-
[컴퓨터 구조] Cache공학/컴퓨터구조 2023. 8. 12. 03:12
글의 참고
- 64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf
- https://en.wikipedia.org/wiki/CPU_cache#Multi-level_caches
- https://en.wikipedia.org/wiki/Locality_of_reference
- https://en.wikipedia.org/wiki/CPU_cache
- https://en.wikipedia.org/wiki/Translation_lookaside_buffer
- https://en.wikipedia.org/wiki/Cache_placement_policies
- https://en.wikipedia.org/wiki/Cache_coherence
- http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
- https://lwn.net/Articles/252125/
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Cache entry, Cache line(Cache Block)
: 캐쉬 라인은 캐쉬의 기본 데이터 전송 단위를 의미한다. 즉, 캐쉬 단위 사이즈를 의미한다. 캐쉬 엔트리를 실제 캐쉬로 복사된 메모리 데이터를 의미한다. 기본적으로 CPU 캐쉬의 데이터 전송단위는 비트나 바이트가 아니고, `캐쉬 라인`이다. 캐쉬 라인은 일반적으로 32B, 64B, 128B 사이즈를 갖는다. 캐쉬 라인이 32B 라면, 메모리는 32B 크기 블락으로 나뉜다는 것이다. 예를 들어, 내가 1B만 요청하더라도, 읽기든 쓰기든 상관없이, 주변 31바이트를 같이 가져온다는 것이다.
Data is transferred between memory and cache in blocks of fixed size, called `cache lines` or `cache blocks`. When a cache line is copied from memory into the cache, a cache entry is created. The `cache entry` will include the copied data as well as the requested memory location (called a `tag`).
- 참고 : https://en.wikipedia.org/wiki/CPU_cache#Cache_entries- 캐쉬 종류
: 기본적으로 PC CPU에는 최소 3개의 독립적인 캐쉬들이 존재한다.
Instruction Cache" 파이프라인에서 `명령어 패치` 과정을 빨리 하기 위해 사용된다.
Data Cache" 파이프라인에서 `데이터 채피`와 `데이터 저장`을 빨리 하기 위해 사용된다.
Translation Lookaside buffer(TLB)" 가상 주소를 물리 주소로 빠르게 변환시키기 위해 사용되는 캐시다. TBL는 단위가 페이지 사이즈이기 때문에, 데이터와 명령어가 모두 섞여있을 수 있다. TLB는 CPU 캐쉬가 아닌, MMU 내부에 들어있는 캐쉬다. 이 말이 `TLB는 SW적으로 컨트롤할 수 없다는 뜻`은 아니다. x86에서 TLB 관련 여러 가지 명령어를 제공하니 참고하도록 하자.
Similar to caches, TLBs may have multiple levels. CPUs can be (and nowadays usually are) built with multiple TLBs, for example a small L1 TLB (potentially fully associative) that is extremely fast, and a larger L2 TLB that is somewhat slower. When instruction-TLB (ITLB) and data-TLB (DTLB) are used, a CPU can have three (ITLB1, DTLB1, TLB2) or four TLBs.
For instance, Intel's Nehalem microarchitecture has a four-way set associative L1 DTLB with 64 entries for 4 KiB pages and 32 entries for 2/4 MiB pages, an L1 ITLB with 128 entries for 4 KiB pages using four-way associativity and 14 fully associative entries for 2/4 MiB pages (both parts of the ITLB divided statically between two threads)and a unified 512-entry L2 TLB for 4 KiB pages, both 4-way associative.
- 참고 : https://en.wikipedia.org/wiki/Translation_lookaside_buffer- Invalid TLB [ 참고1 ]
: 일반적으로, 컨택스트 스위칭시에는 각 프로세스가 가지고 있는 페이지 테이블이 서로 다르기 때문에, 전체 TLB를 Flush(Invalidate) 해버린다. 근데, 이렇게 하면 모든 TLB의 내용이 사라지게 되므로, 그 이후에 모든 캐쉬 액세스는 미스가 발생된다. 그래서 몇 가지 새로운 전략을 내놓았다.
On an address-space switch, as occurs when context switching between processes (but not between threads), some TLB entries can become invalid, since the virtual-to-physical mapping is different. The simplest strategy to deal with this is to completely flush the TLB. This means that after a switch, the TLB is empty, and any memory reference will be a miss, so it will be some time before things are running back at full speed. Newer CPUs use more effective strategies marking which process an entry is for. This means that if a second process runs for only a short time and jumps back to a first process, the TLB may still have valid entries, saving the time to reload them.
Other strategies avoid flushing the TLB on a context switch: (a) A single address space operating system uses the same virtual-to-physical mapping for all processes. (b) Some CPUs have a process ID register, and the hardware uses TLB entries only if they that match the current process ID.
For example, in the Alpha 21264, each TLB entry is tagged with an address space number (ASN), and only TLB entries with an ASN matching the current task are considered valid. Another example in the Intel Pentium Pro, the page global enable (PGE) flag in the register CR4 and the global (G) flag of a page-directory or page-table entry can be used to prevent frequently used pages from being automatically invalidated in the TLBs on a task switch or a load of register CR3. Since the 2010 Westmere microarchitecture Intel 64 processors also support 12-bit process-context identifiers (PCIDs), which allow retaining TLB entries for multiple linear-address spaces, with only those that match the current PCID being used for address translation.
...
- 참고 : https://en.wikipedia.org/wiki/Translation_lookaside_buffer [ Address-space switch ]: 하드웨어가 현재 동작하는 하고 있는 프로세스와 동일한 process ID를 사용하는 TLB만 사용하도록 하는 방법이다. x86 기준으로는 `Intel Pentium Pro`에서 CR4.PGE가 이 내용과 관련이 있으며, `Intel 64`에서는 PCID가 이 내용과 관련이 있다.
- L1 & L2 [ 참고1 참고2 참고3 ]
: `Intel-chip-based` 구조에서 `Front-Side Bus(FSB)`는 CPU와 North Bridge를 연결하는 버스가 된다. 일반적으로 FSB는 프로세서 내부의 L2 캐시와 North-Bridge를 연결하고 있다. 그리고 FSB보다 더 빠른 `Back-Side Bus`가 L2와 L1을 연결하는 버스가 된다.

https://en.wikipedia.org/wiki/Front-side_bus#/media/File:Dual_Core_Generic.svg: 우리가 흔히 말하는 `시스템 버스`라는 용어는 FSB를 의미한다. 이 FSB는 CPU와 Chipset을 연결하는 버스다. 아래 그림을 보면 알 수 있을 것이다. 그리고, 시스템에는 여러 개의 버스들이 존재한다. 예를 들어,`PCI`, `AGP`, `메모리 버스`등은 모두 FSB 클락에서 파생된 클락으로 동작한다. 그러나, FSB와 동기화할 필요는 없다. 즉, 세컨더리 시스템 버스들은 시스템 버스와 비동기적으로 동작 할 수 있다는 뜻이다.

https://en.wikipedia.org/wiki/Front-side_bus#/media/File:Motherboard_diagram.svg: FSB의 속도는 일반적으로 메모리 동작 속도와 비슷하다. 왜냐면, FSB와 결국 CPU와 메모리를 관리하는 North-Bridge와 연결되어 있기 때문이다. 그리고 FSB는 `PC 마더보드`에서나 존재하는 개념이다. 즉, 개인용 컴퓨터나 서버시장에서만 사용하는 용어라는 뜻이다. 임베디드 시장에서는 사용되지 않는다.
: `Back-Side Bus(BSB)`는 인텔에서 CPU와 CPU 캐쉬를 연결하는 버스를 지칭하는 말이었다. 대개 BSB가 사용되던 시기는 L2가 프로세서 외부로 빠져있을 때 였다. 인텔에서 `CPU와 CPU 캐쉬를 연결하는 BSB`와 `CPU와 Chipset을 연결하는 FSB` 구조를 합쳐서 `Dual-Bus Architecture or Dual Independent Bus(DIB)`라고 지칭했다. L2가 프로세서 내부로 들어오면서 부터, BSB 기술이 발전하기 시작했다. 그래서 나온 기술이 `Advanced Transfer Cache` 기술이다. 아래 그림은 L2 캐쉬가 외부에 있던 시절, 칩셋 구조를 보여준다.

https://en.wikipedia.org/wiki/Back-side_bus#/media/File:Intel_MMC2_arch.svg: L2 캐쉬를 프로세서 외부로 배치했던 이유는 L2 캐쉬의 크기가 너무 컸기 때문이다. 펜티임 2시절에는 L2 캐쉬를 만들기 위해서 수백만개의 트랜지스터가 필요했다. 캐쉬는 메모리와 같은 DRAM이 아닌, SRAM을 통해 만들어진다. DRAM 같은 경우는 비트 당 하나의 트랜지스터로 만들 수 있지만, SRAM은 비트 당 6개의 트랜지스터가 필요했다. 즉, 256KB 크기의 K2 캐쉬를 만들려면 1200만개의 트랜지스터가 필요한 셈이다. 미세 공정 기술이 발전함에따라, 크기 더욱 줄어들어 L2 캐쉬가 CPU 안으로 들어올 수 있게 되었다.
: L1과 L2를 연결하는 버스의 대역폭은 아마 프로세서 구조에서 가장 빠른 대역폭을 사용해야 할 것이다. 이론적으로 이 버스의 최대 속도를 측정하려면 단순히 `(버스 대역폭 * 클락 주기) / 8` 를 적용하면 된다. 8을 나누는 이유는 결과(이론적 대역폭)의 단위가 `GigaByte` 이기 때문이다. 아래 `버스 대역폭` 컬럼은 BSB 대역폭을 의미한다.
CPU 버스 대역폭 클락 진동수[빈도] 이론적 대역폭 Intel Pentium III 64비트 1.4GHz 11.2GB/sec AMD Athlon 64 64비트 2.2GHz 17.6GB/sec Intel Pentium 4 256비트 3.2Ghz 102GB/sec - Cache Strategy
: 캐쉬와 관련된 모든 문제는 대개 데이터를 캐쉬에 쓸 때 발생한다. `캐쉬 쓰기`는 2가지 쓰기 정책이 있다.
Write-through" 캐쉬에 데이터를 쓸 때마다, 메인 메모리에도 즉각적으로 데이터를 쓴다. 심플한 전략이지만, 속도가 느리다.
Write-back" 캐쉬에 데이터를 써도 메인 메모리에 즉각적으로 쓰지않는다. 메인 메모리와 동기화가 필요한 시점에 데이터를 쓴다. 속도가 빠르지만, 복잡해진다.- Locality of reference
: `Locality reference`는 프로세서가 짧은 시간동안 반복적으로 동일한 메모리를 여러 번 액세스하는 경향을 의미한다. 일반적으로 2가지 종류가 있다.
Temporal Locality" 특정 위치에 데이터가 참조됬다면, 가까운 미래에 그 데이터가 또 다시 참조될 가능성이 높다는 것을 의미
Spatial Locality(Data Locality)" 특정 위치에 데이터가 참조됬다면, 가까운 미래에 그 주변의 데이터가 참조될 가능성이 높다는 것을 의미In computer science, `locality of reference`, also known as the `principle of locality`, is the tendency of a processor to access the same set of memory locations repetitively over a short period of time. There are two basic types of reference locality – temporal and spatial locality. `Temporal locality` refers to the reuse of specific data and/or resources within a relatively small time duration. `Spatial locality` (also termed `data locality`) refers to the use of data elements within relatively close storage locations. Sequential locality, a special case of spatial locality, occurs when data elements are arranged and accessed linearly, such as traversing the elements in a one-dimensional array.
Locality is a type of predictable behavior that occurs in computer systems. Systems that exhibit strong locality of reference are great candidates for performance optimization through the use of techniques such as the caching, prefetching for memory and advanced branch predictors at the pipelining stage of a processor core.
- 참고 : https://en.wikipedia.org/wiki/Locality_of_reference- Memory Hierarchy
Accessing main memory for each instruction execution may result in slow processing, with the clock speed depending on the time required to find and fetch the data. In order to hide this memory latency from the processor, data caching is used. Whenever the data is required by the processor, it is fetched from the main memory and stored in the smaller memory structure called a cache. If there is any further need of that data, the cache is searched first before going to the main memory. This structure resides closer to the processor in terms of the time taken to search and fetch data with respect to the main memory. The advantages of using cache can be proven by calculating the average access time (AAT) for the memory hierarchy with and without the cache.
- 참고 : https://en.wikipedia.org/wiki/Cache_hierarchyTypical memory hierarchy (access times and cache sizes are approximations of typical values used as of 2013
for the purpose of discussion; actual values and actual numbers of levels in the hierarchy vary):
CPU registers (8–256 registers) – immediate access, with the speed of the innermost core of the processor
L1 CPU caches (32 KB to 512 KB) – fast access, with the speed of the innermost memory bus owned exclusively by each core
L2 CPU caches (128 KB to 24 MB) – slightly slower access, with the speed of the memory bus shared between twins of cores
L3 CPU caches (2 MB up to a max of 64 MB) – even slower access, with the speed of the memory bus shared between even more cores of the same processor
Main physical memory (RAM) (256 MB to 64 GB) – slow access, the speed of which is limited by the spatial distances and general hardware interfaces between the processor and the memory modules on the motherboard Disk (virtual memory, file system) (1 GB to 256 TB) – very slow, due to the narrower (in bit width), physically much longer data channel between the main board of the computer and the disk devices, and due to the extraneous software protocol needed on the top of the slow hardware interface
Remote memory (other computers or the cloud) (practically unlimited) – speed varies from very slow to extremely s
- 참고 : https://en.wikipedia.org/wiki/Locality_of_reference- Cache Entry Structure [ 참고1 참고2 ]
: 실제 캐쉬의 구조는 가상 주소처럼 여러 개의 필드로 구성되어 있다. 기본적으로 3가지 정보가 포함되어 있다.

tag" 캐쉬 구조에서 인덱스와 오프셋만 사용할 경우, 여러 메모리 블락이 동일 캐쉬 라인(동일 인덱스)에 매핑될 수 있다. 이럴 경우, 해당 데이터가 메모리 몇 번지에서 온지를 알 수가 없다. 이 때, `태그`를 사용해서 해당 데이터가 메모리의 몇 번지에서 온지를 알 수 있다.
index" 인덱스는 set 혹은 캐쉬 라인을 결정 및 선택하는데 사용된다.
offset" 오프셋은 실제 접근하는 데이터 주소를 의미한다.: 캐쉬 크기가 8KB, 캐쉬 라인이 64B라고 가정하자. 그렇면, 캐쉬 블락의 개수는 총 128개가 된다. `N-way set associative` 구조에서는 set의 개수는 캐쉬 블락의 개수에서 `N`으로 나눈 값이 된다. 결국, `4-way set associative`에서 set의 개수는 `128 / 4 = 32`가 된다. set이 32개 라는 것은 인덱스는 총 5비트(2^5 = 32)가 할당된다는 뜻이다. 그리고, 캐쉬 블락 사이즈가 64바이트이므로, 64바이트 정렬을 유지해야 한다. 그러므로, offset은 6비트(2^6 = 64)가 필요하다. CPU의 할당 가능 주소를 32비트라고 가정하면, 태그는 `32 - 5 - 6 = 21`비트를 할당하면 된다. 캐쉬 엔트리의 길이는 CPU가 할당 가능한 주소와 동일하지만, 그 안에 각 필드들은 여러 조건하에 길이가 바뀔 수 있다.
The original Pentium 4 processor had a `four-way` set associative L1 data cache of 8 KiB in size, with 64-byte cache blocks. Hence, there are 8 KiB / 64 = 128 cache blocks. The number of sets is equal to the number of cache blocks divided by the number of ways of associativity, what leads to 128 / 4 = 32 sets, and hence 2^5 = 32 different indices. There are 2^6 = 64 possible offsets. Since the CPU address is 32 bits wide, this implies 32 - 5 - 6 = 21 bits for the tag field.
The original Pentium 4 processor also had an eight-way set associative L2 integrated cache 256 KiB in size, with 128-byte cache blocks. This implies 32 - 8 - 7 = 17 bits for the tag field.
- 참고 : https://en.wikipedia.org/wiki/CPU_cache: Flag bits [ 참고1 ]
" 캐쉬 구조는 위와 같은 주소 메커니즘 데이터 말고도 메타 데이터가 추가적으로 필요하다. 예를 들어, 캐시 데이터가 메인 메모리의 데이터와 다르다 던가 혹은 현재 캐시에 있는 데이터가 사용중인 데이터인지 아닌지를 나타내는 메타 데이터들이 존재할 수 있다. 캐쉬 메타 데이터는 보통 2가지가 존재한다.
Valid bit " 현재 캐쉬 라인이 사용중인지 아닌지, 즉, 사용할 수 있는지 없는지(유효한지)를 나타낸다. 무슨 의미일까? 예를 들어, 프로세스가 컨택스트 스위칭을 진행하면 페이지 테이블을 교체해야 한다. 만약, 페이지 테이블을 교체하지 않으면, 새로운 프로세스가 실행되고 있지만, 여전히 이전 프로세스의 페이지 테이블이 사용된다. 이럴 경우, TLB를 무효화(Invalid) 시켜야 한다. 이 때, 캐쉬 엔트리의 Valid bit를 `0`으로 설정해서 이 TLB가 사용이 불가능하다는 것을 프로세서에게 알려야 한다.
Dirty bit " 캐쉬안에 복사본 데이터가 수정되면, Dirty bit가 `1`이 된다. 즉, 캐쉬와 메인 메모리의 데이터가 서로 다름을 나타낸다." 명령어 캐시에는 Valid bit만 사용된다. 왜냐면, 명령어(코드, 텍스트)는 `READ-ONLY` 이기 때문이다. 데이터 캐시에는 Valid bit, Dirty bit가 모두 존재한다.
- Cache Placement Poliies [ 참고1 참고2 ]
: `캐쉬 배치 정책`은 메인 메모리에서 가져온 데이터를 캐쉬안에 어디에 저장해야 하는지에 대한 내용이다. 기본적으로 `캐쉬 배치 정책`은 3 가지가 존재한다.
Direct-mapped" 메인 메모리에 특정 데이터는 캐쉬안에 대응하는 딱 하나의 캐쉬 엔트리에만 저장되어야 한다.
Fully associative" 메인 메모리에서 가져온 데이터를 캐쉬안에 제약없이 아무 캐쉬 엔트리에나 저장이 가능하다.
N-way set associative" 메인 메모리에서 가져온 데이터를 캐쉬안에 N개의 캐쉬 엔트리 중 하나에 저장이 가능하다. 예를 들어, `2-way set associative`같은 경우, 메인 메모리에서 가져온 데이터를 캐쉬안에 2개의 캐쉬 엔트리 중 하나에 저장이 가능하다.: 캐쉬 구조를 설명할 때, `캐쉬 세트`라는 용어가 나온다. 캐쉬 세트를 한 개 혹은 여러 개의 캐쉬 세트를 포함하는 `캐쉬 행(cache row)`를 의미한다. 예를 들어, 아래에서 보겠지만, `4-way set associative` 같은 경우 1개의 캐쉬 세트(캐쉬 행)에 4개의 캐쉬 라인이 포함된 것을 의미한다.
: Direct-mapped cache [ 참고1 ]
" `direct-mapped cache`는 메인 메모리와 캐쉬 엔트리가 1:1 대응된다. `direct-mapped cache`의 구조는 여러 개의 set 들을 가지며, 각 set 당 하나의 캐쉬 라인을 갖는다. 아래 예시를 보자. RAM 사이즈는 16KB, 메모리한 블락은 4B, `direct-mapped cache`는 256B, 한 개의 캐쉬 블락은 4B 라고 가정하자. `direct-mapped cache`에서 전체 set 개수는 `256 / 4 = 64`가 된다(`전체 캐쉬 사이즈 / 캐쉬 블락 사이즈`). `direct-mapped cache`에서는 set과 캐쉬 라인이 1:1 대응이므로, 캐쉬 라인 개수도 64개가 된다.
: `direct-mapped cache` 에서 사용하는 캐쉬 엔트리 구조는 `offset`, `index`, `tag` 로 구성되어 있다. 캐쉬 라인이 4B 이므로, 오프셋은 2비트를 할당하면 된다. 인덱스는 set(캐쉬 라인)를 식별한다. 아래에서 사용가능한 set의 개수는 64이므로, 인덱스에게는 6비트를 할당한다. 태그는 남은 비트를 할당하면 된다(`14 - ( 6 + 2 ) = 6`).

https://en.wikipedia.org/wiki/Cache_placement_policies#/media/File:Direct-Mapped_Cache_Snehal_Img.png: `direct-mapped cache` 에서 사용하는 캐쉬 엔트리 구조는 `offset`, `index`, `tag` 로 구성되어 있다. 캐쉬 라인이 4B 이므로, 오프셋은 2비트를 할당하면 된다. 인덱스는 set(캐쉬 라인)를 식별한다. 아래에서 사용가능한 set의 개수는 64이므로, 인덱스에게는 6비트를 할당한다. 태그는 남은 비트를 할당하면 된다(`14 - ( 6 + 2 ) = 6`). 아래 예시를 보자.
메모리 블락0 (주소 0x0000)"
- tag : 0b00_0000 , index : 0b00_0000, offset : 0b00
" 캐쉬 세트0 에 대응된다.
메모리 블락1 (주소 0x0004)"
- tag : 0b00_0000 , index : 0b00_0001, offset : 0b00
" 캐쉬 세트1 에 대응된다.
메모리 블락63 (주소 0x00FF)"
- tag : 0b00_0000 , index : 0b11_1111, offset : 0b00
" 캐쉬 세트 63 에 대응된다.
메모리 블락64 (주소 0x0100)"
- tag : 0b00_0001 , index : 0b00_0000, offset : 0b00
" 캐쉬 세트 0 에 대응된다.: 메모리 블락0과 메모리 블락64는 동일한 인덱스를 사용한다. 그래서 기존에 메모리 블락0이 캐쉬 세트0에 있었을 경우, 그 후에 메모리 블락64가 캐쉬 세트0에 오버라이트 하게 된다. 그리고 여기서 `태그`를 통해, 동일한 캐쉬 세트에 대응하는 메모리 블락이 구분되는 것을 확인할 수 있다.
: `direct-mapped cache`는 검색 및 배치 시간 복잡도가 O(1)이다. 검색과 배치 알고리즘 또한 매우 심플하다. 보다시피, 정해진 한 곳에만 배치 및 검색해야 하기 때문에 굉장히 심플하면서 속도가 빠르다. 그러나, 이 캐쉬 구조는 캐쉬 미스가 어마어마하다. 공간 활용 및 유연성이 고정적이기 때문에 거의 매번 캐쉬 미스가 발생한다고 봐도 무방하다.
: Fully associative cache [ 참고1 ]
" 하나의 `set`만 존재하고 하나의 set안에 모든 cache lines들이 들어가는 구조다. 아래 예시를 보자. RAM 사이즈는 16KB, 메모리한 블락은 4B, `fullay associative cache`는 256B, 한 개의 캐쉬 블락은 4B 라고 가정하자. `fullay associative cache`는 전체 set 개수가 1개다. 그리고 이 set이 포함하는 캐쉬 라인의 개수는 `256/4 = 64`개가 된다(캐쉬 총 크기 = 256 , 캐쉬 블락 크기 = 4). `fullay associative cache` 에서 사용하는 캐쉬 엔트리 구조는 `offset`, `tag` 2개의 필드로 구성되어 있다.

https://en.wikipedia.org/wiki/Cache_placement_policies#/media/File:Fully-Associative_Cache_Snehal_Img.png: `offset`은 프로세서가 캐쉬 라인에 접근할 때, 바이트를 결정해준다고 보면 된다. 캐쉬 구조가 페이지 테이블과 동일하다. 페이지 테이블에서 페이지 넘버와 페이지 오프셋이 있다. 이 오프셋이 캐쉬에서도 동일하게 적용된다고 보면 된다. 여기서는 4바이트 정렬이기 때문에, offset은 2비트면 충분하다. 예를 들어, 메모리 주소 0xFFF0이 들어오면,
: `tag`는 페이지 테이블에서 페이지 넘버와 동일하다고 보면 된다. 이 `tag`의 사이즈는 offset에서 사용하고 남은 12비트가 된다. 캐쉬 요청이 올 때마다, 오프셋이 아닌 `tag`를 기준으로 존재 여부를 판단한다.
: 예를 들어, 캐쉬가 아주 깨끗한 상태라고 가정하자. 여기서 메모리 주소 `0xFFF0`가 `fullay associative cache` 로 들어오면 어떻게 될까? 접근되는 주소는 다음과 같다.
0" tag - 0b11111111111111, offset - 0x00 , 주소 :
1" tag - 0b11111111111111, offset - 0b01 , 주소 :
2" tag - 0b11111111111111, offset - 0b10 , 주소 :
3" tag - 0b11111111111111, offset - 0b11 , 주소 : 0xFFF: 즉, `0xFFF0`가 `fullay associative cache` 에 저장되면, [0xFFF3:0xFFF0] 까지는 캐쉬를 통해서 액세스가 가능하다.
: 이 방법을 `배치`와 `검색` 측면에서 알아보자. 먼저 `배치`측면에서 보면, 이 방법은 아주 효율적이다. 메모리 주소를 아무데나 저장할 수 있다. 그러나, 캐쉬가 가득 차 있을 경우에는 기존에 있던 캐쉬를 제거하고 새로운 캐쉬를 로드 해야한다. 그런데, 어떤 캐쉬를 대체해야 할 지를 결정해야 한다. 이 때, `캐쉬 교체 알고리즘`을 사용해야 하는 약간의 번거로움이 있다. 그러나, `fullay associative cache`는 공간 효율성 면에서는 최고의 캐쉬 구조라고 할 수 있다.
: `검색` 측면에서는 최악이다. `fullay associative cache` 구조는 정해진 위치에 저장되는 해쉬 테이블같은 구조가 아니기 때문에, 만약에 액세스 하려는 데이터가 캐쉬에 없을 경우, 모든 캐쉬 라인을 검색한 뒤에야 캐쉬에 없다는 것을 알게된다. 즉, 검색에서는 시간 복잡도가 최악이다.
: Set-associative cache [ 참고1 ]
" 이 캐쉬 구조는 예시를 통해 이해하는게 가장 빠르다. `direct-mapped cache` 에서 메모리 블락[0]과 메모리 블락[64]이 동일한 캐쉬 세트로 매핑해서 오버라이트가 됬다. `2-way set associative` 캐쉬 구조를 사용하면, 메모리 블락[64]가 메모리 블락[0]을 오버라이트하지 않는다. 왜냐면, `2-way set associative` 에서는 1개의 캐쉬 세트에 2개의 캐쉬 라인이 존재하기 때문이다.
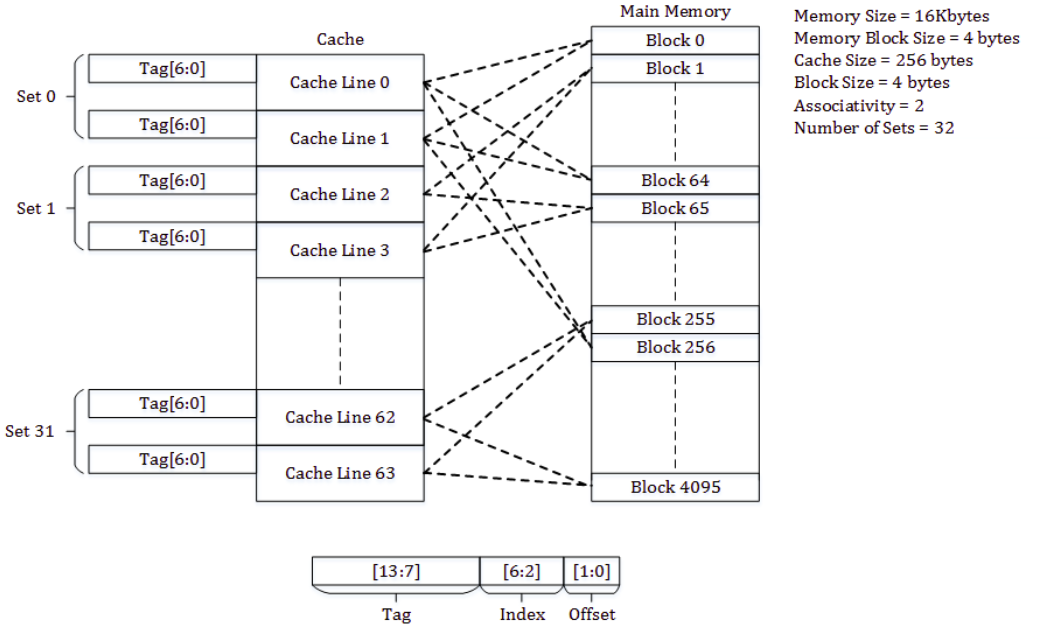
https://en.wikipedia.org/wiki/Cache_placement_policies#/media/File:Set-Associative_Cache_Snehal_Img.png: 아래 그림에서 볼 수 있다시피, 메모리 블락[0]이 캐쉬 세트0의 Way[0]에 저장되면, 메모리 블락[64]는 캐쉬 세트[0]에 Way[1]에 저장된다(`2-way` 이기 때문에 index에 할당되는 비트가 `direct-mapped cache` 구조와는 다르게 5비트를 할당한다(64/2)). 이 구조를 보다보면, `direct-mapped cache` 구조가 `1-way set associative` 구조인 것을 알 수 있다. 오늘날의 대부분의 프로세서는 `direct-mapped cache`, `2-way set associative`, `4-way set associative` 구조를 사용한다.

https://en.wikipedia.org/wiki/CPU_cache#/media/File:Cache,associative-fill-both.png- Cache Prefetching [ 참고1 ]
" `Perfetching`의 기본 개념은 데이터를 한 번에 크게 가져와서, 캐쉬 미스를 최소화 하겠다는 전략이다. 이러한 조건에는 반드시 전제가 있어야 한다. 바로, 데이터가 메모리상에서 분산되어 있지 않고, 연속적으로 배치되어 있음을 전제로 한다(`Spatial Locality`). 아래 내용은 인텔 `FPGA SDK for OpenCL` 관련 문서에서 발췌한 내용이다. 아래와 같이 루프문과 배열을 이용하는 코드는 `Cache Prefetching` 관련 대표적인 코드들이다.
Prefetching
Prefetching data or instructions from a slower global memory to the local cache can improve performance of algorithms on modern processors. `Prefetching` data works best when you access your `data sequentially rather than from random locations` in the memory. `Blocks of data` are copied one time from the global memory to cache, thus `minimizing cache misses` and frequent data fetch to the cache. For example, consider adding one million numbers from an array in the global memory, as shown in the following code snippet:
For each data access, CPU verifies if the data is available in its cache and if not, it loads the data from the global memory to its local cache and adds the data to the Sum. Changing the above code to prefetch data with additional directives reduces cache misses. This can improve the performance of the code many folds. *NX platforms have built-in APIs for prefetching.Sum = 0;
for (int i = 0; i < 1000000; ++i) {
Sum += a[i];
}
...
- 참고 : AN 831: Intel FPGA SDK for OpenCL: Host Pipelined Multithread- False sharing[참고1]
: false sharing 이란 전혀 연관성이 없는 변수들이 동일한 cache line 에 있는 경우에 발생하는 문제다. 이건 예시를 통해서 알아보는 것이 가장 빠르다. 전혀 연관성없는 데이터 A, B는 각각 동일하게 16바이트를 차지하며, 주소도 16바이트에 정렬되어 있다고 가정한다. 그리고, 또 데이터 A, B는 서로 메모리에서 매우 근접한 위치에 저장되어 있다고 전제한다. 그리고, 캐쉬 단위는 64바이트로 가정한다.

: 이런 경우 메모리에서 캐쉬로 로드될 때, 데이터 A, B 는 동일한 cache line 에 위치하게 된다. 그림으로 표현하면 위와 같이 캐쉬에 저장될 것이다. 여기서 한 가지 가정을 더 추가하자. CPU[0] 은 데이터 A 랑만 연관성이 있고, CPU[1] 은 데이터 B 랑만 연관성이 있다.
(1) CPU[0] 이 데이터 A 를 읽었다. 이 때, CPU[0] 의 L1 캐쉬에 데이터 A 가 로드된다. 그런데, 캐쉬의 단위는 64바이트이기 때문에 캐쉬 컨트롤러는 메모리에서 데이터 A를 기준으로 64바이트만큼 CPU[0]의 L1 캐쉬에 읽어온다. 이 때, 데이터 B 도 데이터 A 와 같은 캐쉬 라인에 캐쉬되게 된다. 이제 이 캐쉬 라인의 상태를 `Exclusive state` 로 설정한다.
(2) CPU[1] 이 데이터 B를 읽어야 하는 경우가 발생했다. 그런데, 데이터 B 가 CPU[0] 의 L1 캐쉬에 저장되어 있다. 그래서, CPU[1] 은 메모리에서 데이터 B 를 가져오지 않고, CPU[0] 의 L1 캐쉬에서 데이터 B를 받아오게 된다. 그런데, 이 때, 캐쉬 라인 단위로 데이터를 가져오기 때문에 CPU[1] 에 데이터 A 까지 같이 저장되게 된다. 이 시점에 CPU[0] 과 CPU[1] 의 해당 캐쉬 라인은 `Shared state` 로 변경딘다.
(3) CPU[0] 이 데이터 A를 수정해야 하는 경우가 발생했다. CPU[0] 은 데이터 A 가 공유되어 있는 것을 확인하고 CPU[1] 에 캐쉬 무효화(invalid) 메시지를 전달하고 CPU[1] 은 데이터 A 에 대응하는 캐쉬 라인을 무효화한다. 그리고, CPU[0] 은 해당 캐쉬 라인을 `Modified state` 로 변경하고 데이터 A 를 수정한다.
(4) CPU[1] 이 데이터 B를 수정해야 경우가 발생했다. 그런데, 이 시점에 CPU[1] 의 L1 캐쉬에는 데이터 B 가 캐쉬되어 있지않다. 그래서, CPU[1]은 CPU[0] 에게 메시지를 보내고 CPU[0]은 데이터 B 를 CPU[1]에 반환한다. 그리고, CPU[0] 의 L1 캐쉬에 데이터 B가 캐쉬 되어있으므로, 데이터 B 에 대응하는 캐쉬 라인을 모두 무효화(invalid) 시킨다. 그리고, 데이터 B 에 대응하는 CPU[1] 의 L1 캐쉬 라인의 상태를 `Modified state` 로 변경한다. 이제 CPU[1] 은 데이터 B를 수정할 수 있다.
: 위의 상황에서 (3), (4) 번이 반복되면 어떻게 될까? 전혀 연관성없는 데이터 A, B 가 동일 캐쉬 라인에 저장되다 보니 캐쉬 미스가 무한 반복될 것 이다. 이러한 현상을 `false sharing` 이라고 한다. 이 문제를 어떻게 해결할까? 해결책은 명확하다. 데이터 A, B 를 동일 캐쉬 라인에 두면 안된다. 그렇다면, 동일 캐쉬 라인에 두지 않으려면 어떻게 해야할까? 데이터 A, B 주소를 각각 캐쉬 라인에 정렬시켜야 한다. 물론, 메모리 낭비가 trade-off 로 따라오게 된다.

: 위와 같이 데이터 A, B 가 각각 캐쉬 라인에 정렬되면 서로 영향을 주지 않게된다. 각 캐쉬 라인의 상태는 항상 `Modified` 상태를 유지할 수 있고, MESI 프로토콜이 지속적으로 메시지를 전송할 일이 없어지기 때문에 포퍼먼스가 증가한다. 리눅스에서 이와같은 캐쉬 라인 사이즈에 맞게 데이터 주소를 정렬시키는 기능을 하는 함수는 없다. 대신 GCC 컴파일러에서 ____cacheline_aligned 와 __cacheline_aligned_in_smp 속성이 있다. SMP 환경에서 정적(static)으로 선언되는 전역 변수 같은 경우에 __cacheline_aligned_in_smp 속성을 사용하는 경우를 종종 관찰할 수 있다.
- Case study
: 커널 2.2 & 2.4 까지만 해도 프로세스 플래그가 전역 변수였다고 한다. 그런데, 2.6에서 `thread_info` 구조체안으로 플래그 변수를 이동시켰다. 그러면서, 전역 변수가 아닌 `current` 매크로를 각 프로세서에서 현재 실행중 인 프로세스에 액세스가 가능해지면 더 지역적인 캐쉬에 데이터를 저장할 수 있도록 했다. 예를 들어, 모든 프로세서에서 접근이 가능한 변수는 각 프로세서의 캐쉬에 저장하기가 곤란하다. 혹은, 모든 프로세서가 공유하는 L3 같은 캐쉬에 저장되기 한다. 그런데, 각 프로세서에서 개별적으로 접근이 가능한 데이터들은 L1 같은 캐쉬에 저장하는 것이 더 좋다.
The flag is per-process, and not simply global, because it is faster to access a value in the process descriptor (because of the speed of `current` and high probability of it being in a cache line) than a global variable. Historically, the flag was global before the 2.2 kernel. In 2.2 and 2.4, the flag was an `int` inside the `task_struct`. In 2.6, it was moved into a single bit of a special flag variable inside the `thread_info` structure. As you can see, the kernel developers are never satisfied...
- 참고 : http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch04lev1sec3.html'공학 > 컴퓨터구조' 카테고리의 다른 글
[컴퓨터 구조] Soft(Warm) reset(reboot) vs Hard(Cold) reset(reboot) (1) 2023.08.15 Boot ROM (0) 2023.08.13 [컴퓨터 구조] MMIO (0) 2023.08.11 Port-Mapped IO (1) 2023.08.11 [컴퓨터 구조] AHCI (0) 2023.08.10