-
[리눅스 커널] Data structure - Linked listLinux/kernel 2023. 8. 5. 03:04
글의 참고
- https://en.wikipedia.org/wiki/Doubly_linked_list
- https://stackoverflow.com/questions/10262017/difference-between-list-head-init-and-init-list-head
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다.
글의 내용
- 리스트 자료구조
: 리스트 구현 시, 고민이 되는 부분은 자료구조다. 알고리즘은 사실 자료구조를 어떻게 구성하느냐에 따라 쉬워지다가도 어려지는 내용이라서 자료구조를 잘 만들어야 한다. 대학교때 배우는 정석적인 리스트는 순차탐색으로 다음 노드만을 가리킨다. 즉, 이전으로 돌아올 수 있는 방법이 없다. 그러나 실생활에서는 그런 이론에만 충실한 리스트는 사실 거의 쓸모가 없다. 리스트란 자고로 탐색을 위한 자료구조다. 그러므로, 탐색에 최적화 되어 있어야 한다. 앞과 뒤로 쉽게 탐색이 가능해야 한다.
: 그러면 어떻게 자료 구조를 구성해야 할까? 처음에는 head, tail만 있으면 될 듯 싶다. 왜냐면, 데이터를 삽입관점에서 리스트는 대개는 맨 앞과 맨 뒤에 넣는 경우가 많기 때문이다. 그런데 대개 위와 같은 구성은 리스트 노드이 자료 구조가 아닌 리스트를 관리하는 자료 구조에서 주로 쓰인다. 리스트를 관리하는 자료구조는 현재 리스트내의 항목 개수, head와 tail의 관리등 각 상황에 따라 달라진다. 그래서 별도로 리스트 관리에 대한 자료구조는 존재하지 않는다. 각자 자신의 상황에 따라 리스트 관리 자료구조를 만들 수 있다. 다시 리스트 노드 자료 구조로 돌아와서, 각 리스트 노드는 앞뒤로 연결되어 있어야 탐색이 수월하다. 그러므로, 각 노드에는 prev, next 포인터가 필요할 듯 하다.
: 별도로 리스트 관리를 위해 head, tail을 자료구조를 만드는 것 또한 사실 알고리즘의 단순함을 깨트릴 가능성이 높다. 왜냐면, 리스트를 관리하는 자료구조를 별도로 둘 경우, 해당 자료구조는 리스트 자료구조를 위한 자료구조이므로, 리스트 자료구조와 강하게 연관될 수 밖에 없는 관계가 형성된다. 보다 범용적으로 만들기 위해서는 자료는 단순하게 만들어야 한다. 즉, 리스트 자료구조는 리스트 노드 하나만 있으면 되고, 리스트 노드는 prev, next만 있으면 된다.
: 그렇면 다시 돌아와서 prev, next를 통해서 간단하게 탐색 및 추가를 쉽게 하는 방법은 `순환 리스트`를 만들면 된다. 즉, head 노드의 prev는 last 노드, last 노드의 next는 head 노드를 가리키면 된다. 구현을 하다보면 자연스러운 생각이다. 이 내용을 고민해보지 않고, 냅다 리눅스 코드를 먼저 보면 내 추론에 대한 과정이 사라지게 된다. 그러면 결국 남의 설명을 보면서 공부하고 있다는 착각에 빠지게 된다. 이건 진짜 공부라고 하기에는 다소 거리가 있다.
- 리스트 초기화
" 리눅스 커널의 circular doubly linked list 의 초기화는 다음과 같다. 초기화는 2개로 나눌 수 있다.
1. both 생성 & 초기화 : LIST_HEAD
2. only 초기화 : LIST_HEAD_INIT, INIT_LIST_HEAD// include/linux/list.h - v6.5 /* * Circular doubly linked list implementation. * * Some of the internal functions ("__xxx") are useful when * manipulating whole lists rather than single entries, as * sometimes we already know the next/prev entries and we can * generate better code by using them directly rather than * using the generic single-entry routines. */ #define LIST_HEAD_INIT(name) { &(name), &(name) } #define LIST_HEAD(name) \ struct list_head name = LIST_HEAD_INIT(name) /** * INIT_LIST_HEAD - Initialize a list_head structure * @list: list_head structure to be initialized. * * Initializes the list_head to point to itself. If it is a list header, * the result is an empty list. */ static inline void INIT_LIST_HEAD(struct list_head *list) { WRITE_ONCE(list->next, list); WRITE_ONCE(list->prev, list); }" 위에서 LIST_HEAD_INIT 과 INIT_LIST_HEAD 는 `->next` 와 `->prev` 가 자기 자신을 바라보게 하는 코드다. 그렇다면, 왜 2개의 함수를 분리했을까?
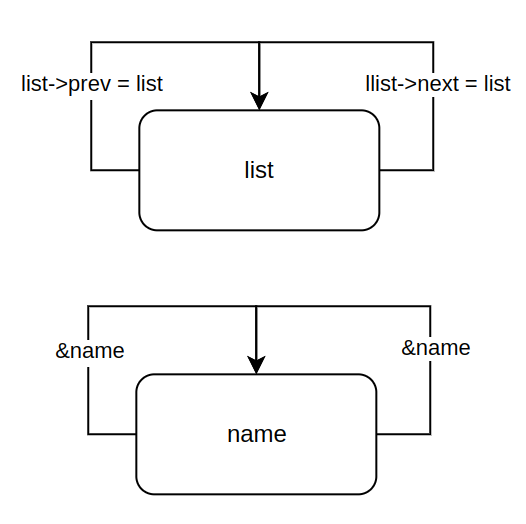
" 2개의 차이는 반환값의 여부로 나뉜다. LIST_HEAD_INIT() 은 반환값이 있고, INIT_LIST_HEAD() 는 반환값이 없다. 예를 들어, 아래와 같이 lst2 는 자기 자신을 인자로 던져서, `->prev` 와 `->next` 를 초기화해서 받을 수 있다. 그러나, 사실 엄밀히 따지면 매크로이기 때문에 반환이 아닌, 치환이 맞다.
// https://stackoverflow.com/questions/10262017/difference-between-list-head-init-and-init-list-head struct list_head lst1; /* .... */ INIT_LIST_HEAD(&lst1); struct list_head lst2 = LIST_HEAD_INIT(lst2); // struct list_head lst2 = { &lst2, &lst2 };" 또한, circular doubly linked list 의 장점은 다음과 같다.
1" 기존의 리스트들은 리스트 관리를 위해 HEAD 와 TAIL을 선언했지만, 순환 이중 연결 리스트는 HEAD만 있으면 된다.
2" 앞, 뒤로 노드의 검색, 삽입, 삭제가 편하다. 즉, 연결 리스트의 알고리즘이 단순해진다.- 리스트 삽입
" 리눅스 커널 `리스트 추가` 함수에서 베이스가 되는 함수다. 새로 추가되는 노드(new)를 `prev`와 `next`사이에 저장한다.
// include/linux/list.h - v6.5 /* * Insert a new entry between two known consecutive entries. * * This is only for internal list manipulation where we know * the prev/next entries already! */ static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next) { if (!__list_add_valid(new, prev, next)) return; next->prev = new; new->next = next; new->prev = prev; WRITE_ONCE(prev->next, new); }" 다양한 파생 함수들이 나올 수 있다. `list_add` 함수는 새로 추가되는 노드를 head가 가리키게 된다. 즉, 새로운 노드가 추가되면 리스트의 맨 앞에 오는 구조다. `list_add_tail` 함수는 새로 추가되는 노드가 제일 마지막 노드가 되는 구조다.
1. list_add - 첫 번째 인자를 두 번째 인자 바로 뒤에 추가한다.
2. list_add_tail - 첫 번째 인자를 두 번째 인자 바로 앞에 추가한다.// include/linux/list.h - v6.5 /** * list_add - add a new entry * @new: new entry to be added * @head: list head to add it after * * Insert a new entry after the specified head. * This is good for implementing stacks. */ static inline void list_add(struct list_head *new, struct list_head *head) { __list_add(new, head, head->next); } /** * list_add_tail - add a new entry * @new: new entry to be added * @head: list head to add it before * * Insert a new entry before the specified head. * This is useful for implementing queues. */ static inline void list_add_tail(struct list_head *new, struct list_head *head) { __list_add(new, head->prev, head); }" `list_add` / `list_add_tail` 함수의 두 번째 인자 이름이 `head`라고 해서 진짜 `head`가 온다고 생각하면 된다. 위에 함수들은 굉장히 유연한 함수들이다. 그렇기 때문에, 헤드가 아니라 리스트 임의의 위치를 전달하더라도 해당 위치를 기준으로 새로운 노드를 추가한다.
" 리스트 삽입 시에, 주의 점은 반드시 새로운 노드의 링크먼저 처리를 해야 한다는 것이다. 새로 추가되는 노드의 링크들을 먼저 연결시키지 않고, 기존에 있던 노드들의 링크를 먼저 새로운 노드에 연결시키면 링크를 잃어버리게 된다.
struct list_node *list_add_head(struct list_node *head, struct list_node *new) { if(head == NULL || new == NULL) return NULL; new->prev = head; new->next = head->next; head->next->prev = new; head->next = new; return new; } struct list_node *list_add(struct list_node *head, struct list_node *new) { if(head == NULL || new == NULL) return NULL; new->prev = head->prev; new->next = head; head->prev->next = new; head->prev = new; return new; }" 단순 기능만 넣은 리스트 추가 함수다. 주의점 몇 가지만 알고 가자.
1" 반드시 새로 추가되는 노드의 링크부터 연결한다.
2" prev 링크부터 연결할 지, next 링크부터 연결할지에 대한 기준을 정하자. 나는 prev 링크부터 연결하기로 정했다.
3" 헤드 노드를 변경할 때, 마지막 노드의 링크를 먼저 변경하고 마지막 노드를 변경해야 한다." `헤드 노드를 변경할 때, 마지막 노드의 링크를 먼저 변경하고 마지막 노드를 변경해야 한다`의 의미는 아래와 같다.
void list_add_head(struct list_node *head, struct list_node *new) { if(head == NULL || new == NULL) return -EINVAL; ... head->next->prev = new; head->next = new; ... return 0; } void list_add(struct list_node *head, struct list_node *new) { if(head == NULL || new == NULL) return -EINVAL; ... head->prev->next = new; head->prev = new; ... return 0; }" 위에서 `head->next->prev = new`와 `head->next = new`의 위치가 바뀌면 안된다. 마찬가지로, `head->prev->next = new`와 `head->prev = new` 도 위치가 바뀌면 안된다. 반드시 마지막 노드의 링크를 먼저 변경한 뒤, 마지막 노드를 변경해야 한다.
- 리스트 삭제
struct list_node *list_del(struct list_node *head, struct list_node *node) { if(head == NULL || node == NULL) return NULL; if(head->prev == head && head->next == head) return NULL; node->next->prev = node->prev; node->prev->next = node->next; return node; }" 기존 연결 리스트들은 삭제를 위해서 몇 가지 예외 케이스들에 대해 if문이 늘어나지만, 순환 이중 연결리스트는 그런게 전혀 없다. HEAD만 있는 경우, 맨 뒤에 노드를 삭제해야 하는 경우, HEAD와 노드가 딱 한 개만 있는 경우등 전부 위의 알고리즘으로 해결이 된다.
" 리스트의 삭제는 prev 와 next 가 각각을 바라보게 함으로써 자신(요소) 을 리스트에서 제외한다.
// include/linux/list.h - v6.5 /* * Delete a list entry by making the prev/next entries * point to each other. * * This is only for internal list manipulation where we know * the prev/next entries already! */ static inline void __list_del(struct list_head * prev, struct list_head * next) { next->prev = prev; WRITE_ONCE(prev->next, next); } static inline void __list_del_entry(struct list_head *entry) { if (!__list_del_entry_valid(entry)) return; __list_del(entry->prev, entry->next); } /** * list_move_tail - delete from one list and add as another's tail * @list: the entry to move * @head: the head that will follow our entry */ static inline void list_move_tail(struct list_head *list, struct list_head *head) { __list_del_entry(list); list_add_tail(list, head); }" list_move_tail() 같은 경우는 자신을 자신이 속한 리스트에서 제거한 후 두 번째 인자인 head 리스트의 끝쪽에 자신을 추가한다.
- 리스트 탐색
" 탐색에 대해 많이 고민해봤다. 내가 내린 결론은 `헤드 노드, void *, 함수 포인터`를 인자로 던지는 것이 었다. 함수 포인터는 첫 번째 인자로 리스트 노드를 받고, 두 번째 인자로는 void *를 받아서 커스텀 비교 함수를 통해 원하는 리스트를 찾으려고 했다. 그러나 리눅스쪽을 확인해봤는데, 나와는 다른 결론인 듯 하다. 리눅스에서는 리스트 탐색 기능을 별도로 제공하지 않는다. `list_for_*` 매크로 함수를 제공하여 사용자가 알아서 리스트 탐색을 수행하도록 한다. C언어의 묘미는 매크로의 활용인데, list_for_* 관련 매크로 함수들을 보면 매크로를 아주 제대로 활용했다.
- list empty
" linked list 에 new entry 가 추가되면, 반드시 ->next 에 연결된다. 그런데, ->next 가 자기 자신을 바라본다는 것은 list 가 empty 라는 것을 의미한다. 왜 그럴까? linked list 를 초기활 때, ->prev 와 ->list 를 자기 자신으로 초기화하기 때문이다.
// include/linux/list.h - v6.5 /** * list_empty - tests whether a list is empty * @head: the list to test. */ static inline int list_empty(const struct list_head *head) { return READ_ONCE(head->next) == head; }- 리스트 요소 얻기
" 리스트의 요소를 얻어오는 베이스 함수는 `list_entry` 함수다. `container_of`의 원형을 그대로 사용하고, 이름만 바꿨다.
/include/linux/list.h /** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. */ #define list_entry(ptr, type, member) \ container_of(ptr, type, member)" 아래 매크로 함수들에서 `type` 유무를 주의해야 한다. 왜 앞에 2개의 함수는 `type`이 필요할까? 왜냐면, 앞에 두 함수의 `ptr`이 `struct list_head`이기 때문이다. `list_entry` 함수는 리스트를 통해서 리스트를 멤버 변수로 가지는 `type`을 반환해주는 함수다. 그런데, 리스트를 통해서 `type`을 반환하려면 `type`의 정보를 알아야 한다. 그래서 `type`을 인자로 전달해줘야 한다.
" 그러나, 뒤에 2개의 함수는 `type(pos)`을 받아서 next 혹은 prev `type`을 반환해주는 함수다. 이미 전달된 인자가 `type`을 가지고 있기 때문에 굳이 `type`을 인자로 받을 필요가 없는 것이다.
// include/linux/list.h - v6.5 .... /** * list_first_entry - get the first element from a list * @ptr: the list head to take the element from. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. * * Note, that list is expected to be not empty. */ #define list_first_entry(ptr, type, member) \ list_entry((ptr)->next, type, member) /** * list_last_entry - get the last element from a list * @ptr: the list head to take the element from. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. * * Note, that list is expected to be not empty. */ #define list_last_entry(ptr, type, member) \ list_entry((ptr)->prev, type, member) .... .... /** * list_next_entry - get the next element in list * @pos: the type * to cursor * @member: the name of the list_head within the struct. */ #define list_next_entry(pos, member) \ list_entry((pos)->member.next, typeof(*(pos)), member) /** * list_prev_entry - get the prev element in list * @pos: the type * to cursor * @member: the name of the list_head within the struct. */ #define list_prev_entry(pos, member) \ list_entry((pos)->member.prev, typeof(*(pos)), member) ...." list_first_entry() 함수는 첫 번째 인자로 전달된 list(ptr) 의 첫 번째 인자를 반환한다. 두 번째는 type 이며, 세 번째는 멤버 변수의 이름을 기입해야 한다. 예를 들어, 아래와 같은 구조체가 있다고 하자. 이 때 `list_first_entry(list, int, eye);` 와 같이 호출할 수 있다.
struct yohda { int eye; char noise; };" 그리고, 앞에 2개의 함수는 주의점이 있다. 리눅스 커널은 양방향 순환 연결 리스트를 사용한다. 그렇기 때문에, 맨 앞과 맨 뒤 노드를 얻으려면 head 노드만 있으면 된다. 즉, 맨 앞 2개의 함수는 첫 번째 인자로 반드시 `head`가 와야한다.
- 리스트 주의 사항
struct list_node *node; ... // 비정상 list_add(frees->head, node); list_del(inuses->head, node); // 정상 list_del(inuses->head, node); list_add(frees->head, node); ..." 위에서 `추가 후 삭제` , `삭제 후 추가`는 무슨 차이가 있을까? 첫 번째는 안되고 두 번째는 된다. 왤까? 리스트의 인자는 포인터다. 근데, list_add()에 들어가면 node의 prev와 next가 바뀌게 된다. 그 후에, list_del()로 들어간다. list_del()은 두 번째 인자의 노드가 첫 번째 인자의 리스트에 연결되어 있다고 전제한다. 그런데, list_add() 함수를 진행하고 온 node의 prev와 next는 이미 frees 리스트쪽에 연결되어 있어서 inuses쪽에서 예상치 못한 행동을 하게 된다. 이 문제는 node가 하나의 연결 리스트에만 연결되어 있으면 문제가 없을까? 만약, 아래와 같이 동일한 리스트에서 `추가 후 삭제`를 해도 마찬가지로 삭제에 이상한 행동을 하게 된다. 그러므로, 리스트에서 반드시 `삭제 후 추가`를 한다.
struct list_node *node; ... // 비정상 list_add(frees->head, node); list_del(frees->head, node); // 정상 list_del(inuses->head, node); list_add(inuses->head, node); ...'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] container_of (0) 2023.08.05 [리눅스 커널] debug - dynamic debug (0) 2023.08.05 [리눅스 커널] pinctrl - raspberry pi 3 overview (0) 2023.08.04 [리눅스 커널] SMP - cpumask (0) 2023.08.03 [리눅스 커널] CPU topology (0) 2023.08.03