-
[공학] data structure - Stack공학 2023. 8. 7. 19:09
글의 참고
- https://users.ece.cmu.edu/~koopman/stack_computers/sec1_4.html
- https://medium.com/swift2go/stacks-and-lifo-structures-implementation-and-use-cases-7ada8f8c400
- https://www.geeksforgeeks.org/applications-advantages-and-disadvantages-of-stack/
- https://en.wikipedia.org/wiki/Stack_(abstract_data_type)
글을 쓴 목적
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다.
글의 내용
- 구조
- 스택은 `LIFO`의 구조를 가진다. 이 약자의 의미는 `Last-in, First-Out`의 구조이다. 여기서 중요한 것은 스택이라는 자료구조는 결국 LIFO라는 동작을 통해 만들어진다는 것이다. LIFO가 되기 위해서는 필수 2가지 동작이 반드시 필요하다.
- 필수
- Push - 데이터를 추가한다.
- Pop - 가장 최신에 추가한 데이터를 제거한다.
- 옵션
- Peek - 가장 최신의 데이터를 반환한다. 대신 제거하지는 않는다(Peek 동작은 쉽게 Pop을 하고 다시 Push를 하면 된다. 그래서 필수 동작은 아니다).
- 필수
- 아래의 그림을 통해 스택의 동작을 이해해보자.

출처 - https://en.wikipedia.org/wiki/Stack_(abstract_data_type) - 어떤 상자가 있다. 이 상자는 좁아서 박스를 위로 쌓을 수 밖에 없는 구조로 되어 있다. 이 상자에 1이라는 숫자가 적힌 박스가 들어있다. 여기에 2라는 박스를 그 위에 쌓는다.
- 다시 2라는 상자위에 3이라는 박스를 쌓는다. 그 과정을 반복해서 6이라는 박스까지 쌓는다.
- 이 상자에서 제일 위에 6이라는 박스를 꺼낸다. 차례대로 꺼내서 마지막에 제일 처음 넣었던 2라는 박스를 꺼낸다.
- 위에서 보다시피 결국 자료구조라는 것은 특정 동작에 따라 정의되는 부분이다. 즉, 위에서 박스나 상자같은 것들이 중요한 게 아니라, 저걸 넣고 빼는 동작 방식 때문에 저 자료구조가 정의된 다는 것에 유념하자.
- 스택 오버플로우, 언더플로우
- 스택 오버플로우는 Push 동작 수행 전 스택을 검사할 때, 스택 언더플로우는 Pop 동작 수행 전 스택을 검사할 때 진행한다.
- 스택 오버플로우 - 스택이 꽉찼다.
- 스택 언더플로우 - 스택이 비어있다.
- 구현
- 스택은 배열이나 연결 리스트로 구현이 가능하다. 구현에 들어가기 앞서 위키에서 가져온 내용을 보자.
- What identifies the data structure as a stack, in either case, is not the implementation but the interface: the user is only allowed to pop or push items onto the array or linked list, with few other helper operations. => 둘중(연결리스트나 배열)에 뭐로 구현했냐는 중요하지 않다. 결국 사용자에게는 인터페이스만 제공되기 때문에 구현부에 대한 내용은 은닉된다.
- 먼저 구현부를 보기전에 구조를 파악해보면 좋다. 되게 자료구조는 다음과 같은 형식으로 구성된다.
- 데이터가 저장될 버퍼
- 알고리즘 연산에 필요한 데이터
- 스택을 예시로 들면 다음과 같다. 아래의 그림을 보면 결국 배열로 구현하든, 연결리스트로 구현하든 데이터 구조는 비슷하다.

- 배열로 스택 만들기
structure stack: maxsize : integer top : integer items : array of item procedure initialize(stk : stack, size : integer): stk.items ← new array of size items, initially empty stk.maxsize ← size stk.top ← 0 // 푸쉬 동작과 탑 인덱스를 +1 시키기전에, 반드시 오버플로우를 체크하자. procedure push(stk : stack, x : item): if stk.top = stk.maxsize: report overflow error else: stk.items[stk.top] ← x stk.top ← stk.top + 1 // 팝 동작과 탑 인덱스를 -1 시키기전에, 반드시 언더플로우를 체크하자. procedure pop(stk : stack): if stk.top = 0: report underflow error else: stk.top ← stk.top − 1 r ← stk.items[stk.top] return r- 연결 리스트로 스택 만들기
- 연결리스트 자료구조를 만들 때 주의점이 있다. 배열로 만들 때와 다르게 스택 자료구조와 데이터 자료구조를 별도로 만든다.
structure frame: data : item next : frame or nil structure stack: head : frame or nil size : integer procedure initialize(stk : stack): stk.head ← nil stk.size ← 0 // 연결리스트에서는 헤드가 중요하다. 헤드는 가장 최신에 푸쉬된 아이템을 가리킨다. 일반적으로 연결리스트에서는 오버플로우가 없다고 가정한다. procedure push(stk : stack, x : item): newhead ← new frame newhead.data ← x newhead.next ← stk.head stk.head ← newhead stk.size ← stk.size + 1 procedure pop(stk : stack): if stk.head = nil: report underflow error r ← stk.head.data stk.head ← stk.head.next stk.size ← stk.size - 1 return r- 싱글 연결리스트로 구현할 때, 가장 중요한 점은 `새로 들어오는 노드의 next는 기존에 가장 꼭대기(head)에 있는 놈을 바라봐야 한다` 이다. 조금 이해하기 어려울 수 있으니 아래 그림을 통해 한 번 의미를 곱씹어 보기를 바란다.

- (1) 동작 - newhead.next <- stk.head
- (2) 동작 - stk.head <- newhead
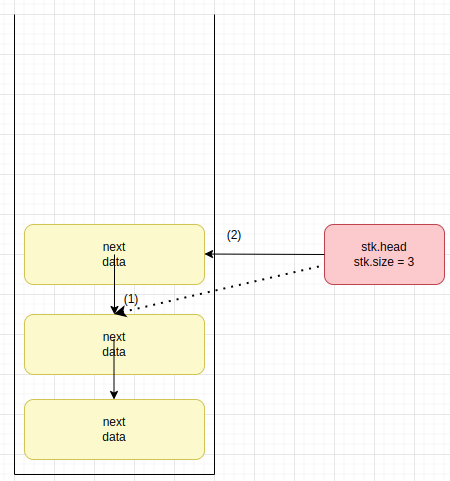
- 핵심은 새로 생기는 노드의 next가 기존 head node를 바라봐야 한다는 것이다.
- 사용처
- 사실 구현 다음으로 중요한 부분이 사용처이다. Stack은 컴퓨터 분야에서 너무 많이 쓰여서 문제다.
- undo/redo 명령어. 즉, 실행 취소 명령어
- 순서 바꾸기. 즉, (1, 2, 3) -> (3, 2, 1)
- 백트래킹.
- 함수 복귀, 지역 변수 할당, 함수로 전달된 파라미터 할당
- Expression evaluation
- Browser history
- Balanced Parentheses/brackets
- syntax parsing
- Towers of Hanoi
'공학' 카테고리의 다른 글
[공학] 오픈 소스 - 소프트웨어(OSS) 라이센스 (0) 2023.08.07 - 스택은 `LIFO`의 구조를 가진다. 이 약자의 의미는 `Last-in, First-Out`의 구조이다. 여기서 중요한 것은 스택이라는 자료구조는 결국 LIFO라는 동작을 통해 만들어진다는 것이다. LIFO가 되기 위해서는 필수 2가지 동작이 반드시 필요하다.