-
[리눅스 커널] Interrupt - ARMv7 interrupt handling processLinux/kernel 2023. 11. 14. 18:10
글의 참고
- https://people.kernel.org/linusw/setting-up-the-arm32-architecture-part-1
- https://people.kernel.org/linusw/setting-up-the-arm32-architecture-part-2
- https://stackoverflow.com/questions/36649551/vectors-page-mapping-in-linux-for-arm
- http://www.wowotech.net/irq_subsystem/irq_handler.html
- https://zhuanlan.zhihu.com/p/363148708?utm_id=0
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" 이 글은 ARMv7 에서 어떻게 인터럽트를 처리하는지를 알아볼 것이다. 인터럽트는 특히나 하드웨어와도 깊은 연관성이 있기 때문에, ARMv7 의 스펙을 참고하면서 설명해야 한다.
- before processing a interrupt
1. prepare each stack for irq, abt, irq and fiq mode
" armv7 프로세서에는 다양한 동작 모드가 존재한다. 예를 들어, user mode (CPU 가 user space 코드를 실행하고 있을 경우), supervisor mode (커널 코드는 대부분 svc mode 에서 실행된다), IRQ mode (interrupt 가 발생하면, 프로세서의 동작 모드는 이 모드로 변경된다) 등등이 있다. 그런데, 리눅스 커널 같은 경우는 인터럽트를 처리하는 동안에 IRQ mode 가 아닌, svc mode 있다. 이게 무슨 말일까? 인터럽트가 발생하면, 실제 ARM processor 는 IRQ mode 로 전환된다. 여기서 IRQ mode 에는 잠깐만 있는다. 즉, IRQ mode 에서는 빨리 처리할 수 있는 사이즈가 작은 작업들을 처리하고, svc mode 로 전환해서 남아있는 인터럽트 처리를 마저 진행한다. IRQ mode 에는 짧게만 머물기 때문에, 할당되는 스택도 딱 16B 다(참고로, x86_64 같은 경우는 stack switching 을 하드웨어 차원에서 지원해준다(`IST`))).
// arch/arm/kernel/setup.c - v6.5 struct stack { u32 irq[4]; u32 abt[4]; u32 und[4]; u32 fiq[4]; } ____cacheline_aligned; #ifndef CONFIG_CPU_V7M static struct stack stacks[NR_CPUS]; #endif" 위에 struct stack 자료 구조를 보면, armv7 에서는 irq, abt, und, fiq 동작 모드에 대해 각각 16B 스택을 할당해주는 것을 알 수 있다. 예를 들어, undefined instruction exception 이 발생하면, `und[4]` 를 사용하게 되는것이다. 인터럽트가 발생하면, `irq[4]` 를 사용하게 된다. 그리고, data abort 와 pre-fetch abort 는 구분하지 않고 `abt[4]` 를 사용한다.
" 그리고, stacks 변수가 배열로 선언된 것으로 봐서는 banked register 처럼 스택도 각 CPU 별로 할당되는 것을 알 수 있다. 즉, banked register stack 이 생겼다고 봐도 무방하다. armv7 에서는 각 동작 모드에 따른 스택 초기화 방법을 아래와 같이 진행하라고 한다. 먼저, `msr cpsr_c, #operation_mode` 를 통해서 먼저 동작 모드를 변경한다. 그리고, `mov sp, #each_stack_start_addr` 를 통해서 스택을 초기화하면 된다. 이렇게 되면, 각 동작 모드가 switching 될 때마다, 스택도 같이 대응하는 동작 모드로 체인지된다.
13.1 Booting a bare-metal system
....
You might then have to initialize stack pointers for the various modes that your application can make use of. Example 13-2 on page 13-3 gives a simple example, showing code that initializes the stack pointers for FIQ and IRQ modes.
Example 13-2 Code to initialize the stack pointers -------------------------------------------------- LDR R0, stack_base @ Enter each mode in turn and set up the stack pointer MSR CPSR_c, #Mode_FIQ:OR:I_Bit:OR:F_Bit ; MOV SP, R0 SUB R0, R0, #FIQ_Stack_Size MSR CPSR_c, #Mode_IRQ:OR:I_Bit:OR:F_Bit ; MOV SP, R0
- 참고 : ARM Cortex-A Series Programmer’s Guide" 그런데, `msr cpsr_c` 에서 cpsr_c 는 뭘까? CPSR 레지스터에서 하위 8비트(0~7)를 의미한다[참고1].


" 리눅스 커널에서 armv7 동작 모드 스택 초기화는 시스템이 초기화되는 시점에 `cpu_init` 함수에서 설정된다. cpu_init 함수는 현재 실행중 인 CPU 의 irq, abt, und 및 fiq 4 가지 모드에 대한 커널 스택을 설정한다.
// arch/arm/kernel/setup.c - v6.5 /* * cpu_init - initialise one CPU. * * cpu_init sets up the per-CPU stacks. */ void notrace cpu_init(void) { #ifndef CONFIG_CPU_V7M unsigned int cpu = smp_processor_id(); // --- 1 struct stack *stk = &stacks[cpu]; // --- 1 if (cpu >= NR_CPUS) { pr_crit("CPU%u: bad primary CPU number\n", cpu); BUG(); } .... /* * Define the placement constraint for the inline asm directive below. * In Thumb-2, msr with an immediate value is not allowed. */ #ifdef CONFIG_THUMB2_KERNEL #define PLC_l "l" #define PLC_r "r" #else #define PLC_l "I" #define PLC_r "I" #endif /* * setup stacks for re-entrant exception handlers */ __asm__ ( // --- 2 "msr cpsr_c, %1\n\t" "add r14, %0, %2\n\t" "mov sp, r14\n\t" "msr cpsr_c, %3\n\t" "add r14, %0, %4\n\t" "mov sp, r14\n\t" "msr cpsr_c, %5\n\t" "add r14, %0, %6\n\t" "mov sp, r14\n\t" "msr cpsr_c, %7\n\t" "add r14, %0, %8\n\t" "mov sp, r14\n\t" "msr cpsr_c, %9" : : "r" (stk), PLC_r (PSR_F_BIT | PSR_I_BIT | IRQ_MODE), "I" (offsetof(struct stack, irq[0])), PLC_r (PSR_F_BIT | PSR_I_BIT | ABT_MODE), "I" (offsetof(struct stack, abt[0])), PLC_r (PSR_F_BIT | PSR_I_BIT | UND_MODE), "I" (offsetof(struct stack, und[0])), PLC_r (PSR_F_BIT | PSR_I_BIT | FIQ_MODE), "I" (offsetof(struct stack, fiq[0])), PLC_l (PSR_F_BIT | PSR_I_BIT | SVC_MODE) : "r14"); #endif }1. 현재 코드를 실행중 인 CPU 번호를 받아와서, IRQ mode, Abort mode, und mode, FIQ mode 에서 사용할 스택 주소를 가져온다(stacks 변수에 4 가지 동작 모드에 대해 각 16B 를 할당).
2. 인라인 어셈블리어가 나오는데, 구조는 format 은 다음과 같다(구체적인 내용은 이 글을 참고하자).
asm(code : output operand list : input operand list : clobber list);
`r` 과 `I` 은 inline assembly 에서 constraint 라고 부른다. 말 그대로, 제약 사항을 준다는 것인데, r 은 레지스터를 사용하라는 뜻이고, I (대문자) 는 즉각적으로 값을 사용하겠다는 뜻이다. 쉽게, 상수값을 직접 명시한다는 뜻이다. output operand 는 없고, input operand 만 존재한다. 그리고, clobber list 가 존재하는데, 위 코드를 기준으로 `r14 레지스터는 내가 직접 사용할거니, 너는 다른 레지스터를 사용하렴` 이라는 뜻이다.
구체적인 설명은 치환된 코드로 대체한다.
/*
* setup stacks for re-entrant exception handlers
*/
__asm__ (
"msr cpsr_c,PLC_r (PSR_F_BIT | PSR_I_BIT | IRQ_MODE)\n\t"
"add r14, stk, "I" (offsetof(struct stack, irq[0]))\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, PLC_r (PSR_F_BIT | PSR_I_BIT | ABT_MODE)\n\t"
"add r14, stk, "I" (offsetof(struct stack, abt[0]))\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, PLC_r (PSR_F_BIT | PSR_I_BIT | UND_MODE)\n\t"
"add r14, stk, "I" (offsetof(struct stack, und[0]))\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, PLC_r (PSR_F_BIT | PSR_I_BIT | FIQ_MODE)\n\t"
"add r14, stk, "I" (offsetof(struct stack, fiq[0]))\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, PLC_l (PSR_F_BIT | PSR_I_BIT | SVC_MODE)"
::: "r14");" SMP 환경에서 커널 초기화 시점에, 동작 모드(irq, abt, unf, fiq) 에 따른 CPU 커널 스택을 초기화하는 플로우는 boot CPU 냐 secondary CPU 냐에 따라 다르다.
- boot CPU : start_kernel -> setup_arch -> setup_processor -> cpu_init
- secondary CPU`s : secondary_start_kernel -> cpu_init2. prepare stack for svc mode [참고0 참고1 참고2 참고3 참고4]
" 왜 svc mode 의 스택은 별도로 설명할까? armv7 프로세서가 kernel space 에서 동작하면, svc mode 로 동작한다. 즉, 커널 코드를 실행하면 armv7 의 동작 모드는 svc mode 라는 것이다. 그렇다면, svc mode 의 스택은 어떻게 결정할 수 있을까? 커널 스택이 svc mode 의 스택이 된다. 즉, 커널 스택이 svc mode 스택과 동의어라는 뜻이다. 이 섹션에서는 armv7 의 초기 스택 설정에 대해 알아본다.
" 리눅스 초기 부팅시점에는 프로세스 (엄밀히 따지면, 커널 스레드) 가 딱 한개만 존재한다. 이 프로세스의 PID 는 `0` 이며, 그 유명한 `swapper process (idle process)` 를 의미한다. 이 프로세스의 커널 스택은 동적이 아닌 정적으로 할당되는데, 해당 절차는 다음과 같다.
/* * The following fragment of code is executed with the MMU on in MMU mode, * and uses absolute addresses; this is not position independent. * * r0 = cp#15 control register (exc_ret for M-class) * r1 = machine ID * r2 = atags/dtb pointer * r9 = processor ID */ __INIT __mmap_switched: .... adr r4, __mmap_switched_data // --- 1 .... ARM( ldmia r4!, {r0, r1, sp} ) .... #ifdef CONFIG_KASAN .... #endif mov lr, #0 b start_kernel ENDPROC(__mmap_switched) .align 2 .type __mmap_switched_data, %object __mmap_switched_data: #ifdef CONFIG_XIP_KERNEL .... #endif .long __bss_start @ r0 .long __bss_stop @ r1 .long init_thread_union + THREAD_START_SP @ sp // --- 2 ....1. __mmap_swithced_data 는 아래쪽에서 볼 수 있다시피, CONFIG_XIP_KERNEL 컨피그가 설정되어 있지 않다면, 첫 번째 데이터가 _bss_start, 두 번째가 __bss_stp, 세 번째가 init_thread_union + THREAD_START_SP 다. 우리가 궁금한 건 바로 이놈이다. `adr r4, __mmap_swithced_data` 를 통해서 r4 는 __mmap_switched_data 심볼 주소를 가리키게 된다.
2. 최초에 커널 스택(svc mode stack)은 `init_thread_union + THREAD_START_SP` 가 된다. 그렇다면, 커널의 시작 주소가 `init_thread_union` 이고, 사이즈는 `THREAD_START_SP` 라는 결론이 나온다. 그렇다면, 여기서 멈추지 말고 이 2개를 좀 더 분석해보자. 초기 svc mode 의 커널 스택 사이즈는 `THREAD_START_SP` 다. 이 값은 아래와 같이 `THREAD_SIZE - 8` 로 정의되며, armv7 은 default 로 KASAN 을 사용하지 않고, PAGE_SIZE 는 기본적으로 1<<12 임을 감안하면, THREAD_START_SP 는 `(1<<13)-8` 이 된다. 여기서 8 을 빼는 이유는 스택의 동작 때문이다. 스택은 값을 집어넣고, 주소를 내리는 방식(decrement after)이기 때문에, THREAD_SIZE 로 설정하면, 다른 주소를 침범하게 된다(딱, 8 바이트 침범한다). 그리고, 굳이 8 인 이유는 armv7 의 AAPCS 를 보면, 스택이 8 바이트 정렬이라는 것을 알 수 있다. 즉, sp 의 이동 단위가 8 바이트라는 뜻이다.
// arch/arm/include/asm/thread_info.h - v6.5 #ifdef CONFIG_KASAN /* * KASan uses a lot of extra stack space so the thread size order needs to * be increased. */ #define THREAD_SIZE_ORDER 2 #else #define THREAD_SIZE_ORDER 1 #endif #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER) #define THREAD_START_SP (THREAD_SIZE - 8) ....
" 그렇다면, 커널 스택의 시작 주소인 `init_thread_union` 는 무엇일까? thread_union 은 전역 변수로 `union_thread_union` 구조체를 통해서 선언된다.// include/linux/sched/task.h - v6.5 extern union thread_union init_thread_union;// include/linux/sched.h - v6.5 union thread_union { #ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK struct task_struct task; #endif #ifndef CONFIG_THREAD_INFO_IN_TASK struct thread_info thread_info; #endif unsigned long stack[THREAD_SIZE/sizeof(long)]; }; .... extern unsigned long init_stack[THREAD_SIZE / sizeof(unsigned long)]; ....
" CONFIG_ARCH_TASK_STRUCT_ON_STACK 컨피그는 ia64 에서만 SET 된다. 그리고, armv7 에서는 default 로 CONFIG_THREAD_INFO_IN_TASK 컨피그가 SET 된다. 그렇다면, struct thread_info 와 stack 만 남게된다. 그런데, union 으로 선언되어 있기때문에, 둘 중에 더 큰 사이즈로 공용체의 사이즈가 결정된다. 그렇다면, 누가 더 클까? 그걸 알려면, linker script 를 확인해봐야 한다.// include/asm-generic/vmlinux.lds.h - v6.5 #define INIT_TASK_DATA(align) \ . = ALIGN(align); \ __start_init_task = .; \ init_thread_union = .; \ init_stack = .; \ KEEP(*(.data..init_task)) \ KEEP(*(.data..init_thread_info)) \ . = __start_init_task + THREAD_SIZE; \
" linker script 를 보면, init_thread_union 과 init_stack 의 주소를 동일하게 두고 있다. 그리고, 중간에 `.data..init_task` 데이터 섹션과 `.data..init_thread_info` 데이터 섹션을 초기 스택 커널에 배치하고 있다. armv7 에서 CONFIG_ARCH_TASK_STRUCT_ON_STACK 컨피그는 설정되어 있지 않기 때문에, `.data..init_thread_info` 데이터 섹션의 사이즈만 알면된다.// include/linux/init_task.h - v6.5 /* Attach to the init_task data structure for proper alignment */ #ifdef CONFIG_ARCH_TASK_STRUCT_ON_STACK #define __init_task_data __section(".data..init_task") #else #define __init_task_data /**/ #endif /* Attach to the thread_info data structure for proper alignment */ #define __init_thread_info __section(".data..init_thread_info")
" 결국 `struct thread_info` 구조체 만큼의 사이즈가 `data..init_thread_info` 데이터 섹션을 의미한다.// init/init_task.c - v6.5 /* * Initial thread structure. Alignment of this is handled by a special * linker map entry. */ #ifndef CONFIG_THREAD_INFO_IN_TASK struct thread_info init_thread_info __init_thread_info = INIT_THREAD_INFO(init_task); #endif
" 결국, 마지막에 `. = __start_init_task + THREAD_SIZE` 를 통해서 struct thread_info 구조체가 THREAD_SIZE 보다 작다는 것을 알 수 있다. 만약, struct thread_info 가 더 크다면, 이건 스택 오버플로우다. 정리하면, 다음과 같다.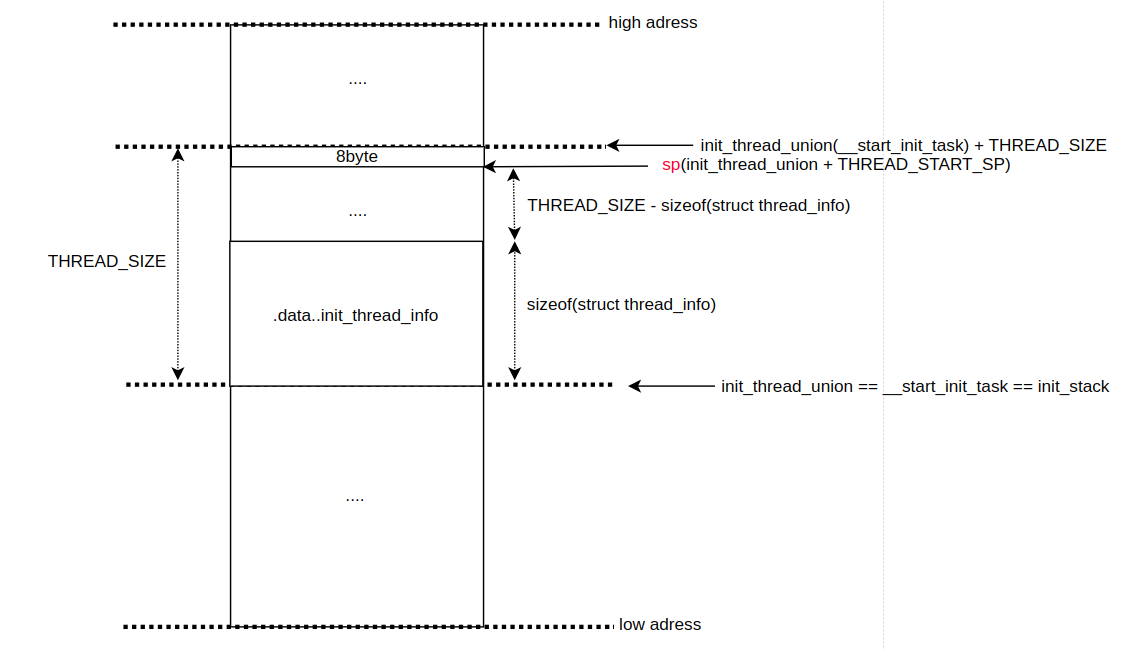
3. prepare for exception vector table [참고1]
" arm processor 에서 exception 이 발생하면, current execution 을 멈추고, 현재 컨택스트를 스택에 저장하고, exception 을 처리하기 위해 대응하는 exeception vector 를 실행한다. exeception 이 모두 처리되면, arm processor 는 exception 발생한 시점에 저장해놓은 컨택스트를 복구한 뒤, exception 이 발생했던 시점으로 복귀해서 이전 작업을 이어나간다. armv7 에서 exception 은 총 8개가 존재하며, exception vector`s 들을 관리하는 자료 구조를 exception vector table 이라고 한다.
// arch/arm/kernel/entry-armv.S - v6.5 .... .section .vectors, "ax", %progbits W(b) vector_rst W(b) vector_und ARM( .reloc ., R_ARM_LDR_PC_G0, .L__vector_swi ) THUMB( .reloc ., R_ARM_THM_PC12, .L__vector_swi ) W(ldr) pc, . W(b) vector_pabt W(b) vector_dabt W(b) vector_addrexcptn W(b) vector_irq W(b) vector_fiq ...." armv7 에서 exception vector table 은 2 군데에 위치할 수 있다고 했다. 먼저 0x0 번지에 로드될 수 있다. exception vector table 이 0x0 에 로드될 경우, 해당 주소를 low vectors 라고 한다. 그리고, 0xFFFF0000 에 로드될 수 있다. exception vector table 이 0xFFFF0000 에 로드될 경우, high vectors 라고 한다.
Exception handling on the core is controlled through the use of an area of memory called the vector table. This lives by default at the bottom of the memory map in word-aligned addresses from 0x00 to 0x1C. Most of the cached cores enable the vector table to be moved from 0x0 to 0xFFFF0000...
The default vector base address is 0x00000000, but most ARM cores permit the vector base address to be moved to 0xFFFF0000 (or HIVECS). All Cortex-A series processors permit this, and it is the default address selected by the Linux kernel...
- 참고 : ARM Cortex-A Series Programmer’s Guide" exception vector table 이 low vectors 혹은 high vectors 인지에 대한 여부는 CP15.SCTLR (CP15 System Control Register) V(13번째) 비트를 통해 결정된다. armv7 linux 같은 경우는 MMU 가 enabled 되어있으면, high vectors 를 사용한다.

ARM Cortex-A Series Programmer’s Guide" 그런데, 리눅스 왜 low vectors 를 사용하지 않을까? 리눅스는 virtual memory 0GB ~ 3GB 는 user space 에게 할당되어 있다. 만약, low vectors 가 설정되면, exception vector table 은 0x0 번지에 로드되야 하기 때문에 low vectors 를 설정할 수 없다. 주의할 점이 있다. armv7 문서에 보면, exception vector table 은 virtual address 에 매핑된다. 즉, 물리적으로 exception vector table 이 어디에 로드되어 있는지 모르겠지만, 그 주소는 반드시 0xFFFF0000 or 0x00000000 으로 매핑되어야 한다.
11.4.1 Boot process
During the boot process, the kernel will allocate a 4KB page as the vector page. It maps this to the location of the exception vectors, virtual address 0xFFFF0000 or 0x00000000. This is done by devicemaps_init() in the file arch/arm/mm/mmu.c. This is invoked very early in the ARM system boot. After this, trap_init (in arch/arm/kernel/traps.c), copies the exception vector table, exception stubs and kuser helpers into the vector page. The exception vector table obviously has to be copied to the start of the vector page, the exception stubs being copied to address 0x200 (and kuser helpers copied to the top of the page, at 0x1000 - kuser_sz), using a series of memcpy() operations, as shown inExample 11-2.
Example 11-2 Copying exception vectors during Linux boot
When the copying is complete, the kernel exception handler is in its runtime dynamic status, ready to handle exceptionsunsigned long vectors = CONFIG_VECTORS_BASE;
memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start);
memcpy((void *)vectors + 0x1000 - kuser_sz, __kuser_helper_start, kuser_sz);
- 참고 : ARM Cortex-A Series Programmer’s Guide" devicemaps_init() 함수는 exception vector table 을 0xFFFF0000 or 0x00000000 에 복사하는 역할을 한다.
// arch/arm/mm/mmu.c - v6.5 /* * Set up the device mappings. Since we clear out the page tables for all * mappings above VMALLOC_START, except early fixmap, we might remove debug * device mappings. This means earlycon can be used to debug this function * Any other function or debugging method which may touch any device _will_ * crash the kernel. */ static void __init devicemaps_init(const struct machine_desc *mdesc) { struct map_desc map; unsigned long addr; void *vectors; /* * Allocate the vector page early. */ vectors = early_alloc(PAGE_SIZE * 2); // --- 1 early_trap_init(vectors); // --- 1 .... /* * Create a mapping for the machine vectors at the high-vectors * location (0xffff0000). If we aren't using high-vectors, also * create a mapping at the low-vectors virtual address. */ map.pfn = __phys_to_pfn(virt_to_phys(vectors)); // --- 2 map.virtual = 0xffff0000; map.length = PAGE_SIZE; #ifdef CONFIG_KUSER_HELPERS map.type = MT_HIGH_VECTORS; #else map.type = MT_LOW_VECTORS; #endif create_mapping(&map); // --- 2 if (!vectors_high()) { // --- 3 map.virtual = 0; map.length = PAGE_SIZE * 2; map.type = MT_LOW_VECTORS; create_mapping(&map); // --- 3 } /* Now create a kernel read-only mapping */ map.pfn += 1; map.virtual = 0xffff0000 + PAGE_SIZE; map.length = PAGE_SIZE; map.type = MT_LOW_VECTORS; create_mapping(&map); // --- 4 .... }1. `.vectors` 섹션과 `.stubs` 섹션에 각각 1KB 를 할당받기 위해 가상 메모리를 `PAGE_SIZE * 2` 만큼 할당받는다. 지금 할당받은 exception vector table 의 가상 주소인 0xFFFF0000 & 0x00000000 와는 전혀 상관없는 주소다. early_trap_init() 함수에서는 exception vector table, exception stubs, kuser helpers 를 전달된 받은 가상 주소(vectors)에 복사한다. armv7 의 early_alloc() 함수는 내부적으로 memblock_alloc() 함수를 호출하는데, 이 함수는 virtual address 를 반환한다.
Once memblock is setup the memory can be allocated using one of the API variants:
- memblock_phys_alloc*() - these functions return the physical address of the allocated memory
- memblock_alloc*() - these functions return the virtual address of the allocated memory.
- 참고 : https://docs.kernel.org/core-api/boot-time-mm.html
2. `vectors` 는 가상 주소다. 이 값을 다른 exception vector table 를 주소로 매핑하기 위해서 먼저 물리 주소로 변환한다virt_to_phys). 그리고, create_mapping() 함수를 통해서 가상 주소 0xFFFF_0000 에 매핑된다(CONFIG_KUSER_HELPERS 컨피그가 설정되어 있지 않으면, low vectors 로 세팅된다).
3. vector_high() 함수는 내부적으로 get_cr() 함수를 통해서 CP15.SCTLR 레지스터를 읽어온다. 그리고, V(vector base address) 를 판별해서 0 일 경우, low vectors 를, 1 일 경우 high vectors 를 의미한다.
// arch/arm/include/asm/cp15.h - v6.5 #define CR_V (1 << 13) /* Vectors relocated to 0xffff0000 */ .... #if __LINUX_ARM_ARCH__ >= 4 #define vectors_high() (get_cr() & CR_V) #else #define vectors_high() (0) #endif #ifdef CONFIG_CPU_CP15 .... static inline unsigned long get_cr(void) { unsigned long val; asm("mrc p15, 0, %0, c1, c0, 0 @ get CR" : "=r" (val) : : "cc"); return val; } ....
4. `11.4.1 Boot process` 에서 봤지마, 0xFFFF0000 ~ 0xFFFF1000 에는 exception vector table 과 kuser helper 가 저장되고, 가상 주소 0xFFFF1000 ~ 0xFFFF2000 에는 exception stubs 이 저장된다. 해당 코드는, exception stubs 를 0xFFFF1000 에 매핑한다(stub 는 뒤에서 보겠지만, 간단히 요약하면 실제 익셉션 핸들링 코드를 의미한다)." early_trap_init() 함수는 인자로 전달받은 가상 주소에 vectors_base 에 `/arch/arm/kernel/entry-armv.S` 에 정의한 exception vector table, kuser helper, exception stubs 를 복사한다.
// arch/arm/kernel/traps.c - v6.5 void __init early_trap_init(void *vectors_base) { extern char __stubs_start[], __stubs_end[]; extern char __vectors_start[], __vectors_end[]; unsigned i; vectors_page = vectors_base; /* * Poison the vectors page with an undefined instruction. This * instruction is chosen to be undefined for both ARM and Thumb * ISAs. The Thumb version is an undefined instruction with a * branch back to the undefined instruction. */ for (i = 0; i < PAGE_SIZE / sizeof(u32); i++) // --- 1 ((u32 *)vectors_base)[i] = 0xe7fddef1; /* * Copy the vectors, stubs and kuser helpers (in entry-armv.S) * into the vector page, mapped at 0xffff0000, and ensure these * are visible to the instruction stream. */ copy_from_lma(vectors_base, __vectors_start, __vectors_end); // --- 2 copy_from_lma(vectors_base + 0x1000, __stubs_start, __stubs_end); // --- 2 .... }1. 0xFFFF_0000 ~ 0xFFFF_2000 에 undefined instructions 들로 채운다. 왜 이런 짓을 할까? exception vector table 과 kuser helper 를 합해도 4KB(한 페이지) 가 되지 않는다. 즉, 나머지 공간이 남는다. 만약, CPU 가 이 `회색 지대(무방비 지대)` 에 액세스하게 될 경우, 알 수 없는 결과(unknown issue)를 초래할 수 있다. 그래서, 이 공간을 undefined instruction 들로 채워서 예외를 발생시키는 것이다.
2. vectors_base 는 가상 주소를 가지고 있다. 그런데, 0xffff_0000 나 0x0000_0000 가 아니다. 그렇다면, 기존 데이터들을 저기로 왜 카피할까? 그냥, `__vector_end - __vector_start` 를 0xffff_0000 나 0x0000_0000 에 직접 매핑시키면 안될까? 사실, 이 부분은 잘 이해가 가질 않는다. 이미, exception vector table 이 RAM 에 로딩이 되어있을텐데, 다른 곳에 복사한뒤에 가상 주소를 0xFFFF_0000 에 매핑한다? ...- ARMv7 handling of interrupt events
" arm processor 가 GIC 로 부터 인터럽트를 받으면, 아래의 절차들을 순서대로 수행한다.
1. CPSR (Current Program Status Register) 의 M[4:0] 필드를 수정한다. M[4:0] 은 현재 동작 모드를 나타낸다. armv7 에서 정의하는 동작 모드는 아래와 같다.
Operating mode M[4:0] Privilege level User(usr) 10000 PL0 FIQ(fiq) 10001 PL1 IRQ(irq) 10010 PL1 Supervisor(svc) 10011 PL1 Monitor(mon) 10110 PL1 Abort(abt) 10111 PL1 Hyp(hyp) 11010 PL2 Undefined(und) 11011 PL1 System(sys) 11111 PL1
인터럽트가 발생하면, arm processor 의 동작 모드는 IRQ mode(10010) 로 변경된다.
2. CPSR 레지스터 값 (인터럽트 발생 전) 과 현재 PC 포인터의 값을 저장한다(인터럽트 처리 완료 후, 복귀를 위해).
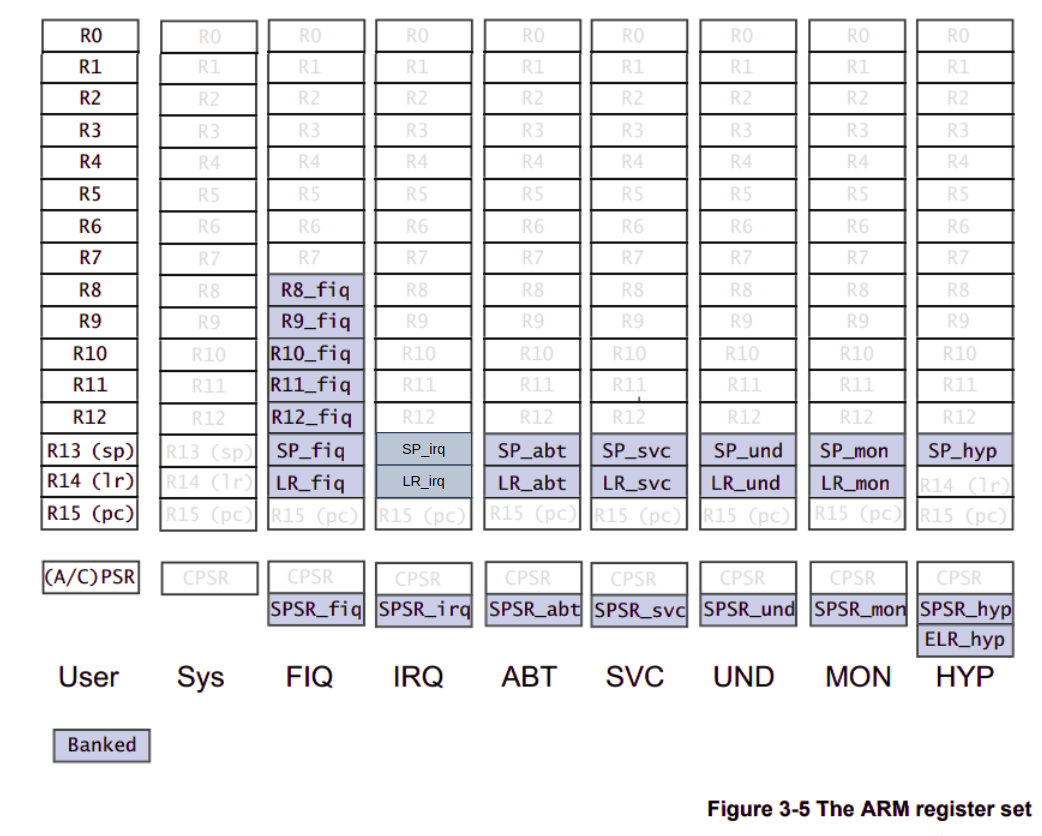
armv7 에서는 총 9 개의 동작 모드가 존재한다. 그리고, 총 16개의 레지스터를 제공한다. 여기서 중요한 건 동작 모드에 따라 arm processor 간에 공유할 수 있는 레지스터와 아닌 레지스터가 나뉜다는 것이다.
- banked register : 동작 모드에 따라 프로세서가 갖는 고유의 레지스터. 즉, Per-CPU 레지스터라고 보면 된다.
- non-banked register : 동작 모드에 관계없이 모든 프로세서가 공유하는 레지스터.
예를 들어, IRQ mode 에서 R0 ~ R12 , PC, CPSR 레지스터는 모든 프로세서가 공유한다(유저 모드이든 커널 모드이든 상관없다). 그러나, R13 (SP, stack pointer), R14 (LR, link register), SPSR (Saved Progarm Status Register) 는 각 프로세서마다 모두 다른 값을 갖는다.
x86 같은 경우에는 CPU 마다 플래그 레지스터가 별도로 있었는데, arm 은 CPSR 레지스터를 모두 공유한다. 그렇다면, 어떻게 코어마다 인터럽트를 처리할 수 없다는 뜻일까? arm 은 대신에 각 동작 모드마다 SPSR_* 레지스터를 갖는다. 예를 들어, 인터럽트가 발생하면, CPSR 레지스터 값이 SPSR_irq 레지스터에 저장되고, CPSR.M[4:0] 가 IRQ mode 로 변경될 것 이다.
PC 도 동작 모드에 상관없이 모든 프로세서가 공유한다. PC 같은 경우도, 인터럽트 및 익셉션이 발생할 경우, 복귀 지점을 저장하기 위해서 현재 PC 를 저장해야 한다. 그 역할을 하는 레지스터는 LR_* 레지스터다. 인터럽트가 발생하면, LR_irq 레지스터에 복귀 주소가 저장된다. 그런데, armv7 에서 인터럽트 복귀 주소가 조금 이해하기가 어렵다[참고1 참고2].
- SUBS PC, R14, #4 @ IRQ mode
인터럽트 복귀 주소를 보면 `PC = LR_IRQ - 4` 를 하는 이유가 뭘까? PC 포인터에 next instruction 가 들어있기 때문이다. 즉, R14(LR_IRQ) 에는 PC + 4 가 들어가게 된다. 그런데, 인터럽트는 비동기 메커니즘이다. 즉, 현재 실행중 인 명령어를 멈추고, 인터럽트 루틴을 실행하게 된다. 그렇기 때문에, 복귀 했을 때 이전에 실행중 이던 명령어를 모두 마무리해야 한다. 그런데, 그냥 LR_IRQ 레지스터에 저장된 값으로 복귀해버리면, 이전에 처리중이던 명령어가 skip 되버린다. 그렇기 때문에, 이전 명령어로 복귀하기 위해서 `LR_IRQ - 4` 를 하는 것이다.
그렇다면, 함수는 어떻게 설명할 수 있을까? 중요한 건 `비동기`냐 `동기`냐의 차이다. 인터럽트는 비동기다. 즉, 언제 발생할 지 알 수가 없다. 그러나, 함수는 동기적으로 호출되기 때문에, 현재 실행중 인 명령어가 다 실행되고나서 호출된다. 그렇기 때문에, 다음 명령어로 복귀해도 이상이 없다.
3. IRQ 플래그를 mask 한다. 즉, CPSR.I 를 SET 한다.
4. PC 포인터에 IRQ exception vector 주소를 설정한다." 이 과정은 모두 하드웨어적으로 처리되는 과정이다. exception vector table 에서 ISR 를 실행하는 순간부터는 소프트웨어가 직접 핸들링하게 된다.
- entry point of processing interrupt
" armv7 에서 인터럽트가 발생하면, exception vector table 로 가장 먼저 분기한다. 그 이후, vector_irq 레이블로 분기하게 된다. 그런데, vector_irq 레이블을 어디에도 선언되어 있지 않다. 이 레이블을 찾기 위해서는 vector_stub 매크로에 대해 알아야 한다. vector_stub 매크로는 name, mode, correction 이라는 세 개의 인자를 받아서, vector_irq, vector_und, vector_dabt, vector_pabt 레이블을 생성한다. 예를 들어, `vector_stub irq, IRQ_MODE, 4` 어셈블리어가 치환되면, 오른쪽과 같이 vector_irq 레이블이 생성되는 것을 볼 수 있다.
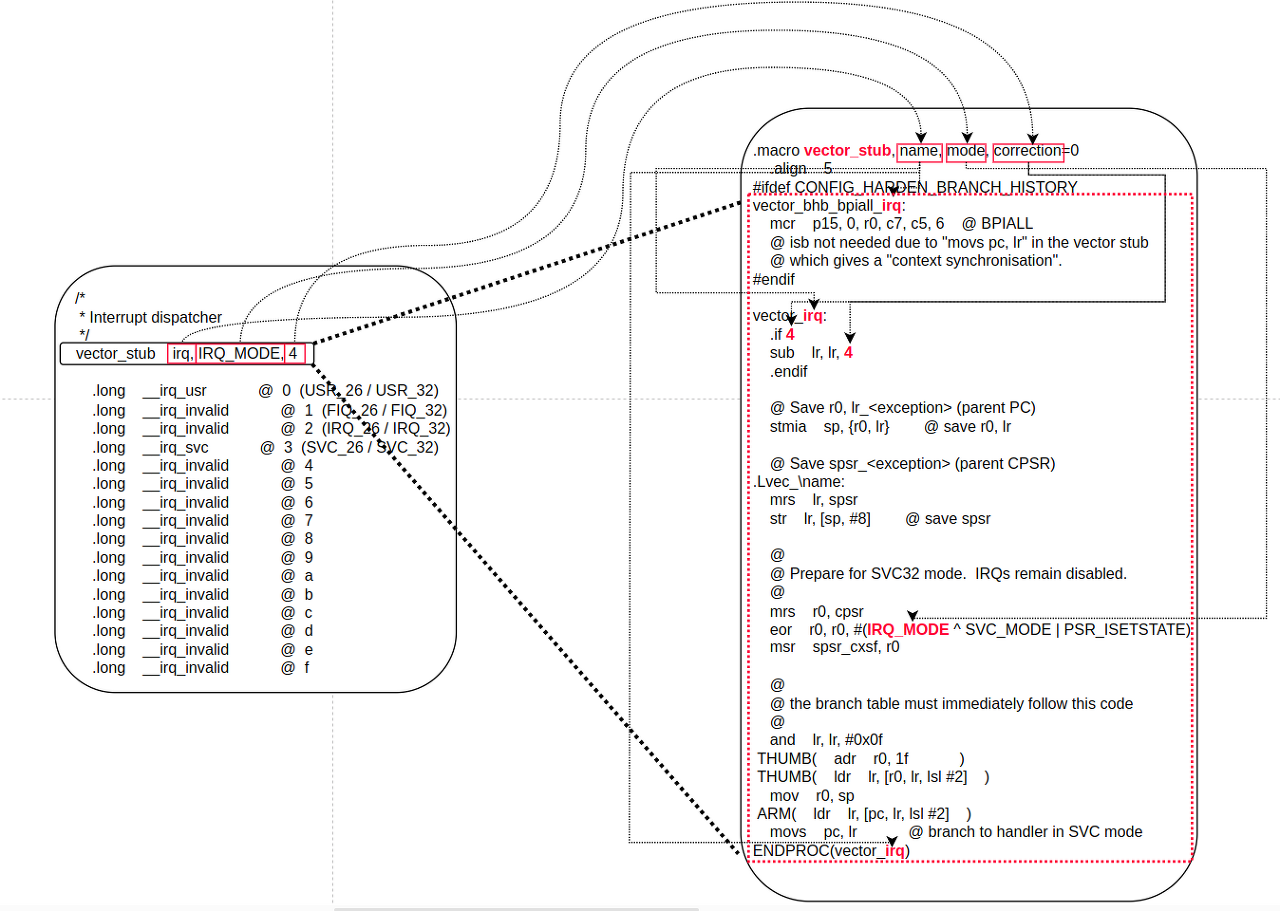
" 각 exception vector 를 생성하는 vector_stub 는 다음과 같다.
// arch/arm/kernel/entry-armv.S - v6.5 /* * Vector stubs. * * This code is copied to 0xffff1000 so we can use branches in the * vectors, rather than ldr's. Note that this code must not exceed * a page size. * * Common stub entry macro: * Enter in IRQ mode, spsr = SVC/USR CPSR, lr = SVC/USR PC * * SP points to a minimal amount of processor-private memory, the address * of which is copied into r0 for the mode specific abort handler. */ .macro vector_stub, name, mode, correction=0 .align 5 .... vector_\name: .if \correction sub lr, lr, #\correction // --- 1 .endif @ Save r0, lr_<exception> (parent PC) stmia sp, {r0, lr} @ save r0, lr // --- 2 @ Save spsr_<exception> (parent CPSR) .Lvec_\name: mrs lr, spsr str lr, [sp, #8] @ save spsr // --- 3 @ @ Prepare for SVC32 mode. IRQs remain disabled. @ mrs r0, cpsr // --- 4 eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE) msr spsr_cxsf, r0 @ @ the branch table must immediately follow this code @ and lr, lr, #0x0f // --- 5 .... mov r0, sp ARM( ldr lr, [pc, lr, lsl #2] ) movs pc, lr @ branch to handler in SVC mode ENDPROC(vector_\name)1. 이전 섹션에서 PC 에 next instruction 이 들어가 있기 때문에, `LR_IRQ - 4` 를 통해 이전에 처리중이던 명령어로 돌아갈 수 있다고 했다.
2. IRQ mode 로 스위칭되면, `sp` 는 암묵적으로 `sp_irq` 로 변경된다. 그리고, 동작 모드에 따른 스택을 초기화할 때, 할당된 16B 를 사용할 수 있게 된다. stmia 명령어는 그림으로 설명하는 것이 빠르다. 근데, r0 은 왜 저장할까?
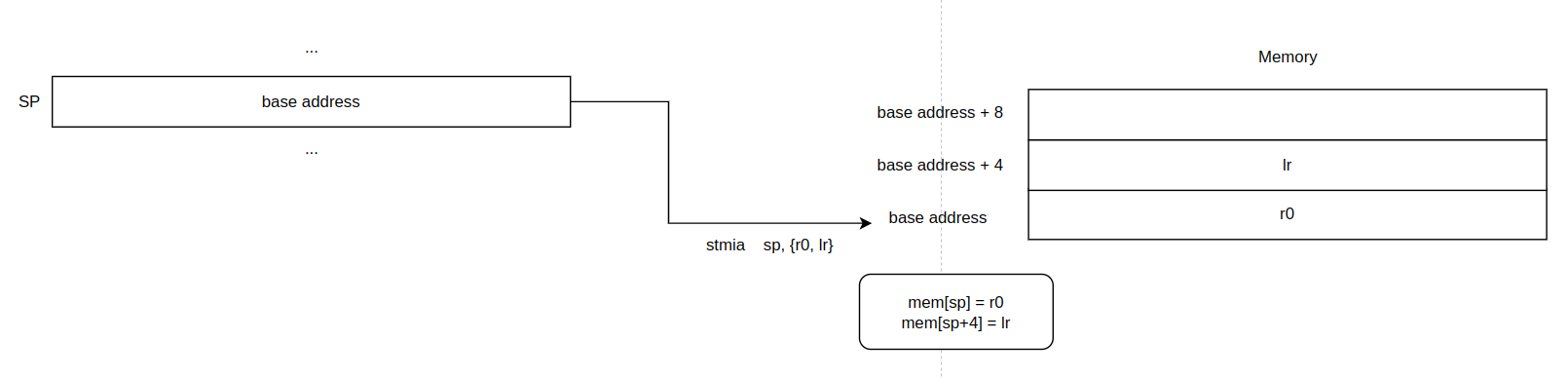
이후에 코드에서 r0 을 사용하기 때문에, r0 의 데이터를 보존하기 위해 stack 에 저장해야 한다. 그런데, 꼭 보존해야 할까? 인터럽트에 의한 선점당했던 실행 컨택스트에서 r0 에 자신만의 데이터를 사용하고 있을 수 있다. 그렇기 때문에, 반드시 사용할 레지스터들은 stack 에 저장해놔야 한다.
3. 이 시점에 spsr(SPSR_irq) 에는 인터럽트가 발생하기전인 CPSR(svc mode or usr mode)가 들어있다. 이 값도 irq stack 에 추가한다.
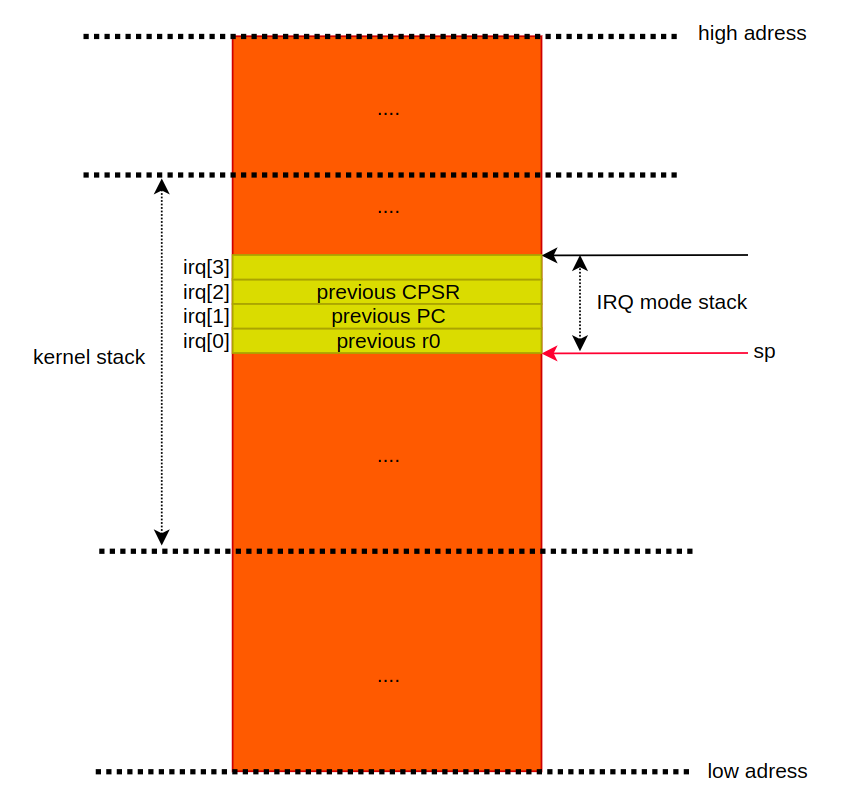
4. spsr 에 IRQ mode 는 없애고, SVC mode 를 추가하는 코드다(배타적 연산은 2번(1. `^` , 2. `eor`) 함으로써 IRQ mode 를 제거한다). 이걸 하는 이유는 arm 이 svc mode 로 전환하기 위해서다. 뒤에서 다시 살펴본다.
5. 이 시점에 lr 레지스터에는 인터럽트가 발생하기 전 cpsr 값이 들어있다. 이 값에 0xf 를 and 연산한다는 것은 CPSR[3:0] 을 추출하겠다는 뜻이고, 이 말은 현재 동작 모드만 lr 에 저장하겠다는 뜻이다. 그런데, CPSR[3:0] 만으로 동작 모드를 판단할 수 있을까? 가능하다. 왜냐면, CPSR[4] 는 무조건 1 이기 때문이다.
" `mov r0, sp` 는 다음에 실행 될 핸들러가 __irq_usr 인지 __irq_svc 인지는 관계없이, 현재 설정된 스택(r0)을 전달하는 것이다.
" `ldr lr, [pc, lr, lsl #2]` 는 현재 동작 모드에 __irq_usr 혹은 __irq_svc 를 lr 에 설정한다. lsl 은 `logical shift left` 의 약자로, 왼쪽으로 쉬프트하는 것을 의미한다[참고1].
- ldr lr, [pc, lr, lsl #2] --> ldr lr, [pc + lr << 2] 라고 볼 수 있다.
" movs pc, lr 를 통해 lr 에 저장된 값을 pc 에 쓴다. lr 에 값에 따라, __irq_usr 혹은 __irq_svc 로 분기한다. 동작 모드는 무조건 svc mode 로 변경된다). 그런데, 동작 모드는 어떻게 변경이 되는 것일까? movs 명령어는 spsr 에 있는 값을 cpsr 에 쓰는 기능이 추가적으로 포함되어 있다(모든 값이 써지는 것은 아니다. 동작 모드 관련된 하위 비트들만 써진다).
2. when an interrupt occurs, the core currently runs in user space
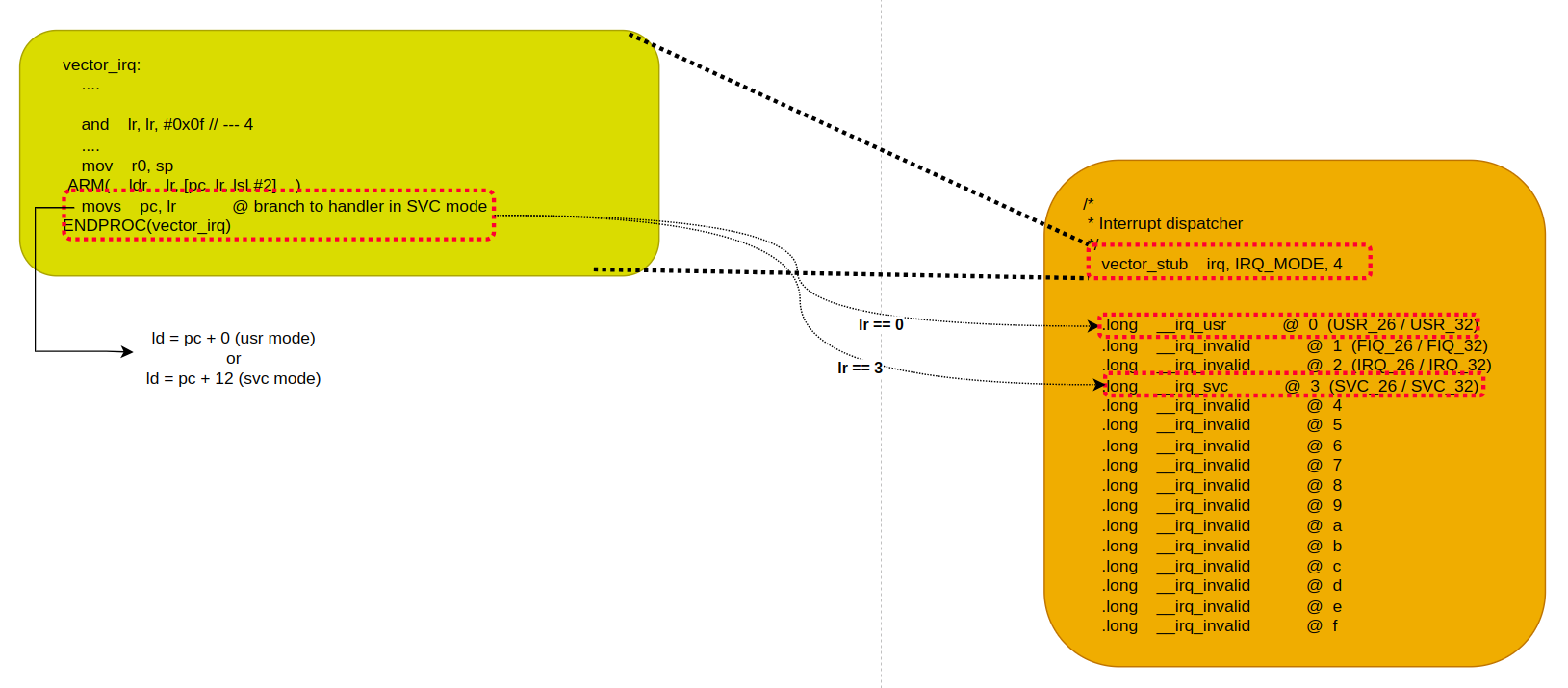
" 인터럽트가 발생했을 때, 실제 코드를 처리하는 핸들러의 위치는 아래와 같다(vector_irq). 즉, user space 에서 인터럽트가 발생했을 경우, __irq_user 로 분기하고, kernel space 에서 인터럽트가 발생했을 경우, __irq_svc 로 분기한다. 엔트리가 16개인 이유는 위에서 CSPR[3:0] 을 기준으로 __irq_usr 로 분기할지, __irq_svc 로 분기할지 판단하기 때문이다(4비트는 총 16개의 엔트리를 생성할 수 있다). 실제 사용되는 엔트리는 2개 뿐이며, 잘못 분기할 경우, __irq_invalid 루틴을 발동하게 구현되어있다(`early_trap_init() 함수에서 봤던 것과 동일하다고 보면 된다).
// arch/arm/kernel/entry-armv.S - v6.5 /* * Interrupt dispatcher */ vector_stub irq, IRQ_MODE, 4 .long __irq_usr @ 0 (USR_26 / USR_32) .long __irq_invalid @ 1 (FIQ_26 / FIQ_32) .long __irq_invalid @ 2 (IRQ_26 / IRQ_32) .long __irq_svc @ 3 (SVC_26 / SVC_32) .long __irq_invalid @ 4 .long __irq_invalid @ 5 .long __irq_invalid @ 6 .long __irq_invalid @ 7 .long __irq_invalid @ 8 .long __irq_invalid @ 9 .long __irq_invalid @ a .long __irq_invalid @ b .long __irq_invalid @ c .long __irq_invalid @ d .long __irq_invalid @ e .long __irq_invalid @ f" user space 에서 인터럽트가 발생할 경우, __irq_usr 레이블로 점프하게 된다. 여기서 부터가 인터럽트 처리의 시작이라고 볼 수 있다. 물론, 본격적인 처리는 irq_handler 에서 시작되지만, 그전까지의 절차는 이전 컨택스트를 스택에 저장하는 작업을 수행한다. 이전 컨택스트를 저장하는 절차에서 3 가지 중요한 포인트가 있다.
1. fiq mode 를 제외한 나머지 동작 모드는 r0 - r12 를 공유한다. 즉, r1 - r12 레지스터는 스택에 저장해놔야 한다.
2. r0 은 irq mode 로 스위칭되면, irq stack 의 주소를 가리킨다. irq stack 에는 user mode 에서 사용하던 r0(orginal r0), lr, cpsr 이 저장된다.
3. banked register`s 는 동작 모드에 따라 Per-CPU 로 가지고 있기 때문에, 스택에 저장할 필요가 없다." __isr_usr 는 user space 에서 발생한 인터럽트 처리를 관장한다고 볼 수 있다. 크게 3 가지 작업으로 나눠볼 수 있다.
1. 이전 컨택스트(usr mode)를 커널 스택에 저장 : usr_entry
2. 실제 인터럽트 처리 : irq_handler
3. 이전 컨택스트(usr mode)로 복귀 : ret_to_user_from_irq// arch/arm/kernel/entry-armv.S - v6.5 .align 5 __irq_usr: usr_entry // --- 1 kuser_cmpxchg_check irq_handler from_user=1 get_thread_info tsk mov why, #0 b ret_to_user_from_irq UNWIND(.fnend ) ENDPROC(__irq_usr)" 이전 컨택스트에서 실행중이던 커널 스레드의 정보를 r9 레지스터에 저장한다. 이 정보는 ret_to_user_from_irq 에 전달된다.
" `why` 는 r8 레지스터를 의미한다. r8 레지스터는 뒤에 `ret_to_user_form_irq` 핸들러에게 전달되는 파라미터다. r8 레지스터는 시스템 콜 번호를 의미하는데, 지금은 인터럽트 핸들링이기 때문에 `0` 을 던지다(`0` 은 hw 인터럽트가 발생했다는 것을 의미한다. 즉, 시스템 콜과는 완전히 별개의 프로세스라는 것을 알린다).
(1) user_entry 는 이전 컨택스트(usr mode)를 커널 스택에 저장하는 역할을 한다.
// arch/arm/kernel/entry-armv.S - v6.5 .macro usr_entry, trace=1, uaccess=1 UNWIND(.fnstart ) UNWIND(.cantunwind ) @ don't unwind the user space sub sp, sp, #PT_REGS_SIZE // --- 1 ARM( stmib sp, {r1 - r12} ) // --- 2 .... ldmia r0, {r3 - r5} // --- 3 add r0, sp, #S_PC @ here for interlock avoidance // --- 4 mov r6, #-1 @ "" "" "" "" // --- 5 str r3, [sp] @ save the "real" r0 copied // --- 5 @ from the exception stack ATRAP( ldr r8, [r8, #0]) @ @ We are now ready to fill in the remaining blanks on the stack: @ @ r4 - lr_<exception>, already fixed up for correct return/restart @ r5 - spsr_<exception> @ r6 - orig_r0 (see pt_regs definition in ptrace.h) @ @ Also, separately save sp_usr and lr_usr @ stmia r0, {r4 - r6} // --- 6 ARM( stmdb r0, {sp, lr}^ ) // --- 7 .... .endm1. 재미있는 건 아직 이시점까지도 이전 컨택스트에 정보를 스택에 저장하지 않았다는 것이다. 애초에 각 모드마다 스택을 너무 적게 할당되어서 이전 컨택스트를 저장할 수 가 없다. 그래서, 스택을 많이 사용할 수 있는 svc mode 로 전환한 후에, 컨택스트를 저장한다. 위에서 `movs pc, lr` 을 통해서 이 시점에는 이미 svc mode 이고, sp 도 sp_svc 가 된 상태이다. 즉, 이제부터는 커널 스택을 사용하는 것이다.
// arch/arm/kernel/asm-offsets.c - v6.5 DEFINE(PT_REGS_SIZE, sizeof(struct pt_regs));// linux/arch/arm/include/asm/ptrace.h - v6.5 struct pt_regs { unsigned long uregs[18]; };
" 그런데, 컨택스트는 얼마나 저장해야 할까? PT_REGS_SIZE 사이즈만큼만 저장한다. 이 사이즈는 실체는 `struct pt_regs` 이다.
2. 먼저 r1 ~ r12 를 스택에 푸쉬한다. 그런데, r0 은 왜 안넣을까? r0 은 지금 막 사용하는 용도로 쓰이고 있다. 그래서, r0 의 값은 의미가 없다. 이전 컨택스트에서 사용했던 r0 값은 IRQ mode 스택에 이미 들어가있다(`vector_irq` 레이블에서 우리가 했던 일을 떠올려 보자).
" stmib 에서 `ib` 는 `increment before` 이다. 즉, 값을 메모리에 쓰기전에 먼저 주소를 증가시킨뒤, 값을 쓰겠다는 뜻이다(`vector_irq` 레이블에서 설명한 stmia 명령어와 비교해보자). 결국, `stmib sp, {r1-r12}` 는 r0 의 자리는 비워놓고 스택에 레지스터를 쓰게된다. stmib 명령어에 `!` 가 사용되지 않았으므로, sp 의 위치는 업데이트되지 않는다. 즉, 기존 주소를 그대로 유지한다. 만약, 명령어 수행후에 주소를 업데이트하고 싶다면, `stmia sp!, {r1-r12}` 처럼 사용하면 된다.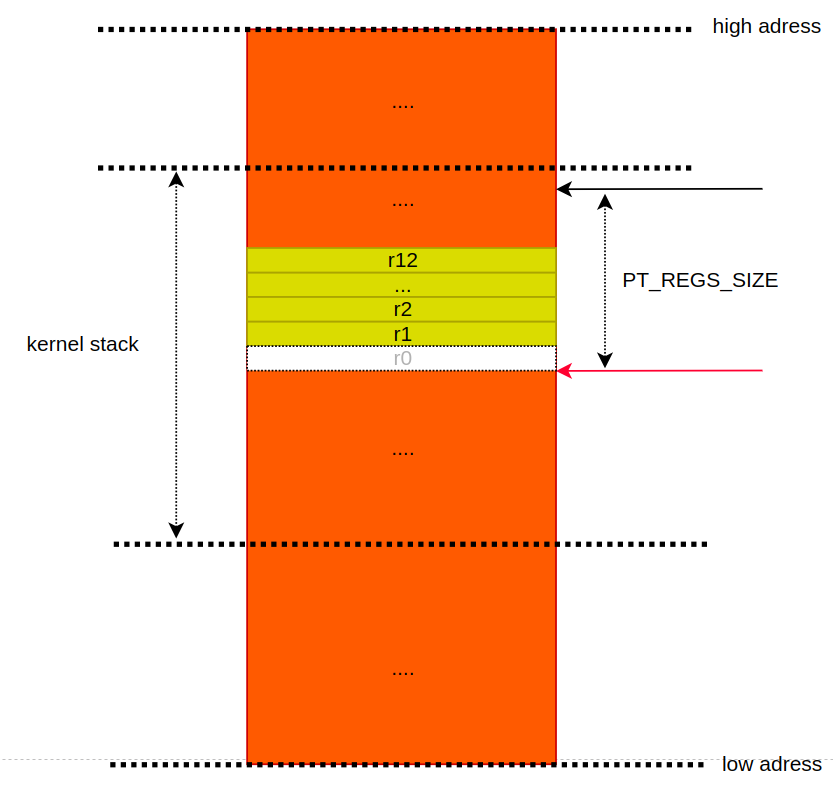
3. vector_irq 에서 r0 에 irq stack 을 저장했다. ldmia 는 stmia 와 반대로 역할을 하는 명령어다. 해당 코드를 통해 아래의 과정이 수행된다. 이걸 수행하는 이 정보를 커널 스택에 저장하기 위해서다.
1. r3 = r0 + 0 (r0)
2. r4 = r0 + 4 (PC)
3. r5 = r0 + 5 (CPSR)
4. S_PC 는 struct pt_regs 구조체의 특정 위치를 가리킨다. struct pt_regs 구조체는 exception 이 발생할 때, 스택에 저장해야 할 이전 컨택스트 정보를 표현하는 구조체를 의미한다.
// arch/arm/kernel/asm-offsets.c - v6.5 .... DEFINE(S_R0, offsetof(struct pt_regs, ARM_r0)); DEFINE(S_R1, offsetof(struct pt_regs, ARM_r1)); DEFINE(S_R2, offsetof(struct pt_regs, ARM_r2)); DEFINE(S_R3, offsetof(struct pt_regs, ARM_r3)); DEFINE(S_R4, offsetof(struct pt_regs, ARM_r4)); DEFINE(S_R5, offsetof(struct pt_regs, ARM_r5)); DEFINE(S_R6, offsetof(struct pt_regs, ARM_r6)); DEFINE(S_R7, offsetof(struct pt_regs, ARM_r7)); DEFINE(S_R8, offsetof(struct pt_regs, ARM_r8)); DEFINE(S_R9, offsetof(struct pt_regs, ARM_r9)); DEFINE(S_R10, offsetof(struct pt_regs, ARM_r10)); DEFINE(S_FP, offsetof(struct pt_regs, ARM_fp)); DEFINE(S_IP, offsetof(struct pt_regs, ARM_ip)); <--- 현재까지 저장된 컨택스트 위치 DEFINE(S_SP, offsetof(struct pt_regs, ARM_sp)); DEFINE(S_LR, offsetof(struct pt_regs, ARM_lr)); DEFINE(S_PC, offsetof(struct pt_regs, ARM_pc)); <--- add r0, sp #S_PC 를 수행하면, r0 은 여리기를 가리킴 DEFINE(S_PSR, offsetof(struct pt_regs, ARM_cpsr)); DEFINE(S_OLD_R0, offsetof(struct pt_regs, ARM_ORIG_r0)); DEFINE(PT_REGS_SIZE, sizeof(struct pt_regs)); ....
" 그런데, 왜 sp 를 바꾸지 않고 r0 을 통해서 스택을 조작할까? stack base line 을 유지하고 싶기 때문이다. x86 에서도 이와 유사한 개념으로 bp 레지스터가 있다. 이 레지스터를 통해서 이전 컨택스트로 복귀하기가 수월해진다. 현재 커널 스택의 상태는 다음과 같다.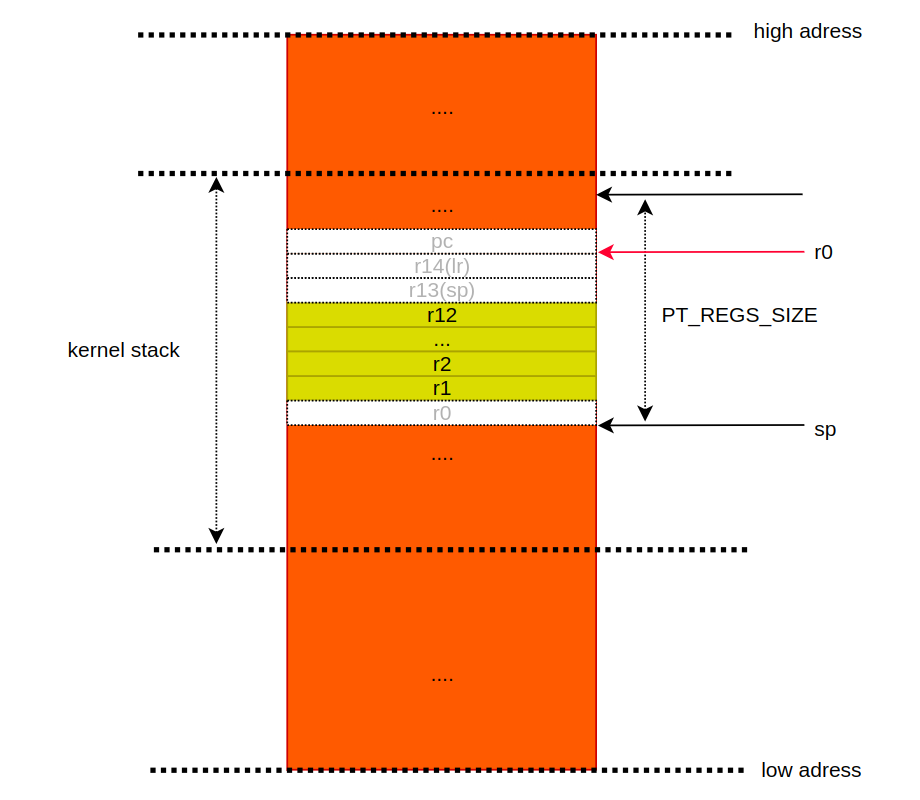
5. r6 에 -1 을 넣는다. 즉, orig_r0 에 -1 을 넣는다. 왜 그럴까? 그리고, 오리지널 r0 은 r3 에 저장되어 있지 않나? 이 섹션의 마지막에서 설명한다. `str r3, [sp]` 은 r3 의 값 (기존 r0) 을 sp 가 가리키는 주소의 값으로 사용한다는 것을 의미한다. 즉, `[]` 는 포인터의 * 와 같다고 보면된다. 어셈블리어는 `[]` 가 없으면, 무조건 주소다. 만약, `str r3, sp` 가 되면, sp 의 주소가 바뀌게 된다. 여기까지 진행한 뒤, 커널 스택은 다음과 같다.
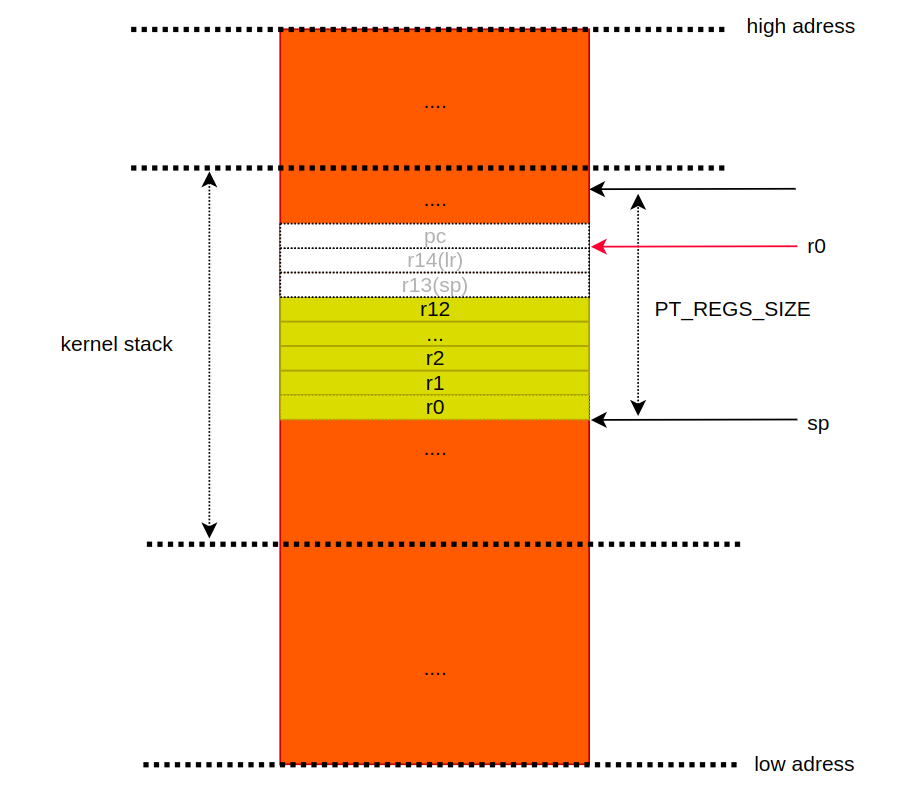
6. 이제 irq stack 에 저장해놨던 이전 컨택스트(r0, pc, cpsr)를 svc stack 에 저장해야 한다. armv7 은 IRQ mode 를 거의 사용하지 않기 때문에, svc 에서 모든 것을 처리한다. 이전 상태로의 복귀 또한 svc mode 에서 이루어진다.
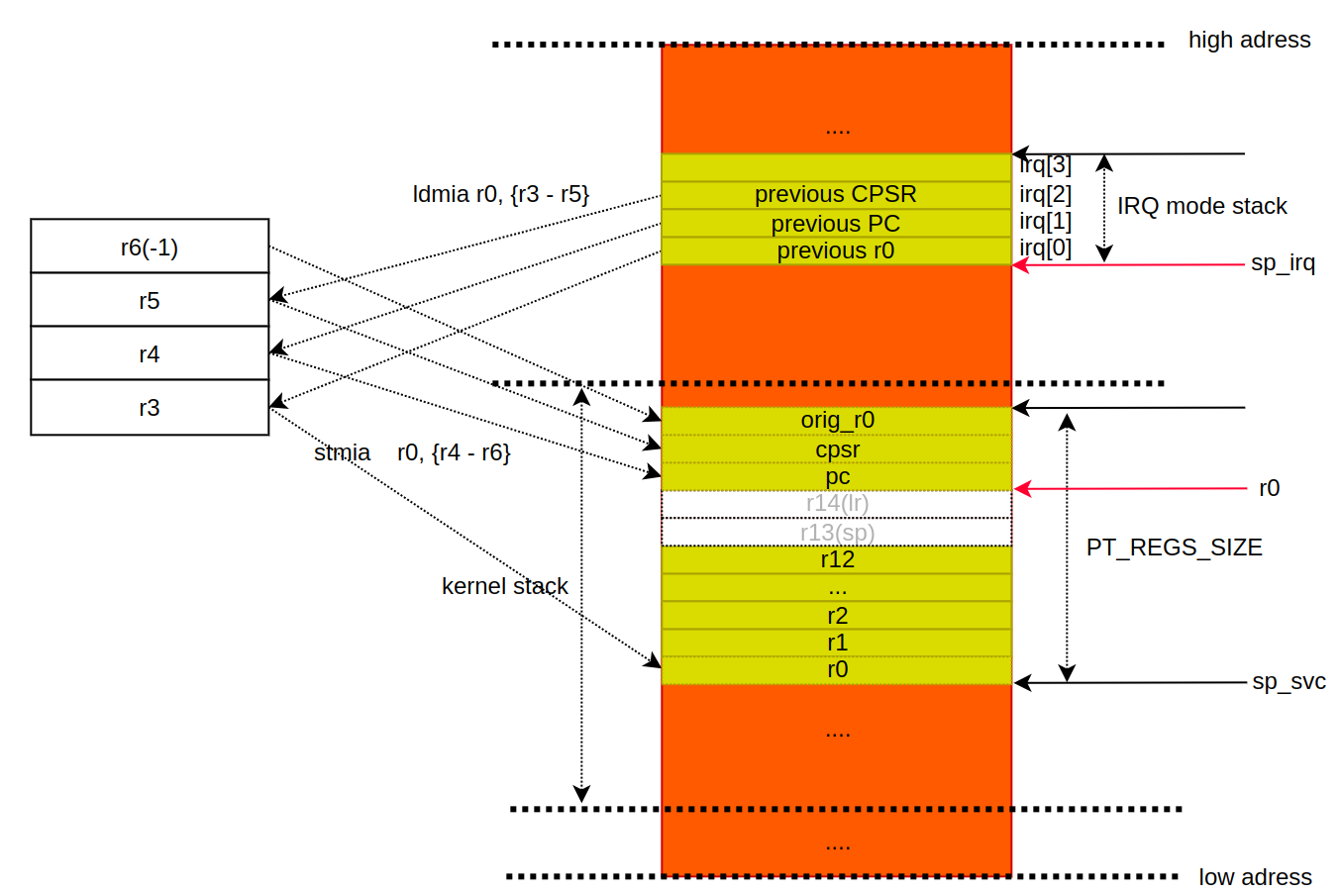
7. 이제 2개만 저장하면 된다. 바로 인터럽트가 발생했을 때의 lr 과 sp 다. 즉, 유저 모드의 lr 과 sp 다. 유저 모드에 접근하기 위해서는 `^` 를 사용해야 한다[참고1]. `stmdb r0, {sp, lr}^` 명령어는 주소를 먼저 내려간 뒤에 값을 쓰는 명령어다. 절차는 다음과 같다(x86 같은 경우는 이전 컨택스트의 sp 를 스택에 자동으로 넣어주지만, arm 은 수동으로 직접 넣어야 한다).
1. 유저 모드 레지스터에 접근
" stmdb r0, {sp, lr}^ ---> stmdb r0, {sp_usr, lr_usr}
2. 주소 먼저 감소한 뒤, 유저 sp, lr 저장 : 주의할 점이 있다. stmdb 는 뒤에 값부터 먼저 저장한다[참고1].
2.1 r0(pc) - 4 = lr_usr
2.2 r0(pc) - 8 = sp_usr2. interrupt core processing
" 이제까지는 이전 컨택스트를 svc stack 에 저장하는 절차였다. 이제 본격적으로 인터럽트를 처리할 수 있는 준비 단계가 완료된 셈이다. 실제 인터럽트 처리 엔트리 포인트는 `irq_handler` 다. irq_handler 가 인터럽트를 처리하는 방식은 2가지가 있다.
1. CONFIG_MULTI_IRQ_HANDLER 가 설정된 경우 : low-level IRQ handler 를 runtime 시에 변경이 가능하다.
2. CONFIG_MULTI_IRQ_HANDLER 가 설정되지 않은 경우 : 위에 내용을 허용하지 않고, arch_irq_handler_default 가 low level IRQ handler 로 사용된다.// arch/arm/kernel/entry-armv.S - v6.5 /* * Interrupt handling. */ .macro irq_handler #ifdef CONFIG_GENERIC_IRQ_MULTI_HANDLER ldr r1, =handle_arch_irq mov r0, sp badr lr, 9997f ldr pc, [r1] #else arch_irq_handler_default #endif 9997: .endm" 현재 arch_irq_handler_default 를 사용하지 않는다[참고1]. 그 이유는 여러 가지가 있지만, 가장 큰 요인은 arch_irq_handler_default 핸들러가 HW interrupt number 를 IRQ number 로 매핑하는데 있어서, SoC 구조를 생각하지 않는다는 것이다. 즉, arch_irq_handler_default 핸들러는 SoC 에 interrupt controller 가 1개 라고 가정한다. 그리고, hw interrupt number 와 IRQ number 의 매핑 관계도 상당히 단순한 방식으로 매핑한다. 그러나, 현재 arm 아키텍처의 인터럽트 시스템은 상당히 복잡하다. 다수의 hw interrupt number 를 IRQ number 로 매핑하기 위해 interrupt controller casecade, irq domain 등과 같은 복잡한 개념이 추가되었다. 그렇기 때문에, 유연한 설계에 맞춰서 소프트웨어도 유연하게 변경될 수 있어야 한다. 그러므로, (2) 번 방식을 권고되고 있다.
" GENERIC_IRQ_MULTI_HANDLER 컨피그는 `/arch/arm/Kconfig` 파일에 default 로 선언되어 있다. handle_arch_irq 는 함수 포인터로 선언되서 동적으로 변경이 가능하다. arm 에서 handle_arch_irq 가 설정되는 경우는 2가지가 있다. 첫 번째로, 시스템에 내에 다수의 인터럽트 컨트롤러가 존재할 경우, 예를 들어, 인터럽트를 지원하는 GPIO controller 와 interrupt controller 가 있는 경우다. 두 번째로, SoC 내에 인터럽트 컨트롤러 하나만 존재하는 경우다. 더 구체적인 내용은 다른 문서에서 다루도록 하겠다.
" 벤더사에서 자체 인터럽트 컨트롤러를 만들어서 low-level IRQ handling 을 하고 싶다면, set_handle_irq() 함수에 자신들이 작성한 handle_arch_irq 함수를 전달하면 된다. `irq_handler` 에서 인자로 sp 를 전달하는 이유는 `struct pt_regs` 를 제공하기 위해서임을 알 수 있다. 주로, irqchip driver 에서 set_handle_irq() 함수를 호출하는 것을 볼 수 있다. gic 또한 irqchip driver 로 구현된다.
// include/linux/irq.h - v6.5 #ifdef CONFIG_GENERIC_IRQ_MULTI_HANDLER /* * Registers a generic IRQ handling function as the top-level IRQ handler in * the system, which is generally the first C code called from an assembly * architecture-specific interrupt handler. * * Returns 0 on success, or -EBUSY if an IRQ handler has already been * registered. */ int __init set_handle_irq(void (*handle_irq)(struct pt_regs *)); /* * Allows interrupt handlers to find the irqchip that's been registered as the * top-level IRQ handler. */ extern void (*handle_arch_irq)(struct pt_regs *) __ro_after_init; #endif// kernel/irq/handle.c - v6.5 #ifdef CONFIG_GENERIC_IRQ_MULTI_HANDLER int __init set_handle_irq(void (*handle_irq)(struct pt_regs *)) { if (handle_arch_irq) return -EBUSY; handle_arch_irq = handle_irq; return 0; } #endif" 이 섹션을 마치기 전에 인터럽트와 스택에 대해 주의할 점이 하나있다. irq_handler 레이블에서 handle_arch_irq 핸들러에게 sp 를 인자로 전달하고 있다. 그런데, 이 sp 가 가리키는 스택의 출처는 어딜까? 인터럽트가 발생하면, user space 건 kernel space 건 관계없이 무조건 svc mode 로 전환한다. 그리고, svc mode 에서 실제 인터럽트 처리 과정이 수행된다. 그렇다면, 인터럽트 발생 전 svc mode 의 sp 를 사용해서 인터럽트를 처리한다는 뜻인데, svc mode 가 커널과 동의어이기 때문에, 다시 해석하면, kernel space 의 스택을 사용해서 인터럽트를 처리한다는 뜻이 된다.
" 그런데, 운영 체제는 메모리 관리 및 작업의 `단위` 를 프로세스 및 스레드로 정한다. 즉, 운영 체제는 사소한 일을 처리 하더라도 반드시 스레드를 통해서 해당 작업을 한다는 것이다. 이 말은 비동기적인 인터럽트가 발생했을 때도, 임의의 스레드가 동작하고 있다는 뜻이 된다. 이 때, 인터럽트 핸들러는 이전 컨택스트의 스레드의 스택을 빌려서 작업을 처리하게 된다. 즉, 인터럽트를 위한 특별한 스택이 존재하는 것은 아니다.
" 문제가 되지는 않을까? interrupt nesting 을 지원하지 않는다면, interrupt handling 에서 스택을 많이 사용할 이유가 없기 때문에 stackoverflow 를 걱정할 필요는 없다고 본다(그러나, x86_64 에서는 `IST` 라는 하드웨어 아키텍처를 도입해서 인터럽트가 발생할 때 마다, CPU 마다 7 개의 별도의 인터럽트 처리 스택을 제공할 수 있다).
3. interrupt processing when an interrut occured in kernel space
" kernel space 에서 인터럽트가 발생하면, __irq_svc 로 점프하게 된다.
// arch/arm/kernel/entry-armv.S - v6.5 .align 5 __irq_svc: svc_entry // --- 1 irq_handler // --- 2 #ifdef CONFIG_PREEMPT // --- 3 ldr r8, [tsk, #TI_PREEMPT] @ get preempt count ldr r0, [tsk, #TI_FLAGS] @ get flags teq r8, #0 @ if preempt count != 0 movne r0, #0 @ force flags to 0 tst r0, #_TIF_NEED_RESCHED blne svc_preempt #endif svc_exit r5, irq = 1 @ return from exception UNWIND(.fnend ) ENDPROC(__irq_svc)1. 커널 스택에 이전 컨택스트 정보를 저장한다.
2. 커널 모드 또한 인터럽트 처리 절차는 user mode 에서 했던 것과 같이 irq_handler 를 호출해서 처리한다.
3. 리눅스 커널이 선점형을 지원하기 전에는 시스템 콜이 리턴되는 시점에만 스케줄링이 필요한지 검사(need_resched)해서 유저 프로세스를 선점했었다. 그러나, preemption 을 지원하면서 re-scheduling path 가 굉장히 많아졌다. 그 중에 하나가 `kernel space 에서 인터럽트가 발생해서 kenrel space 로 복귀` 하는 시점 이다. 이 프로세스를 이해하기 위해서 먼저 struct thread_info 구조체를 살펴봐야 한다.
// arch/arm/include/asm/thread_info.h - v6.5 /* * low level task data that entry.S needs immediate access to. * __switch_to() assumes cpu_context follows immediately after cpu_domain. */ struct thread_info { unsigned long flags; /* low level flags */ int preempt_count; /* 0 => preemptable, <0 => bug */ .... };
" flags 는 일반적으로 task 의 상태를 나타낸다. 그리고, preemt_count 는 preemption 이 가능한지를 나타낸다. 이 값이 0 이 아니면, preemption 이 불가능 하다는 것을 의미한다. 즉, 선점이 불가능하다. 그러므로, 이전 컨택스트로 복귀한다. preemt_count 가 0 이 아닌 경우는 preempt_disable() 함수를 호출했거나(주로, lock 을 소유할 경우), interrut context 내에 있을 경우를 들 수 있다. 만약, preempt_count 가 0 이면, preemption 조건이 충족된 것이다. 그러나, 이것만으로 선점이 불가능하다. 현재 thread_info.flags 에 _TIF_NEED_RESCHED 가 SET 되어 있어야 선점이 가능하다(현재 태스크가 time slice 를 모두 소진했거나, 자신보다 높은 우선 순위의 태스크가 wake-up 했을 경우). 즉, `preempt_count == 0 && _TIF_NEED_RESCHED` 가 참이여야 preemption 이 가능하다." kernel space 에서 인터럽트가 발생했을 때, 인터럽트 처리 절차에서 svc_entry 는 irq_handler 전에 호출된다. 이 말은 svc entry 도 실제 인터럽트 처리 절차는 아니며, 이전 svc 컨택스트를 스택에 역할을 맡고있다는 것을 알 수 있다.
//arch/arm/kernel/entry-armv.S - v6.5 .macro svc_entry, stack_hole=0, trace=1, uaccess=1 UNWIND(.fnstart ) UNWIND(.save {r0 - pc} ) sub sp, sp, #(SVC_REGS_SIZE + \stack_hole - 4) // --- 1 .... stmia sp, {r1 - r12} // --- 2 ldmia r0, {r3 - r5} // --- 2 add r7, sp, #S_SP - 4 @ here for interlock avoidance // --- 3 mov r6, #-1 @ "" "" "" "" // --- 2 add r2, sp, #(SVC_REGS_SIZE + \stack_hole - 4) // --- 4 .... str r3, [sp, #-4]! @ save the "real" r0 copied // --- 2 @ from the exception stack mov r3, lr // --- 2 @ @ We are now ready to fill in the remaining blanks on the stack: @ @ r2 - sp_svc @ r3 - lr_svc @ r4 - lr_<exception>, already fixed up for correct return/restart @ r5 - spsr_<exception> @ r6 - orig_r0 (see pt_regs definition in ptrace.h) @ stmia r7, {r2 - r6} // --- 2 .... .endm// linux/arch/arm/include/asm/ptrace.h - v6.5 struct svc_pt_regs { struct pt_regs regs; u32 dacr; };1. `-4` 를 빼는 이유는 sp 가 r1 을 바라보게 하기 위해서다. 아래 그림을 참고하자.
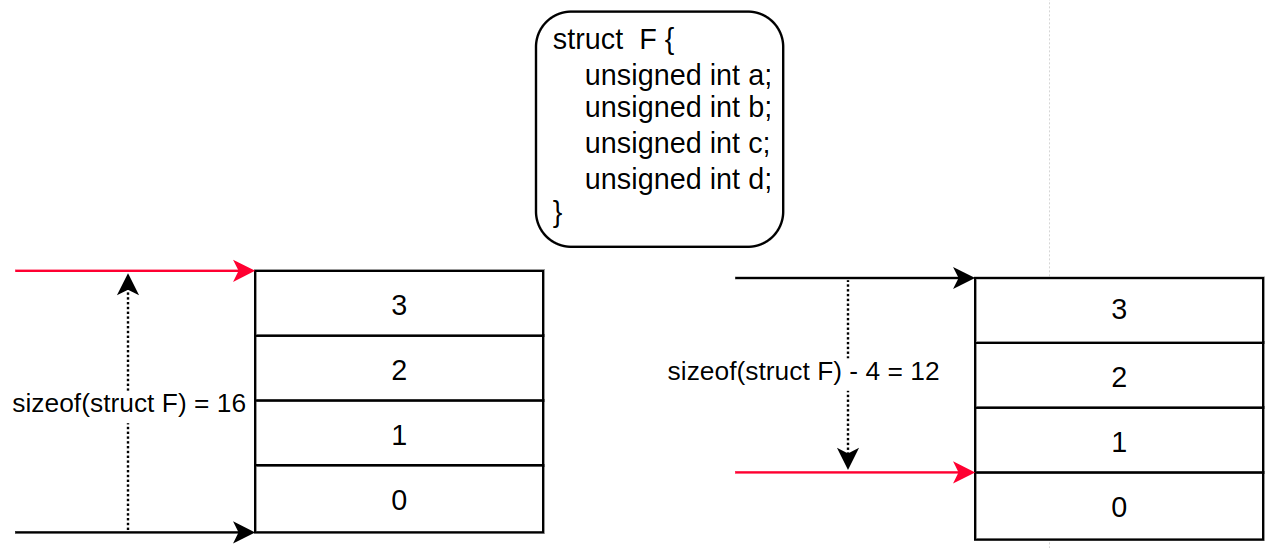
2. user_entry 참고.
3. r7 이 가리키는 곳을 스택에 저장된 r12 를 바라보게 만든다.
// arch/arm/kernel/asm-offsets.c - v6.5 .... DEFINE(S_R0, offsetof(struct pt_regs, ARM_r0)); DEFINE(S_R1, offsetof(struct pt_regs, ARM_r1)); DEFINE(S_R2, offsetof(struct pt_regs, ARM_r2)); DEFINE(S_R3, offsetof(struct pt_regs, ARM_r3)); DEFINE(S_R4, offsetof(struct pt_regs, ARM_r4)); DEFINE(S_R5, offsetof(struct pt_regs, ARM_r5)); DEFINE(S_R6, offsetof(struct pt_regs, ARM_r6)); DEFINE(S_R7, offsetof(struct pt_regs, ARM_r7)); DEFINE(S_R8, offsetof(struct pt_regs, ARM_r8)); DEFINE(S_R9, offsetof(struct pt_regs, ARM_r9)); DEFINE(S_R10, offsetof(struct pt_regs, ARM_r10)); DEFINE(S_FP, offsetof(struct pt_regs, ARM_fp)); DEFINE(S_IP, offsetof(struct pt_regs, ARM_ip)); <--- add r0, sp #S_SP-4 : r0 이 가리키는 위치 DEFINE(S_SP, offsetof(struct pt_regs, ARM_sp)); DEFINE(S_LR, offsetof(struct pt_regs, ARM_lr)); DEFINE(S_PC, offsetof(struct pt_regs, ARM_pc)); DEFINE(S_PSR, offsetof(struct pt_regs, ARM_cpsr)); DEFINE(S_OLD_R0, offsetof(struct pt_regs, ARM_ORIG_r0)); DEFINE(PT_REGS_SIZE, sizeof(struct pt_regs)); ....
4. r2 에 svc_entry 가 최초로 호출되었을 때, sp 포인터의 위치를 저장한다. 즉, 이전 svc 스택 포인터를 r2 에 저장한다." 그런데, usr_entry / svc_entry 모두 r0 과 orig_r0 을 커널 스택에 저장한다. 그렇다면, 2 개의 차이가 뭘까? 그리고, 왜 orig_r0 에 -1 을 저장할까? 이걸 이해하기 위해서는 `system call` 에 대해서 알아야 한다. system call 과 interrupt 는 모두 CPU exception 이라는 범위안에 속하지만, 차이점이 있다면, system call 은 return value 와 parameter 가 존재한다는 것이다. 파라미터는 왜 전달해야할까? arm 같은 경우는, 함수 호출 규약에서 파라미터를 전달할 때, 레지스터를 통해서 전달하도록 하고 있다(r0 은 첫 번째 파라미터). 거기다가, return value 는 또한 r0 레지스터를 통해서 전달된다(x86 같은 경우는 스택을 통해 전달하고, x86_64 는 레지스터를 통해 전달. 참고로, 레지스터를 통한 전달이 스택보다 빠르다).
" arm 에서 파라미터를 전달할 때, r0 ~ r7 레지스터를 사용하는데, 이 레지스터들은 동작 모드에 관계없이 모든 CPU 가 공유하는 레지스터들이다. 그래서, system call 시에 usr mode -> svc mode 로 가더라도, 파라미터의 값이 유지될 수 있다. 그런데, system call 도 mode switching 을 유발하기 때문에, 이전 컨택스트를 정상적으로 복귀 및 복구하기 위해서 이전 컨택스트를 스택에 저장해놔야 한다. 이 때, r0 이 parameter 와 return value 로 2 개 모두로 사용되다보니 스택에도 2 번을 저장해야 하는 것이다. 인터럽트는 이것과는 관계가없다. 그래서 ARM_ORIG_r0 에 -1 을 저장한다.
- Interrupt return process
1. return to user
" usr mode 에서 인터럽트가 발생하고 다시 복귀하는 프로세스는 `ret_to_user_from_irq` 에서 수행한다.
// arch/arm/kernel/entry-common.S - v6.5 ENTRY(ret_to_user_from_irq) ldr r1, [tsk, #TI_FLAGS] movs r1, r1, lsl #16 // --- 1 bne slow_work_pending no_work_pending: asm_trace_hardirqs_on save = 0 ct_user_enter save = 0 restore_user_regs fast = 0, offset = 0 ENDPROC(ret_to_user_from_irq)(1) 복잡한 코드다. 이 명령어를 직접 해석하는 것은 쉽지 않다(이 사이트를 참고하자). 이전 패치를 찾아봤는데, `tst r1, #_TIF_WORK_MASK` 명령어와 동일하다는 것을 알게됬다[참고1]. 즉, _TIF_WORK_MASK 는 re-scheduling 과 관련되어 있다.
// arch/arm/include/asm/thread_info.h - v6.5 * * Change these and you break ASM code in entry-common.S */ #define _TIF_WORK_MASK (_TIF_NEED_RESCHED | _TIF_SIGPENDING | \ _TIF_NOTIFY_RESUME | _TIF_UPROBE | \ _TIF_NOTIFY_SIGNAL)
" 위에 플래그중 하나라도 SET 되어있으면, slow_work_pending 으로 branch 하게 된다. 가장 중요한 2개의 플래그는 _TIF_NEED_RESCHED 와 _TIF_SIGPENDING 이다. 현재 프로세스에 _TIF_NEED_RESCHED 플래그가 SET 되어있으면, 스케줄링이 필요하다는 뜻이다. 만약, _TIF_SIGPENDING 가 SET 되어있으면, pending signal 이 있기 때문에 해당 요청을 처리하기 위해 스케줄링이 필요하다는 뜻이다." slow_work_pending 에서 핵심 함수는 do_work_pending 이다. 3개의 인자가 전달되는데, 다음과 같다. 첫 번째는 usr mode 의 이전 컨택스트 정보(r0) 다. 두번 째는 struct thread_info(r1)이 전달된다. 그리고, syscall(r2) 이 전달된다. 그런데, syscall 은 뭘까? `why` 는 r8 레지스터를 의미한다. 즉, r8 레지스터에 0 을 넣는다. __irq_usr 는 유저 모드에서 인터럽트가 발생했다는 것을 의미한다. 즉, syscall 은 시스템 콜이 호출될 경우에는 `1` 로 설정되고, 인터럽트가 발생한 경우에는 `0` 으로 설정된다.
/arch/arm/kernel/entry-armv.S __irq_usr: .... mov why, #0 b ret_to_user_from_irq ....// arch/arm/kernel/entry-common.S - v6.5 slow_work_pending: mov r0, sp @ 'regs' mov r2, why @ 'syscall' bl do_work_pending cmp r0, #0 beq no_work_pending movlt scno, #(__NR_restart_syscall - __NR_SYSCALL_BASE) ldmia sp, {r0 - r6} @ have to reload r0 - r6 b local_restart @ ... and off we go ...." do_work_pending() 함수는 크게 2가지 기능을 수행한다.
1. 현재 스레드에 _TIF_NEED_RESCHED 플래그가 SET 되어있으면, 즉각적으로 schedule() 함수를 호출한다.
2. 그외에는 3 가지 경우로 나눠볼 수 있다.
- 먼저, _TIF_NEED_SIGPENDING 플래그 SET 되어있으면, 현재 프로세스가 signal 을 받았다는 뜻이므로, do_signal() 함수를 호출해서 pending signal 을 처리하도록 한다.
- 두 번째로, _TIF_UPROBE 플래그가 SET 되어있는 경우. 주로, uprobe 를 통해 breakpoint / singlestep 디버깅을 하기 위한 경우라고 보면된다[참고1 참고2]
- 세 번째로, 위에 2개를 제외한 _TIF_WORK_MASK 에서 설정된 나머지 플래그가 SET된 경우(대개는 _TIF_NOTIFY_RESUME 플래그가 SET 됨). resume_user_mode_work() 함수는 `task_work` 라는 메커니즘을 사용한다[참고1]// arch/arm/kernel/signal.c - v6.5 asmlinkage int do_work_pending(struct pt_regs *regs, unsigned int thread_flags, int syscall) { .... do { if (likely(thread_flags & _TIF_NEED_RESCHED)) { schedule(); } else { if (unlikely(!user_mode(regs))) return 0; .... if (thread_flags & (_TIF_SIGPENDING | _TIF_NOTIFY_SIGNAL)) { int restart = do_signal(regs, syscall); .... } else if (thread_flags & _TIF_UPROBE) { uprobe_notify_resume(regs); } else { resume_user_mode_work(regs); } } .... thread_flags = read_thread_flags(); } while (thread_flags & _TIF_WORK_MASK); return 0; }" do_work_pending() 함수의 종료 조건은 _TIF_WORK_MASK 에 걸리는게 없어야 한다. pending work 가 모두 마무리되면(_TIF_WORK_MASK 에 걸리는게 없다면), do_work_pending() 함수는 `0` 을 반환한다. 그리고, do_work_pending() 함수가 0 을 반환하면, no_work_pending 으로 branch 하게 된다(`cmp r0, #0; beq no_work_pending;`).
(2) 만약, re-scheduling 관련 작업을 수행할 필요없다면, `restore_user_regs` 로 브랜치해서 이전 컨택스트(usr mode)를 복구하는 작업을 수행한다.
// arch/arm/kernel/entry-header.S - v6.5 .macro restore_user_regs, fast = 0, offset = 0 .... uaccess_enable r1, isb=0 #ifndef CONFIG_THUMB2_KERNEL @ ARM mode restore mov r2, sp // --- 1 ldr r1, [r2, #\offset + S_PSR] @ get calling cpsr // --- 1 ldr lr, [r2, #\offset + S_PC]! @ get pc // --- 1 .... msr spsr_cxsf, r1 @ save in spsr_svc // --- 2 .... .if \fast ldmdb r2, {r1 - lr}^ @ get calling r1 - lr .else ldmdb r2, {r0 - lr}^ @ get calling r0 - lr // --- 3 .endif .... add sp, sp, #\offset + PT_REGS_SIZE // --- 4 movs pc, lr @ return & move spsr_svc into cpsr // --- 5 1: bug "Returning to usermode but unexpected PSR bits set?", \@ .... #else .... #endif /* !CONFIG_THUMB2_KERNEL */ .endm1. 이전 컨택스트(usr mode) 가 저장된 sp 를 r2 에 저장된다. 인터럽트를 통해 restore_user_regs 가 호출되면, offset 은 0 이다. 그러므로, r1 은 이전 CPSR(usr mode) 를 갖게 되고, lr 은 이전 복귀 주소(usr mode pc) 를 갖게된다. 이 때, r2 의 주소가 S_PC 만큼증가한다(`!` 때문에)
2. 이전 CPSR(usr mode)를 spsr 에 저장한다. 즉, usr mode 로 바꿀 준비를 한다.
3. 인터럽트를 통해서 restore_user_regs 로 브랜치할 경우, `\fast` 는 `0` 이 된다. 그리고, 이 시점에 r2 는 sp 를 의미한다. 즉, 스택에서 r0_usr, r1_usr, ... , lr_usr 로 이전 컨택스트(usr mode)를 복구한다.
4. 상당히 중요한 코드다. 인터럽트 핸들러는 현재 커널 스레드의 스택을 공유한다. 그렇기 때문에, 인터럽트가 모두 처리되면, 스택을 복구해줘야 한다. 그런데, 위에서 볼 수 있다시피 복구라는 것이 단순히 sp 를 위로 이동시키면 그만이다. 즉, 사용했던 데이터를 0 으로 만들 필요가 없다는 것이다.
5. lr(이전 usr mode pc) 를 pc 에 넣음으로써, 인터럽트 발생 전 usr code 로 복귀한다. 거기다가, spsr_svc(usr mode) 를 cpsr 에 오버라이트 함으로써, usr mode 로 변경한다.2. return to svc
" svc mode 에서 발생한 인터럽트가 복귀하는 것은 굉장히 심플하다. `svc mode -> 인터럽트 발생 -> irq mode -> svc mode` 루틴은 결국 svc mode -> svc mode 이기 때문에, mode switching 이 필요없다.
// arch/arm/kernel/entry-header.S - v6.5 .macro svc_exit, rpsr, irq = 0 .if \irq != 0 @ IRQs already off .... .else @ IRQs off again before pulling preserved data off the stack disable_irq_notrace .... #ifndef CONFIG_THUMB2_KERNEL @ ARM mode SVC restore msr spsr_cxsf, \rpsr // --- 1 .... ldmia sp, {r0 - pc}^ @ load r0 - pc, cpsr // --- 2 #else .... #endif .endm1. `\rpsr` 은 파라미터로 전달되느 값이다(arm 에서 접두사 `\` 는 파라미터를 의미한다). __irq_svc 에서 irq 에는 1을 전달하지만, rpsr 에는 r5 를 전달한다. 그렇다면, r5 에는 어떤 값이 들어가 있을까? svc_entry 에서 r5 레지스터에 이전 컨택스트의 CPSR 값을 저장한다. 즉, svc mode 를 저장한다. 결국, `\rpsr` 은 svc mode 가 된다. spsr_cxsf 는 spsr 을 의미한다고 보면된다. spsr_cs, spsr_c, spsr_fx 등 여러 가지 방법으로 사용이 가능하다. 각 c, x, s, f 마다 차지하는 비트 필드는 8 바이트이며, 의미는 cpsr 과 같다고 볼 수 있다.
//arch/arm/kernel/entry-armv.S - v6.5 .macro svc_entry, stack_hole=0, trace=1, uaccess=1 .... ldmia r0, {r3 - r5} // --- 2 ....
2. r0 - pc 까지면, 총 16개의 레지스터가 복구된다. 앞전에 cpsr 을 복구했으니, 17 개 레지스터 모두를 복구한 셈이다. 그리고, `^` 은 user mode 레지스터를 의미한다. 즉, 커널 스택에 있는 값이 r0 - pc 에 로드될 때, r0_usr, r1_usr, ... , sp_usr, lr_usr, pc_usr 로 로드된다. 그리고, `^` 은 spsr 을 cpsr 로 카피하는 능력도 가지고 있다.'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Scheduler - process switching (1) 2023.11.21 [리눅스 커널] Synchronization - tranditional locking (0) 2023.11.17 [리눅스 커널] Scheduler - introduction (0) 2023.11.10 [리눅스 커널] Interrupt - IRQ domain (0) 2023.11.07 [리눅스 커널] Kernel command-line parameters (0) 2023.11.06