove_request(struct pm_qos_request *req); #else .... #endif: `CPU latency QoS framework`의 커널 레벨을 초기화하는 함수를 제공하지 않는다(참고로, `cpu_latency_qos_init` 함수가 있지만, 유저 레벨을 초기화하는 함수이므로 뒤에서 다시 설명한다). 커널 레벨 초기화 함수는 없지만, 커널 레벨에서 사용하는 글로벌 변수가 하나가 초기화된다. 바로, `cpu_latency_constraints` 변수다. 이 변수는 공식 문서에 아래와 같이 나와있다. 아래에서 얘기하는 `CPU latency QoS request`는 모두 `cpu_latency_constraints` 변수에 연결된다. 그리고, `effective` 라는 단어가 눈에 뛰는데, 그 이유는 `cpu_latency_constraints`는 일반적인 리스트가 아닌, 우선 순위를 기반으로 한 리스트이기 때문이다. 뒤에서 다시 다룬다.
A global list of CPU latency QoS requests is maintained along with an aggregated (effective) target value. The aggregated target value is updated with changes to the request list or elements of the list. For CPU latency QoS, the aggregated target value is simply the min of the request values held in the list elements.
- 참고 : https://docs.kernel.org/power/pm_qos_interface.html: `pm_qos_get_value` 함수는 인자로 전달된 제약 사항이(`pm_qos_constraints`) 하한값(`plist_first`)인지 상한값(`plist_last`)인지를 구분해서 값을 반환한다. 이 함수를 호출한 콜러에서는 반환값이 `하한`인지 `상한`인지를 판단해서, 파워 상태를 변경할지를 결정한다. `pm_qos_read_value` / `pm_qos_set_value` 함수의 구체적인 설명은 생략한다. `cpu_latency_qos_limit` 함수는 현재 시스템에 존재하는 가장 우선순위가 높은 `CPU latency limit`을 반환한다. 뒤에서 보겠지만, 이 값은 `cpu_latency_constraints.target_value`다.
//include/linux/pm_qos.h - V6.5 #define PM_QOS_CPU_LATENCY_DEFAULT_VALUE (2000 * USEC_PER_SEC) //kernel/power/qos.c - v6.5 /** * pm_qos_read_value - Return the current effective constraint value. * @c: List of PM QoS constraint requests. */ s32 pm_qos_read_value(struct pm_qos_constraints *c) { return READ_ONCE(c->target_value); } static int pm_qos_get_value(struct pm_qos_constraints *c) { if (plist_head_empty(&c->list)) return c->no_constraint_value; switch (c->type) { case PM_QOS_MIN: return plist_first(&c->list)->prio; case PM_QOS_MAX: return plist_last(&c->list)->prio; default: WARN(1, "Unknown PM QoS type in %s\n", __func__); return PM_QOS_DEFAULT_VALUE; } } static void pm_qos_set_value(struct pm_qos_constraints *c, s32 value) { WRITE_ONCE(c->target_value, value); } .... #ifdef CONFIG_CPU_IDLE /* Definitions related to the CPU latency QoS. */ static struct pm_qos_constraints cpu_latency_constraints = { .list = PLIST_HEAD_INIT(cpu_latency_constraints.list), .target_value = PM_QOS_CPU_LATENCY_DEFAULT_VALUE, .default_value = PM_QOS_CPU_LATENCY_DEFAULT_VALUE, .no_constraint_value = PM_QOS_CPU_LATENCY_DEFAULT_VALUE, .type = PM_QOS_MIN, }; /** * cpu_latency_qos_limit - Return current system-wide CPU latency QoS limit. */ s32 cpu_latency_qos_limit(void) { return pm_qos_read_value(&cpu_latency_constraints); }: 커널 레벨의 디바이스 드라이버에서 `CPU latency QoS`를 추가하고 싶다면, `cpu_latency_qos_add_request` 함수를 사용하면 된다. `req->qos = &cpu_latency_constraints` 를 하는 이유는 해당 요청이 글로벌 QoS 리스트에 추가되었다는 의미로 사용된다. 뒤에서 나올 `cpu_latency_qos_request_active` 함수에서 다시 설명한다.
: `cpu_latency_qos_add_request` / `cpu_latency_qos_apply` 함수들은 단순히 `pm_qos_update_target` 함수의 `래핑 함수` 이기 때문에 구체적인 설명은 생략한다.
//kernel/power/qos.c - V6.5 static void cpu_latency_qos_apply(struct pm_qos_request *req, enum pm_qos_req_action action, s32 value) { int ret = pm_qos_update_target(req->qos, &req->node, action, value); if (ret > 0) wake_up_all_idle_cpus(); } /** * cpu_latency_qos_add_request - Add new CPU latency QoS request. * @req: Pointer to a preallocated handle. * @value: Requested constraint value. * * Use @value to initialize the request handle pointed to by @req, insert it as * a new entry to the CPU latency QoS list and recompute the effective QoS * constraint for that list. * * Callers need to save the handle for later use in updates and removal of the * QoS request represented by it. */ void cpu_latency_qos_add_request(struct pm_qos_request *req, s32 value) { if (!req) return; if (cpu_latency_qos_request_active(req)) { WARN(1, KERN_ERR "%s called for already added request\n", __func__); return; } trace_pm_qos_add_request(value); req->qos = &cpu_latency_constraints; cpu_latency_qos_apply(req, PM_QOS_ADD_REQ, value); } EXPORT_SYMBOL_GPL(cpu_latency_qos_add_request);: `pm_qos_update_target` 함수는 실제 `target_value`를 변경시키는 함수다. 두 번째 인자로 전달된 `node`에 같이 전달된 `value`를 저장하고, global list of CPU latency QoS requests(`c`) 에(서) 삽입/변경/제거 한다.
//include/linux/pm_qos.h - v6.5 #define PM_QOS_DEFAULT_VALUE (-1) .... // kernel/power/qos.c - v6.5 /** * pm_qos_update_target - Update a list of PM QoS constraint requests. * @c: List of PM QoS requests. * @node: Target list entry. * @action: Action to carry out (add, update or remove). * @value: New request value for the target list entry. * * Update the given list of PM QoS constraint requests, @c, by carrying an * @action involving the @node list entry and @value on it. * * The recognized values of @action are PM_QOS_ADD_REQ (store @value in @node * and add it to the list), PM_QOS_UPDATE_REQ (remove @node from the list, store * @value in it and add it to the list again), and PM_QOS_REMOVE_REQ (remove * @node from the list, ignore @value). * * Return: 1 if the aggregate constraint value has changed, 0 otherwise. */ int pm_qos_update_target(struct pm_qos_constraints *c, struct plist_node *node, enum pm_qos_req_action action, int value) { int prev_value, curr_value, new_value; unsigned long flags; spin_lock_irqsave(&pm_qos_lock, flags); prev_value = pm_qos_get_value(c); if (value == PM_QOS_DEFAULT_VALUE) new_value = c->default_value; else new_value = value; switch (action) { case PM_QOS_REMOVE_REQ: plist_del(node, &c->list); break; case PM_QOS_UPDATE_REQ: /* * To change the list, atomically remove, reinit with new value * and add, then see if the aggregate has changed. */ plist_del(node, &c->list); fallthrough; case PM_QOS_ADD_REQ: plist_node_init(node, new_value); plist_add(node, &c->list); break; default: /* no action */ ; } curr_value = pm_qos_get_value(c); pm_qos_set_value(c, curr_value); spin_unlock_irqrestore(&pm_qos_lock, flags); trace_pm_qos_update_target(action, prev_value, curr_value); if (prev_value == curr_value) return 0; if (c->notifiers) blocking_notifier_call_chain(c->notifiers, curr_value, NULL); return 1; }: `pm_qos_update_target` 함수의 구체적인 동작은 아래와 같다.
switch(action) ... : `action`에 따라 동작이 달라진다.
- PM_QOS_REMOVE_REQ : `global list of CPU latency QoS requests` 에서 node를 제거한다.
- PM_QOS_UPDATE_REQ : `global list of CPU latency QoS requests` 에서 node를 제거한 뒤, 다시 추가한다.
- PM_QOS_ADD_REQ : `node`를 `new_value`로 초기화한뒤, `global list of CPU latency QoS requests`에 node를 추가한다. 전달받은 `req->node`는 이 함수로 들어올 때, 메모리 할당만 받은 상태이기 때문에, 이 함수에서 초기화를 진행한다.
curr_value = ... , pm_qos_set_ ... : `cpu_latency_constraints` 변수에서 현재 우선 순위가 가장 높은 `CPU latency limit` 을 가져와서, `cpu_latency_constraints.target_value`에 저장한다. 즉, 이 말은 `cpu_latency_constraints.target_value` 변수에는 항상 우선 순위가 가장 높은 `CPU latency limit`이 저장되어 있단 소리다. `CPUidle` 프레임워크는 이 값을 통해 `deep sleep`으로 들어갈지 말지를 결정한다.
if (prev_value == curr_value) ... : 이전에 limit 과 현재의 limit 이 같으면, 값이 그대로 유지된 것이므로 `noti`를 하지 않는다.
if (c->notifiers) ... : 마지막으로, 이전에 limit 과 현재의 limit 이 같지 않으면, 값이 변경된 것이므로 현재 설정된 limit 값을 등록되어 있는 모든 `notifiers`들에게 알린다.: `cpu_latency_qos_request_active` 함수는 현재 들어온 QoS 요청이 이미 전역 리스트에 존재하는지를 판별한다. 판별하는 기준은 `cpu_latency_qos_add_request` 함수에서 ` req->qos = &cpu_latency_constraints` 를 진행했었다. 바로 이 작업이 QoS 요청이 글로벌 QoS 리스트에 저장되었다는 것을 의미한다.
// kernel/power/qos.c - v6.5 .... /** * cpu_latency_qos_request_active - Check the given PM QoS request. * @req: PM QoS request to check. * * Return: 'true' if @req has been added to the CPU latency QoS list, 'false' * otherwise. */ bool cpu_latency_qos_request_active(struct pm_qos_request *req) { return req->qos == &cpu_latency_constraints; } .... /** * cpu_latency_qos_update_request - Modify existing CPU latency QoS request. * @req : QoS request to update. * @new_value: New requested constraint value. * * Use @new_value to update the QoS request represented by @req in the CPU * latency QoS list along with updating the effective constraint value for that * list. */ void cpu_latency_qos_update_request(struct pm_qos_request *req, s32 new_value) { if (!req) return; if (!cpu_latency_qos_request_active(req)) { WARN(1, KERN_ERR "%s called for unknown object\n", __func__); return; } trace_pm_qos_update_request(new_value); if (new_value == req->node.prio) return; cpu_latency_qos_apply(req, PM_QOS_UPDATE_REQ, new_value); } EXPORT_SYMBOL_GPL(cpu_latency_qos_update_request); /** * cpu_latency_qos_remove_request - Remove existing CPU latency QoS request. * @req: QoS request to remove. * * Remove the CPU latency QoS request represented by @req from the CPU latency * QoS list along with updating the effective constraint value for that list. */ void cpu_latency_qos_remove_request(struct pm_qos_request *req) { if (!req) return; if (!cpu_latency_qos_request_active(req)) { WARN(1, KERN_ERR "%s called for unknown object\n", __func__); return; } trace_pm_qos_remove_request(PM_QOS_DEFAULT_VALUE); cpu_latency_qos_apply(req, PM_QOS_REMOVE_REQ, PM_QOS_DEFAULT_VALUE); memset(req, 0, sizeof(*req)); } EXPORT_SYMBOL_GPL(cpu_latency_qos_remove_request);: 그 이후에는 동일하게 `cpu_layency_qos_apply` -> `pm_qos_update_target` 함수 순서로 호출된다(`action` 값만 `PM_QOS_UPDATE_REQ`로 변경). `cpu_latency_qos_remove_request` 함수 또한 내용이 비슷하기 때문에 자세한 설명은 생략한다.
: 공식문서에서는 아래와 같이 `CPU latency QoS notifier API`s`를 보여주고 있지만, 2개 모두 `커널 6.5`에서는 아예 존재하지 않는 함수다. 커널 패치에도 아래 함수들이 사라진 것에 대한 내용을 찾을 수 가 없다. 아래 문서에서만 존재하는 함수다... 즉, 커널 6.5에서는 `CPU latency QoS notifier`를 등록할 방법이 없다.
....
int cpu_latency_qos_add_notifier(notifier):
Adds a notification callback function to the CPU latency QoS. The callback is called when the aggregated value for the CPU latency QoS is changed.
int cpu_latency_qos_remove_notifier(notifier):
Removes the notification callback function from the CPU latency QoS.
....
- 참고 : https://docs.kernel.org/power/pm_qos_interface.html- User-level CPU latency QoS framework
: 이제 `CPU latency QoS framework`에서 지원해주는 유저 인터페이스에 대해 알아보자. 먼저, 유저 스페이스가 어떻게 생성되는지 부터 알아보자.
// kernel/power/qos.c - v6.5 #ifdef CONFIG_CPU_IDLE .... static const struct file_operations cpu_latency_qos_fops = { .write = cpu_latency_qos_write, .read = cpu_latency_qos_read, .open = cpu_latency_qos_open, .release = cpu_latency_qos_release, .llseek = noop_llseek, }; static struct miscdevice cpu_latency_qos_miscdev = { .minor = MISC_DYNAMIC_MINOR, .name = "cpu_dma_latency", .fops = &cpu_latency_qos_fops, }; static int __init cpu_latency_qos_init(void) { int ret; ret = misc_register(&cpu_latency_qos_miscdev); if (ret < 0) pr_err("%s: %s setup failed\n", __func__, cpu_latency_qos_miscdev.name); return ret; } late_initcall(cpu_latency_qos_init); #endif /* CONFIG_CPU_IDLE */: `cpu_latency_qos_init` 함수는 `misc_register` 함수를 통해 유저 인터페이스(`/dev/cpu_dma_latency`)를 생성한다. 인자로 전달되는 `struct miscdevice`의 중요한 필드만 알아보자.
1. minor : `MISC_DYNAMIC_MINOR` 값이 설정되면, `minor` 번호를 임의로 생성해준다. 직접 지정도 가능하다.
2. name : `/dev/${name}` 파일이 생성된다. 이 파일에 `cat`, `echo xxx` 같은 명령어를 사용하면 아래의 `fops`에 설정된 콜백 함수들이 호출된다.
3. fops : `/dev/${name}` 파일에 특정 명령어들을 수행했을 때, `fops`에 정의된 함수들이 호출된다. 예를 들면, `cat /dev/${name}` 을 입력하면, `cpu_latency_qos_read` 함수가 호출된다.: 이제 `fops`에 설정된 파일 연산자들에 대해서 간단하게 알아보자. 아래의 함수들을 요약하면 다음과 같다.
1. cpu_latency_qos_open : 새로운 `CPU latency QoS`를 하나 생성해서 글로벌 CPU latency QoS 리스트에 저장한다. 아직은 `target_value`가 없으므로, 크게 의미가 없는 QoS다. 그리고, 다른 파일 오퍼레이션에서 사용할 수 있도록 `file->private_data = req` 를 진행한다.
2. cpu_latency_qos_release : `cpu_latency_qos_open` 함수를 통해 생성한 CPU latency QoS 를 해제한다.
3. cpu_latency_qos_read : 현재 시스템에서 가장 강력한 CPU latency QoS limit 값을 반환한다.
4. cpu_latency_qos_write : 커널 버전 6.5에서 해당 함수는 비정상적인 동작을 한다. 예를 들어, 100 ~ 999 사이에 값이 오면, `count` 변수에는 4가 들어온다(`\n` 포함해서 네 글자). 그래서, `copy_from_user` 함수를 호출하게 되는데, 이 때 `value`에 쓰레기값이 들어오게 된다. 왜냐면, 현재 `buf`에 있는 값은 문자열값이기 때문이다. 이 값을 `s32` 데이터 타입에 넣으니 쓰레기값이 되버린 것이다. 패치는 올라와있는데, 아직 확정 되지는 않은 것 같다[참고1].// kernel/power/qos.c - v6.5 /* User space interface to the CPU latency QoS via misc device. */ static int cpu_latency_qos_open(struct inode *inode, struct file *filp) { struct pm_qos_request *req; req = kzalloc(sizeof(*req), GFP_KERNEL); if (!req) return -ENOMEM; cpu_latency_qos_add_request(req, PM_QOS_DEFAULT_VALUE); filp->private_data = req; return 0; } static int cpu_latency_qos_release(struct inode *inode, struct file *filp) { struct pm_qos_request *req = filp->private_data; filp->private_data = NULL; cpu_latency_qos_remove_request(req); kfree(req); return 0; } static ssize_t cpu_latency_qos_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos) { struct pm_qos_request *req = filp->private_data; unsigned long flags; s32 value; if (!req || !cpu_latency_qos_request_active(req)) return -EINVAL; spin_lock_irqsave(&pm_qos_lock, flags); value = pm_qos_get_value(&cpu_latency_constraints); spin_unlock_irqrestore(&pm_qos_lock, flags); return simple_read_from_buffer(buf, count, f_pos, &value, sizeof(s32)); } static ssize_t cpu_latency_qos_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos) { s32 value; if (count == sizeof(s32)) { if (copy_from_user(&value, buf, sizeof(s32))) return -EFAULT; } else { int ret; ret = kstrtos32_from_user(buf, count, 16, &value); if (ret) return ret; } cpu_latency_qos_update_request(filp->private_data, value); return count; }- Case study
: 예시로 가져온 코드는 `via`사의 카메라 드라이버 코드다. 아래 함수는 비디오 streaming을 시작할 때, 호출되는 콜백 함수다. 이 함수가 호출되는 시점에는 ACPI의 `C-STATE` 로 진입하지 못하도록, `CPUidle exit(resume) latency limit` 값을 50us으로 설정하고 있다. 이렇게 되면, CPUidle 서브-시스템은 CPU가 CPUidle 상태로 진입할 수 있는 상황에서 50us 보다 작은 `exit latency`를 가지는 `C-STATE`를 선택해야 한다. 대게, CPU 제조사에서는 디바이스 트리에 `C-STATE`에 따른 `exit latency`를 작성해놓고 있다. 그래서, 부팅 시점에 CPUidle 서브-시스템이 해당 내용을 디바이스 트리에서 가져와 저장한다.
// drivers/media/platform/via/via-camera.c - v6.5 static int viacam_vb2_start_streaming(struct vb2_queue *vq, unsigned int count) { struct via_camera *cam = vb2_get_drv_priv(vq); struct via_buffer *buf, *tmp; int ret = 0; if (cam->opstate != S_IDLE) { ret = -EBUSY; goto out; } /* * Configure things if need be. */ if (test_bit(CF_CONFIG_NEEDED, &cam->flags)) { ret = viacam_configure_sensor(cam); if (ret) goto out; ret = viacam_config_controller(cam); if (ret) goto out; } cam->sequence = 0; /* * If the CPU goes into C3, the DMA transfer gets corrupted and * users start filing unsightly bug reports. Put in a "latency" * requirement which will keep the CPU out of the deeper sleep * states. */ cpu_latency_qos_add_request(&cam->qos_request, 50); viacam_start_engine(cam); return 0; out: list_for_each_entry_safe(buf, tmp, &cam->buffer_queue, queue) { list_del(&buf->queue); vb2_buffer_done(&buf->vbuf.vb2_buf, VB2_BUF_STATE_QUEUED); } return ret; }: 그런데, 왜 `video streaming`을 할 때, `C3`로 가면 안될까? ACPI에서 정의하는 `C3` 상태는 `deep sleep` 상태를 의미한다. 그런데, `C3`에서는 `bus snooping hardware(coherency controller)`가 비활성화된다. 이 상황에서 DMA가 데이터를 캐쉬에 쓰게되면, `cache concurrency` 문제가 발생하게 된다. 그래서, `C3` 상태는 못들어가게 하는 것이다. 근데, `C3` 상태를 진입하는데, 무조건 50us 보다 더 걸리는 것일까? 이 링크를 들어가보면, `exit-latency-us` 라는 속성이 있다. CPU 제조사에서 디바이스 트리에 각 `C-STATE`의 `exit-latency-us`를 작성해 놓는다. 여기서 `C3`의 `exit-latency-us`를 찾아서 그 값보다 작게 설정하면 된다. 그런데, 칩 제조사마다 다른 내용이라서 가장 안전하게 가고 싶다면, `cpu_latency_qos_add_request(&cam->qos_request, 0)` 처럼 `0`을 쓰는 것이 가장 좋다. 그런데, 이렇게 하면 가장 낮은 `C-STATE` 까지도 진입하지 못하고 계속 `풀-파워`로 동작하게 된다. 이럴 때는, 디바이스 트리에서 `idle-states` 노드를 읽어서 `C3 exit latency` 보다 값을 작게 주는 것이 좋다.
CPUIDLE_FLAG_CHECK_BM indicates that this state is not compatible with bus-mastering DMA activity. Deep sleeps will, among other things, disable the bus cycle snooping hardware, meaning that processor-local caches may fail to be updated in response to DMA. That can lead to data corruption problems.
- 참고 : https://lwn.net/Articles/384146/'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Timer - Broadcast timer (0) 2023.09.17 [리눅스 커널] Cpuidle - idle process (0) 2023.09.12 [리눅스 커널] Timer - Dynamic tick(tick sched) (0) 2023.09.08 [리눅스 커널] Wait queue & condition (0) 2023.09.08 [리눅스 커널] PM - Wakeup interrupt (0) 2023.09.05