-
[xv6] mkfs프로젝트/운영체제 만들기 2023. 7. 30. 02:24
글의 참고
- https://github.com/mit-pdos/xv6-public/tree/master
- xv6 - DRAFT as of September 4, 2018
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
: `xv6`를 실행시키기 위해서는 `xv6.img` 부팅 디스크 파일과 `fs.img` 파일 시스템 파일이 필요하다. 왜 2개를 별도로 나눠났을까? 무조건적으로 부팅 디스크 파일과 파일 시스템 파일을 나눌 필요는 없다. 하나의 이미지로 합쳐도 상관없다.
: 근데, 정말로 `xv6` 에서 파일을 나눠놓은 이유가 뭘까? 내 개인적으로 생각으로 추측해보면, 부팅하는데 포맷이 있는 디스크들은 읽는데 불편함을 가져다 준다. 파일 포맷 해석에 대한 메타 데이터들이 필요하기 때문에, 코드양이 늘어날 수 있다. `xv6`의 부트 로더는 GRUB과 같이 `스테이지 2` 부트 로더 따위는 존재하지 않는다. 오로지 `MBR 부트 섹터` 양에 맞춘 512B 부트 로더 밖에 존재하지 않는다. 즉, 512B 양에 딱 맞춘 부트 로더를 사용하기 때문에 읽기가 쉬운 RAW 이미지 파일을 필요로 할 듯 싶다. 그런데, 32비트 `xv6` 커널 이미지(`kernel`)는 ELF 포맷인데...??? 결국, 부트 로더에서 ELF 포맷을 파싱해서 1MB에 로딩을 시키는데...
: `xv6.img` 파일과 `fs.img`를 만드는 과정은 `Makefile`에 나와있다.
// Makefile UPROGS=\ _cat\ _echo\ _forktest\ _grep\ _init\ _kill\ _ln\ _ls\ _mkdir\ _rm\ _sh\ _stressfs\ _usertests\ _wc\ _zombie\ ... xv6.img: bootblock kernel dd if=/dev/zero of=xv6.img count=10000 dd if=bootblock of=xv6.img conv=notrunc dd if=kernel of=xv6.img seek=1 conv=notrunc ... bootblock: bootasm.S bootmain.c $(CC) $(CFLAGS) -fno-pic -O -nostdinc -I. -c bootmain.c $(CC) $(CFLAGS) -fno-pic -nostdinc -I. -c bootasm.S $(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 -o bootblock.o bootasm.o bootmain.o $(OBJDUMP) -S bootblock.o > bootblock.asm $(OBJCOPY) -S -O binary -j .text bootblock.o bootblock ./sign.pl bootblock ... mkfs: mkfs.c fs.h gcc -Werror -Wall -o mkfs mkfs.c ... fs.img: mkfs README $(UPROGS) ./mkfs fs.img README $(UPROGS): `xv6.img` 이미지 파일과 `bootblock` 파일을 만드는 과정은 이 글을 참고하자. 여기서는 `fs.img`를 만드느 과정을 알아본다.
: `fs.img` 이미지가 만드는 과정을 잘 보면, `mkfs.c` 파일은 리눅스에서 빌드된다. 즉, 크로스 컴파일(`i386-jos-elf`)이 아닌 리눅스 환경에 있는 빌트-인 GCC를 이용해서 빌드된다. 이 말은 `mkfs`는 `xv6.img`에는 포함되지 않는다는 말이다. 왜냐면, `mkfs`은 리눅스 환경으로 빌드되었기 때문이다. `gcc -Werror -Wall -o mkfs mkfs.c` 에서 `gcc`는 현재 내 컴퓨터에서 동작하는 CPU를 기준으로 동작하는 컴파일러다. 즉, 인텔 x86_64 컴파일러다. 그런데, `xv6`는 i386 컴파일러를 사용하므로, `x86-64`로 빌드된 실행 파일이 `i386`에서 동작하지 않게 된다. 그리고, 컴파일러는 벤더사뿐만 아니라, 운영체제에도 의존적이다. 즉, 운영체제마다 사용하는 ABI가 다르기 때문에, 만약에, 리눅스 운영체제가 제공하는 컴파일러 사용하면 `mkfs` 실행 파일은 리눅스 운영체제 관련 정보들로 가득차게 된다. `xv6`가 리눅스가 사용하는 정보들을 해석하고 파싱해서 사용할 수 있다면 모르겠지만, 현재를 기준으로 `xv6`에는 그런 기능이 없다.
: 그래서 결국 위에서 `./mkfs` 를 실행하면, 리눅스 환경에서 실행되는 것이므로, 우리가 흔히하는 `main` 함수가 호출되면서 매개변수의 개수와 매개변수 내용들이 각각 `argc`와 `argv`에 전달될 것 이다. 만약, 저기서 `mkfs.c` 파일을 `i386-jos-elf`로 빌드했다면, 별도로 `fs.img`를 만들 방법을 강구해야 한다. 참고로, `fs.img`는 `xv6` 컴파일 시점에 함께 만들어져야 하므로, 리눅스에서 제공해주는 다른 툴들을 이용해서 만들어야 할 것이다.
: `mkfs`의 `main` 함수를 호출하면, 인자 개수에 대한 검사를 진행하고, 2번째 인자(`fs.img`)를 `open` 한다. 플래그를 보면, 무조건 해당 파일을 새로 만드는 옵션이다. 그리고 권한은 `읽기/쓰기` 모두 가능하도록 한다. 즉, `fsfd` 파일에 `fs.img` 파일에 읽기/쓰기에 대한 파일 포인터가 들어가 있다. 그리고, 파일 시스템에 대한 메타 정보를 저장하는 `슈퍼 블락`에 대해 설정한다.
// mkfs.c ... #define NINODES 200 // Disk layout: // [ boot block | sb block | log | inode blocks | free bit map | data blocks ] int nbitmap = FSSIZE/(BSIZE*8) + 1; int ninodeblocks = NINODES / IPB + 1; int nlog = LOGSIZE; int nmeta; // Number of meta blocks (boot, sb, nlog, inode, bitmap) int nblocks; // Number of data blocks int fsfd; struct superblock sb; char zeroes[BSIZE]; uint freeinode = 1; uint freeblock; ... int main(int argc, char *argv[]) { int i, cc, fd; uint rootino, inum, off; struct dirent de; char buf[BSIZE]; struct dinode din; static_assert(sizeof(int) == 4, "Integers must be 4 bytes!"); if(argc < 2){ fprintf(stderr, "Usage: mkfs fs.img files...\n"); exit(1); } assert((BSIZE % sizeof(struct dinode)) == 0); assert((BSIZE % sizeof(struct dirent)) == 0); fsfd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC, 0666); if(fsfd < 0){ perror(argv[1]); exit(1); } // 1 fs block = 1 disk sector nmeta = 2 + nlog + ninodeblocks + nbitmap; nblocks = FSSIZE - nmeta; sb.size = xint(FSSIZE); sb.nblocks = xint(nblocks); sb.ninodes = xint(NINODES); sb.nlog = xint(nlog); sb.logstart = xint(2); sb.inodestart = xint(2+nlog); sb.bmapstart = xint(2+nlog+ninodeblocks); printf("nmeta %d (boot, super, log blocks %u inode blocks %u, bitmap blocks %u) blocks %d total %d\n", nmeta, nlog, ninodeblocks, nbitmap, nblocks, FSSIZE); freeblock = nmeta; // the first free block that we can allocate for(i = 0; i < FSSIZE; i++) wsect(i, zeroes); memset(buf, 0, sizeof(buf)); memmove(buf, &sb, sizeof(sb)); wsect(1, buf); rootino = ialloc(T_DIR); assert(rootino == ROOTINO); bzero(&de, sizeof(de)); de.inum = xshort(rootino); strcpy(de.name, "."); iappend(rootino, &de, sizeof(de)); bzero(&de, sizeof(de)); de.inum = xshort(rootino); strcpy(de.name, ".."); iappend(rootino, &de, sizeof(de)); for(i = 2; i < argc; i++){ assert(index(argv[i], '/') == 0); if((fd = open(argv[i], 0)) < 0){ perror(argv[i]); exit(1); } // Skip leading _ in name when writing to file system. // The binaries are named _rm, _cat, etc. to keep the // build operating system from trying to execute them // in place of system binaries like rm and cat. if(argv[i][0] == '_') ++argv[i]; inum = ialloc(T_FILE); bzero(&de, sizeof(de)); de.inum = xshort(inum); strncpy(de.name, argv[i], DIRSIZ); iappend(rootino, &de, sizeof(de)); while((cc = read(fd, buf, sizeof(buf))) > 0) iappend(inum, buf, cc); close(fd); } // fix size of root inode dir rinode(rootino, &din); off = xint(din.size); off = ((off/BSIZE) + 1) * BSIZE; din.size = xint(off); winode(rootino, &din); balloc(freeblock); exit(0); }: `freeblock = nmeta` 에서 `nmeta`는 메타 데이터에 할당된 블락들의 개수다(`nmeta = 2 + nlog + ninodeblocks + nbitmap`). `freeblock` 은 FREE한 `데이터 최초의 데이터 블락 번호`를 의미한다. `xv6` 에서는 먼저 메타 데이터에 대한 블락들을 순차적으로 할당하고, 남은 모든 데이터 블락들을 데이터 블락에 할당한다(`nblocks = FSSIZE - nmeta`). 그러다 보니, `nmeta`는 최초의 사용 가능한 데이터 블락 번호가 된다. 그래서 이 값을 `freeblock`에 할당하니, `freeblock` 또한 최초의 사용 가능한 데이터 블락 번호가 된다.
: `mkfs`는 포맷 함수이기 때문에, 먼저 `fs.img`를 모두 0으로 초기화한다(`for(i = 0; i < FSSIZE; i++) wsect(i, zeroes)`)
: 그리고, `xv6`의 파일 시스템 메타 데이터 정보들이 들어있는 슈퍼 블락을 `fs.img` 첫 번째 섹터에 쓴다. 0 번째 섹터는 부트 섹터라서 쓸 수 없다.
: 근데, `fs.img`에도 부트 섹터를 쓰나? `xv6.img`에만 쓰는 거 아니었나?
: 그리고, 루트 파일 시스템 구조를 만들기 위해 `루트 inode`를 하나 만든다. 이 때, inode 할당은 `fs.c` 파일에서 사용하는 `ialloc` 함수가 아닌, `mkfs.c` 파일에 커스텀하게 작성한 `ialloc` 함수를 통해서 inode를 할당한다. 애초에 `fs.c` 파일에 있는 `ialloc` 함수는 `xv6` 환경에서만 동작하는 함수이다. 그리고 커널 레벨 함수이기도 해서 `mkfs`에서는 사용하면 안되고, 사용되어서도 안된다.
: `mkfs`는 `fs.img` 이미지 파일만 `xv6` 파일 시스템 구조에 맞게 포맷만 해주면 되므로, 모든 함수를 간단하게 만들었다. inode를 할당할 때, 각 inode를 구분하기 위해 ID를 할당한다. ID의 할당은 `freeinode`를 통해서 이루어진다. `freeinode`는 전역 변수로 선언되서 `ialloc` 함수가 호출될 때 마다, 새로 만들어지는 inode에게 ID를 부여한다. 이 값은 순차적으로 1씩 증가한다. 그리고, `ialloc` 함수를 통해 만들어지는 inode는 SW에서 사용하는 inode 이기 보다는 디스크 저장될 inode이므로, `struct dinode`를 사용해서 만든다.
: `bzero`는 마치 `memset(&dst, 0, sizeof(dst))` 과 동일한 기능을 한다. 근데 여기서 재미있는 부분은 `bzero` 함수는 `xv6`의 `fs.c` 파일에 선언되어 있는 함수라는 것이다. 엥? 위에서 사용못한다고 하지 않았나?
// fs.c // Zero a block. static void bzero(int dev, int bno) { struct buf *bp; bp = bread(dev, bno); memset(bp->data, 0, BSIZE); log_write(bp); brelse(bp); }: 맞다. 원래라면 사용하면 안된다. 다시 한번 상기하자. `mkfs` 파일은 크로스 컴파일러가 아닌, 빌트-인 컴파일러로 빌드되는 파일이다. 그리고 `mkfs.c` 파일은 `xv6`의 다른 C 파일들과 함께 빌드되지 않는다. 그런데, 딱 하나의 C 파일이 파일과 함께 빌드된다. 그게 바로 `fs.c` 파일이다. 그래서 `fs.c` 파일에서 정의된 파일들을 `mkfs.c` 파일에서도 사용할 수 있는 것이다. 그렇다면 `fs.c` 파일은 `i386-jos-elf` 크로스 컴파일러와 현재 내 컴퓨터에서 설치된 빌트-인 컴파일러 모두에서 빌드될 수 있는 파일이된다.
// mkfs.c #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <string.h> #include <fcntl.h> #include <assert.h> #define stat xv6_stat // avoid clash with host struct stat #include "types.h" #include "fs.h" #include "stat.h" #include "param.h" ... uint freeinode = 1; ... uint ialloc(ushort type) { uint inum = freeinode++; struct dinode din; bzero(&din, sizeof(din)); din.type = xshort(type); din.nlink = xshort(1); din.size = xint(0); winode(inum, &din); return inum; }: `winode` 함수는 첫 번째 인자로 전달된 inode 번호를 갖는 inode를 디스크에서 읽어서 두 번째 인자로 전달된 inode로 교체한다. 예를 들어, `winode(3, ip)` 로 호출할 경우, inode 섹터에서 3번 inode를 추출해서 ip로 교체한다. `IBLOCK` 매크로 함수는 inode의 번호를 전달하면, 해당 inode 번호에 대응하는 inode가 있는 섹터 번호를 반환한다.
: `dip = ((struct dinode*)buf) + (inum % IPB)` 의 의미는 inode 섹터에서 inum에 대응하는 inode를 추출하는 것이다. `buf`는 inum에 대응하는 inode가 들어있다. 그래서 `inum % IPB`을 `buf`에 더해서 `buf`의 주소를 inum에 대응하는 inode로 이동시킨다. 이렇게 inum에 대응하는 inode를 추출하게 된다. 예를 들어, inum이 3이다. `IPB`는 한 섹터에 들어갈 수 있는 최대 inode의 개수를 의미한다. 디스크에 저장되는 inode는 `struct dinode` 구조체 크기와 동일하다. 즉, 16바이트다. 그래서 `IPB`는 512 / 16 으로 32가 된다. 그렇면, `dip = ((struct dinode*)buf) + (inum % IPB)` 은 `dip = ((struct dinode*)buf) + (3 % 32)`으로 바뀐다.
void winode(uint inum, struct dinode *ip) { char buf[BSIZE]; uint bn; struct dinode *dip; bn = IBLOCK(inum, sb); rsect(bn, buf); dip = ((struct dinode*)buf) + (inum % IPB); *dip = *ip; wsect(bn, buf); }: `루트 inode`를 하나 만든 후, 곧 바로 다시 `루트 inode`에 `.`과 `..` 디렉토리 엔트리를 추가하고 있다. 이 과정을 거치면, `루트 inode`의 0 번째 직접 데이터 블락에 `.`과 `..`의 디렉토리 엔트리가 연속적으로 저장된다. 참고로, `.`과 `..`에 `ialloc` 함수를 사용하지 않았다. 즉, inode 번호를 할당하지 않았다.
// mkfs.c ... bzero(&de, sizeof(de)); de.inum = xshort(rootino); strcpy(de.name, "."); iappend(rootino, &de, sizeof(de)); bzero(&de, sizeof(de)); de.inum = xshort(rootino); strcpy(de.name, ".."); iappend(rootino, &de, sizeof(de)); ...: 그런데, 위에서 `.`과 `..`은 무슨 의미이며, 왜 `루트 inode`에 이것들을 저장할까? 이 내용은 `xv6`에서 간단하게만 나와있다.
...
If the new inode is a directory, create initializes it with `.` and `..` entries.
...
- 참고 : xv6 - DRAFT as of September 4, 2018 [ Code: System calls ]: 즉, 새로운 inode가 만들어 질 때, 해당 노드가 디렉토리라면 `.`과 `..` 디렉토리 엔트리를 추가한다는 소리다. 이 내용은 조금 부족한 면이 많다. 그래서 `Design of the Unix Operating System`에서 내용을 참고했다.
directories are the files that give the file system its hierarchical structure; they play an important role in conversion of a file name to an inode number. A directory is a file whose data is a sequence of entries, each consisting of an inode number and the name of a file contained in the directory. A path name is a null terminated character string divided into separate components by the slash ("/") character. Each component except the last must be the name of a directory, but the last component may be a non-directory file. UNIX System V restricts component names to a maximum of 14 characters; with a 2 byte entry for the inode number, the size of a directory entry is 16 bytes.
" 아래 표는 `UNIX System V`에서의 `/etc` 폴더안에 있는 파일들을 보여준다. 컬럼들의 내용은 아래에 `/`을 기준으로 해석하면 된다.
디렉토리 내에서 바이트 오프셋 / inode 번호 / 파일 이름 0 83 .
16 2 ..
32 1798 init
48 1276 fsck
64 85 clri
80 1268 motd
96 1799 mount
112 88 mknod
128 2114 passwd
144 1717 umount
160 1851 checklist
176 92 fsdblb
192 84 config
208 1432 getty
224 0 crash
240 95 mkfs
256 188 inittab
Every directory contains the file names dot and dot-dot ("." and "..") whose inode numbers are those of the directory and its parent directory, respectively. The inode number of "." in `/etc` is located at offset 0 in the file, and its value is 83. The inode number of ".." is located at offset 16, and its value is 2. Directory entries may be empty, indicated by an inode number of 0. For instance, the entry at address 224 in "/etc" is empty, although it once contained an entry for a file named "crash". The program `mkfs` initializes a file system so that "." and ".." of the root directory have the root inode number of the file system.
...
- 참고 : Design of the Unix Operating System [ 4.3 DIRECTORIES ]: `xv6`의 `struct dirent` 구조체는 `UNIX System V`의 디렉토리 엔트리 구조를 그대로 가져온 듯 하다. 왜냐면, 14바이트 이름과 2바이트 inode 번호는 완전히 동일하다. 그리고 모든 디렉토리는 반드시 파일 이름이 `.`과 `..`인 디렉토리를 포함해야 한다고 한다. 그리고 `.` 디렉토리 엔트리의 inode 번호는 반드시 해당 디렉토리의 오프셋 0에 위치해야 한다. `..` 디렉토리 엔트리의 inode 번호는 반드시 해당 디렉토리의 오프셋 16에 위치해야 한다. 즉, `.`과 `..`은 각각 맨 앞과 그 다음에 위치해야 한다는 말이다.
: 그리고, `inode 번호 0`은 예약 번호다. 즉, 어딘가에 할당되는 번호가 아니다. inode 번호가 0인 inode는 `빈 디렉토리 엔트리`를 의미한다. 그런데, 빈 디렉토리라고 하더라도 파일 이름은 존재한다. 위에서 `crash`가 이 경우에 해당한다. 그리고 원래라면 `inode 번호 1`도 bad block으로 예약되어 있다. 그런데, `xv6`는 루트 inode에 inode 번호 1을 할당하고 있다.
: `루트 inode`에 `.`과 `..`을 추가하면, 유저 프로그램을 `fs.img`에 써야 한다. 그 과정이 `for(i = 2; i < argc; i++)` 루프문안에 들어가 있다. `fd = open(argv[i], 0)`에서 `0`은 `O_RDONLY(0)`를 의미한다. 그리고, 여기서 `open` 함수는 `xv6`에서 정의한 `open` 함수가 아니다. `mkfs.c` 파일이 현재 실행되고 있는 환경이 리눅스인 점을 상기하자. 즉, 리눅스에서 제공하는 `stdio.h` 파일에서 제공하는 `open` 함수를 쓰고 있는 것이다.
// mkfs.c ... for(i = 2; i < argc; i++){ assert(index(argv[i], '/') == 0); if((fd = open(argv[i], 0)) < 0){ perror(argv[i]); exit(1); } // Skip leading _ in name when writing to file system. // The binaries are named _rm, _cat, etc. to keep the // build operating system from trying to execute them // in place of system binaries like rm and cat. if(argv[i][0] == '_') ++argv[i]; inum = ialloc(T_FILE); bzero(&de, sizeof(de)); de.inum = xshort(inum); strncpy(de.name, argv[i], DIRSIZ); iappend(rootino, &de, sizeof(de)); while((cc = read(fd, buf, sizeof(buf))) > 0) iappend(inum, buf, cc); close(fd); } ...: `fs.img` 파일에 ㄷㄹㄷㄹㄷㄹㄷㄹㄷㄹ
: `iappend` 함수는 `mkfs` 파일에서 제일 핵심 함수다. 이 함수는 먼저 `inum`을 통해서 해당 inum에 맞는 inode를 추출해낸다. 그리고, 주소 `xp` 에서 `n`만큼 데이터를 inode의 데이터 블락에 쓴다. 먼저, `rinode` 함수를 통해서 inum에 대응하는 inode를 `din`에 로드한다. 그리고, 꺼내온 inode가 가지고 있는 데이터 사이즈를 `off`에 저장한다.
: `fbn = off / BSIZE` 에서 `fbn`은 inode가 이전 작업을 마무리하고, 공간이 남은 마지막 데이터 섹터 번호를 반환하는 코드다. 예를 들어, inode의 데이터 사이즈가 2248 이면, 섹터가 512B를 기준으로 한다면, 4번째 블락에서 312B(2560B - 2248B) 정도가 남는다. 즉,4번째 블락부터 데이터를 쓸 수 있는 것이다(섹터 번호가 0 부터 시작).
: `fbn < NDIRECT` 의미는 현재 inode의 직접 데이터를 쓸 수 있는 블락들이 꽉 찼는지를 검사한다. 현재 inode의 사이즈가 23482B 라면, 섹터 번호로는 45번이 된다. 직접 데이터를 쓸 수 있는 블락은 총 12개까지 이니, 45라면 이건 직접 데이터를 쓸 수 있는 번호가 아니다. 그러므로, 간접 데이터 블락으로 넘어가야 한다.
: 간접 데이터 블락은 먼저 13번째 블락이 데이터 섹터가 아니라는 것을 알아야 한다. 직접 데이터 블락들은 디스크 섹터 번호를 직접 저장한다. 그래서 그 번호를 통해서 디스크에서 데이터를 읽어와서 수정하고 다시 쓰는 과정을 거친다. 간접 데이터 블록은 이 과정에 한 가지 과정이 더 추가된다.
직접 데이터 블록" 각 블록(총 12개)들에는 섹터 번호가 저장되어 있음 -> 해당 섹터 번호를 통해서 디스크 내용을 읽어옴 -> 진짜 데이터(512B)
간접 데이터 블록" 간접 블록(1개)에도 섹터 번호가 들어있음 -> 해당 섹터 번호를 통해서 디스크 내용을 읽어옴 -> 읽어온 데이터(512B)는 다시 128개의 섹터 번호로 구성됨. -> 다시 각 섹터 번호를 읽어서 이번에는 진짜 데이터(512B)를 가져옴.: 즉, `xv6` inode의 데이터 구조는 13개의 데이터 블럭이 존재하는데, 12개는 직접 블록이고, 1개는 간접 블럭이다. 그런데, 간접 블록에는 다시 128개의 직접 블록이 포함된다. 그러므로, 실제 데이터 블록은 `12 + 128`개의 블록이 된다.
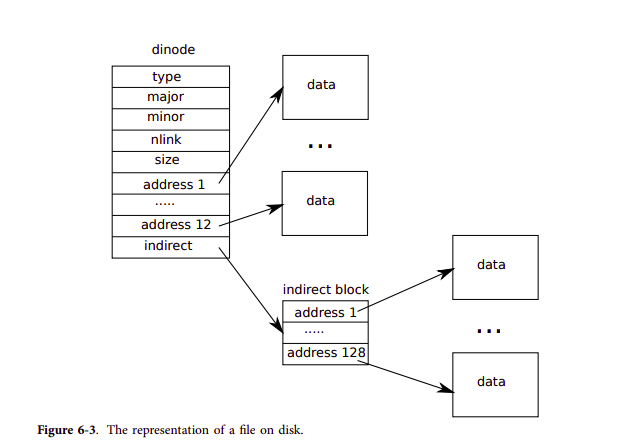
: 간접 블락에 데이터 섹터를 할당하는 과정은 검사 조건이 좀 더 많다. 먼저, 간접 블록, 즉, 13번째 블록에 섹터가 할당이 되어있는지 검사해야 한다. 이 블록을 먼저 할당을 받아야 128개의 직접 블록들을 더 할당받을 수 있다. 해당 내용에 대한 코드는 아래와 같다.
... if(xint(din.addrs[NDIRECT]) == 0){ din.addrs[NDIRECT] = xint(freeblock++); }: 13번째 블락이 할당되어 있다면, 이제 128개의 직접 블록들이 할당되어 있는지 검사해야 한다. 즉, 13번째 블락에 512B를 할당받았으니, 여기에 다시 128개의 512B 섹터를 할당받는 것이다. 128개인 이유는 디스크에서는 섹터 번호이지만, 이게 나중에 인-메모리에서 관리될 때는 주소 단위(4B)로 관리되야 하므로, 512를 4로 128개가 된 것이다. 해당 내용에 대한 코드는 아래와 같다.
... rsect(xint(din.addrs[NDIRECT]), (char*)indirect); if(indirect[fbn - NDIRECT] == 0){ indirect[fbn - NDIRECT] = xint(freeblock++); wsect(xint(din.addrs[NDIRECT]), (char*)indirect); } x = xint(indirect[fbn-NDIRECT]);: 그리고 루프 마지막에 앞에서 열심히 찾은 inode의 데이터 블락에 전달받은 데이터(`p = xp`)를 쓰게 된다. 그런데, 이 때 그냥 `n`만큼 데이터를 쓰게 아니라, 계산이 필요하다. 왜냐면, inode가 반환한 버퍼에 작업중이던 내용에 그냥 오버라이트하면 안된다. 위에서 말했던 것처럼 2248 까지 작업을 했다고 치자. 2248B 까지 작업을 했다는 것은 4번째 섹터의 시작인 2048B를 기준으로 200B 데이터가 써졌다는 것이다. 이 데이터는 보존되어야 한다. 그러므로, 새로운 쓰기 작업이 이어나가려면, 2248B 부터 데이터를 써야 한다. 그래서 어디서부터 데이터를 써야 할지 계산이 필요하다.
n1 = min(n, (fbn + 1) * BSIZE - off);
: 위에 식을 예시를 통해 이해해보자. inode의 데이터 블락 사이즈가 2248B 이고, `n = 0x4000`이라고 가정하자. 그러면, `off = 2248`이고, `fbn = 4`가 된다. 위에서 `n1`은 데이터를 얼마나 써야 하는지를 나타내는 변수다. 4번째 섹터에 써야하고 현재 까지 쓴 양이 2248B이고, 섹터 단위가 512B인 것을 고려하면, `5*512B - 2248B = 312B`가 된다. 즉, `다음 번 섹터 번호 * 512 - 현재 사이즈` 라고 볼 수 있다. 대개, 남는 양을 구할 때 이런 비슷한 식을 많이 보게된다.
: 그리고 `rsect`을 통해서 작업중이던 4번 섹터를 읽어왔다고 치자. 그렇면 `2048B ~ 2560B`를 읽어온 것이다. 이제 2248B 뒷쪽부터 데이터를 써야 한다. 그 식은 아래와 같다. `p`가 가지고 있는 데이터를 `buf + off - (fbn * BSIZE)`에 `n1` 만큼 쓰는 것이다.
bcopy(p, buf + off - (fbn * BSIZE), n1);: `buf + off - (fbn * BSIZE)`에서 buf를 제외하면 `off - (fbn * BSIZE)` 가 된다. 이 값은 `2248 - (4 * 512) = 200`가 된다. 즉, `buf + off - (fbn * BSIZE)`은 2248이 된다. `p`가 가지고 있는 데이터를 2248에 `n1`만큼 쓰게 된다.
: 요청했던 inode에 모든 데이터를 쓰고 나면, 루프를 빠져나오고, 작업을 진행했던 inode를 다시 디스크에 쓴다.
void iappend(uint inum, void *xp, int n) { char *p = (char*)xp; uint fbn, off, n1; struct dinode din; char buf[BSIZE]; uint indirect[NINDIRECT]; uint x; rinode(inum, &din); off = xint(din.size); // printf("append inum %d at off %d sz %d\n", inum, off, n); while(n > 0){ fbn = off / BSIZE; assert(fbn < MAXFILE); if(fbn < NDIRECT){ // NDIRECT = 12 if(xint(din.addrs[fbn]) == 0){ din.addrs[fbn] = xint(freeblock++); } x = xint(din.addrs[fbn]); } else { if(xint(din.addrs[NDIRECT]) == 0){ // NDIRECT = 128 din.addrs[NDIRECT] = xint(freeblock++); } rsect(xint(din.addrs[NDIRECT]), (char*)indirect); if(indirect[fbn - NDIRECT] == 0){ indirect[fbn - NDIRECT] = xint(freeblock++); wsect(xint(din.addrs[NDIRECT]), (char*)indirect); } x = xint(indirect[fbn-NDIRECT]); } n1 = min(n, (fbn + 1) * BSIZE - off); rsect(x, buf); bcopy(p, buf + off - (fbn * BSIZE), n1); wsect(x, buf); n -= n1; off += n1; p += n1; } din.size = xint(off); winode(inum, &din); }'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
[빌드] Makefile (0) 2023.08.03 [xv6] entry (0) 2023.08.01 [xv6] Boot-loader (0) 2023.07.29 [xv6] - fork (0) 2023.07.27 [xv6] - sbrk (0) 2023.07.26