-
부트 로더프로젝트/운영체제 만들기 2023. 8. 3. 22:43
글의 참고
- https://academickids.com/encyclopedia/index.php/X86_assembly_programming_in_real_mode
- https://wiki.osdev.org/Real_Mode
- https://wiki.osdev.org/Memory_Map_(x86)
- https://wiki.osdev.org/Bootable_Disk
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
- `글의 참조`에서 빨간색 볼드체로 체크된 링크는 이 글을 작성하면 가장 많이 참조한 링크다.
- `운영체제 만들기` 파트에서 퍼온 모든 참조 글들과 그림은 반드시 `이 글과 그림을 소스 코드로 어떻게 구현을 해야할까` 라는 생각으로 정말 심도있게 잠시 멈춰서 생각해봐야 실력이 발전한다.
글의 내용
- 부트 로더 할 일
: 리얼 모드의 부트 로더에서 크게 해야할 일은 다음과 같다.
1" 간단한 텍스트 문자 출력
2" 디스크에서 보호 모드 부트 로더 및 커널 로딩
3" 각 모드로 진입 하기전 사전 준비 작업: 디버깅이 필요없다면, 문자 출력을 할 필요는 전혀 없다. 그냥 BIOS 기능 이용해서 문자를 출력해도 된다. 즉, 복잡하게 어셈블리언어로 VGA 드라이버를 작성하지 않아도 된다는 것이다. VGA 드라이버 작성은 보호 모드부터 작성해도 된다. 그러나, 어차피 작성해야 하는거 리얼 모드에서 작성을 해 놓으면 편하다.
: 그리고 BIOS가 최초에 디스크에서 메모리로 로딩하는 양은 512B 밖에 안된다. 즉, 우리가 작성한 부트 로더만 메모리에 로딩이 된다. 그런데, 우리는 VBR에서 두 번째 부트 로더를 불러올거고, 32비트 커널, 64비트 커널까지 실행할 것이다. 즉, 디스크에서 데이터를 가져와야 하는 건 결국 우리의 몫이다.
: MBR에서 4개의 파티션을 설정할 수 있게, 64바이트를 제공해준다. 이걸 사용할 것이다.
: 위의 3가지(텍스트 출력, 디스크 읽기, 파티션 설정)를 하면 어느 정도 512B에 간당간당할 것이다. 그래서 FBL에서는 VGA를 통해 문자열을 출력하지 않고, BIOS INT를 통해 출력할 것이다. 그리고 함수도 없을것이다. 함수의 사용은 재사용을 위해서인데, FBL에 함수를 작성하는 것은 여유가 부족하다는 판단이 든다. 문자열 출력, 디스크 읽기 등 모두 심볼 단위로 구현한다. 함수의 구현 및 보호 모드로 가기 위한 A20, GDT, IDT는 VBR에서 진행할 것이다.
: 참고로, x86은 리얼 모드부터 시작해서 보호 모드를 거쳐 64비트 모드 까지 가는 과정 자체가 굉장히 힘들다. ARM은 그냥 부팅하면서 64비트로 동작을 하는데, x86은 호환성을 지키겠다고 리얼 모드부터 시작을 한다. 결국 매번 모드가 바뀔 때 마다, 메모리 맵이 바껴야 한다는 것이다. 그래서 각 모드에 따라 커널이 메모리 로딩되는 위치도 제 각각이다. 커널 이미지를 로딩하는 방법은 이 글을 참고하자.
- 세그 먼트 주소 지정
: x86은 다른 CPU 아키텍처에서는 보기 힘든 메모리 관리 구조를 사용한다. 바로 `세그먼테이션`이다. 많은 CPU 아키텍처들은 선형 주소방식으로 메모리를 관리하지만, x86 리얼 모드 때부터 사용된 이 방식은 현재는 거의 리얼 모드에서만 사용되는 듯 하다. 물론, x86 아키텍처는 GDT를 사용하기 때문에 세그멘테이션 관리 방식을 무조건 사용할 수 밖에 없다. 그러나, 실제 디테일한 메모리 관리는 페이징으로 넘어갔다. 세그먼테이션 주소는 마치 공식이 존재한다.
세그먼테이션 주소 = (세그먼테이션 베이스 주소 << 4) + 오프셋
: 위의 공식은 아래와 같이 여러 가지로 문장으로 대체되기도 한다.
1" 세그먼테이션 주소 = (세그먼테이션 베이스 주소 * 0x10) + 오프셋
2" 세그먼테이션 주소 = (세그먼테이션 베이스 주소 * 16) + 오프셋: 위의 3개 식 모두 같은 뜻이다. 결국 베이스 주소를 왼쪽으로 4비트 쉬프트 시켜서 1MB 이상의 주소에 접근하겠다는 뜻이다.
- 두 번째 부트로더 메모리 위치
: 리얼 모드에서는 메모리 어디 위치에 커널을 로드 해야 할까? 일단 리얼 모드에서 BIOS가 사용하는 메모리 맵을 확인해야 한다. BIOS가 사용하는 메모리 위치는 피해서 로드해야 하기 때문이다. 그럼 왜 하필이면 BIOS의 메모리 맵을 확인할까? 리얼 모드에서는 BIOS가 전부이기 때문이다. 디바이스 드라이버의 역할을 BIOS가 전부 담당한다.
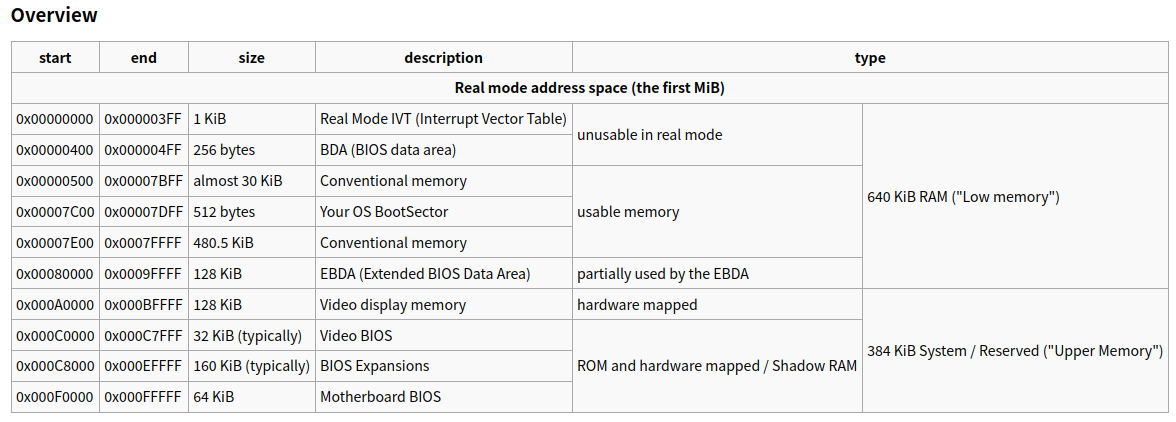
출처 - https://wiki.osdev.org/Memory_Map_(x86) : 위에서 이미 한 번 봤던 내용일 것이다. 커널을 로드하는 위치는 사용 가능한 메모리인 0x500 ~ 0x7FFFF 사이에 위치하면 될 듯 하다. 그런데 사용 가능한 영역도 3개로 나눠어져 있다. 여기서 가장 큰 영역은 `0x7E00 ~ 0x7FFFF`이다. 커스텀 부트로더의 마지막 주소 바로 다음인 0x7E00에 16비트 커널을 로드하는 것이 좋아보인다. 저곳에 하는 이유는 잠시나마 있을 리얼 모드이지만, 메모리를 최대한 사용할 수 있는 위치이고, 0x7E00이 2바이트 정렬 주소이기도 하기 때문이다.
: 커널을 0x7E00으로 위치시키면서 스택의 베이스 포인터를 0x7E00으로 위치를 바꾸려고 했지만, 스택의 위치를 바꾸는 설정은 메인 함수로 진입전에만 할 수 있기 때문에 쉽지 않아보인다. 왜냐면, 스택 위치를 바꾸려면 스택이 사용중이지 않아야 한다. 그런데 메인 함수가 호출됬다는 것은 이미 스택이 사용중이라는 뜻이 된다. 즉, C 언어를 사용한다는 것은 이미 함수를 실행한다는 뜻이고 함수를 실행한다는 것은 스택을 사용하겠다는 뜻이 된다. 그러므로, 스택의 위치를 커널에서 수정하는 것은 쉽지 않아보인다.
- C 언어 부트로더
: 최초의 프로그램은 C언어가 될 수 없다. 그 이유는 2가지가 있다. 첫 째로, C언어 프로그램은 함수 기반의 언어다. 함수의 기반의 언어란 결국 스택의 기반의 언어와 동의어다. 즉, 메모리에 스택이 영역이 설정되고 SP, BP 포인터가 설정이 되어야 한다. 그런데, C언어로 만들어진 프로그램이 최초로 실행이 된다는건 main() 함수가 프로그램 실행과 함께 최초로 실행된다는 것을 의미한다. 그런데, 스택이 설정이 안되어 있다. 이러면, SP가 어디를 가리키는 지도 알 수 없는 상황에서 스택을 맘대로 컨트롤하는 꼴이 된다. 이래서 C언어 기반의 프로그램이 최초의 프로그램이 될 수 없다.
: 그리고 두 번째로, C언어는 아키텍처의 독립적인 언어다. 하이 레벨 랭기지가 만들어진 배경은 로우 레벨 랭기지 때문이다. 즉, 어셈블리언어처럼 CPU 아키텍처에 의존적인 언어들 때문에 만들어진 것이다. 그런데, 로우 레벨 랭기지는 각 아키텍처에서 지원해주는 각 기능들을 사용할 수 있다. 그러나 C언어로는 그게 불가능하다. 즉, C언어는 인텔의 레지스터나 ARM의 레지스터에 직접 접근할 수 있는 방법이 없다. 그러나 각 CPU 제조사의 어셈블언어는 이게 가능하다. 두 번째 이유를 정리하면, C언어가 최초의 실행 언어가 될 수 없는 건 하이 레벨 언어이기 때문이다.
- C 메인 함수 호출
: 부트 로더에서 할 일을 다하고 C언어 메인 함수를 호출하려면 어떻게 해야 할까? 일단 어셈블리언어로 작성된 파일과 C언어로 작성된 파일을 확장자가 다르다. 어셈블언어는 어셈블러를 통해 어셈블되고, C언어는 컴파일러를 통해 컴파일된다. 그런데, 컴파일은 결국 C언어를 어셈블리언어로 변환하는 과정이다. 그래서 결국 C언어 파일이든 어셈블리언어 파일이든 오브젝트 파일 형태로 빌드가 된다.
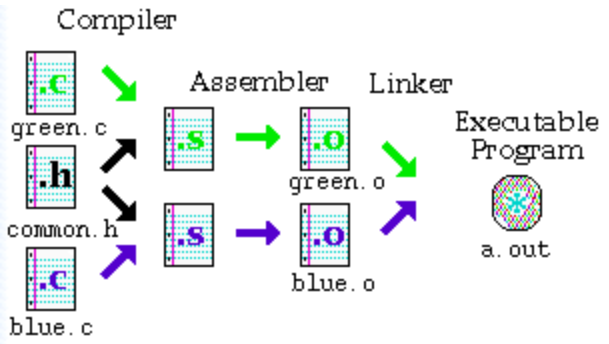
출처 - https://www.dartmouth.edu/~rc/classes/softdev_linux/complex_compile.html : 예를 들어, boot.S와 main.c가 boot.o와 main.o로 빌드되는 것이다. 이제 저 2개의 실행 파일을 합쳐야 된다. 저기서 2개의 파일이 합쳐지지 않으면 부트 로더(boot.o)에서 C 메인 함수를(main.o) 호출할 수 없다. 왜? 실제 변수나 함수는 `심볼`이라는 개념에서 시작됬다. 이 심볼은 각각의 주소를 갖게된다. 위에 각각의 2개의 파일에 test 라는 변수가 선언됬다고 치자. 빌드시에는 이게 문제가 없다. 왜? 각각의 파일은 서로 독립적인 파일이기 때문이다. 그러나, 링킹이라는 과정을 거쳐 서로 합쳐저 하나의 파일이 될 때는 문제가 생긴다. 왜? 2개의 파일에 있는 test 라는 변수가 동일한 이름을 쓰기 때문이다. 즉, 이 말을 다르게 해석하면, 이제 각각의 파일이 서로 독립적인 것이 아니라, 서로를 참조할 수 있는 관계가 됬다는 소리다. 이게 링킹의 과정이다.
: 부트 로더에서 C 함수를 호출하는 방법은 이 글을 참고하자.
- 16비트 부트 로더 디버그
: 16비트 부트 로더는 일반적인 방법으로 GDB를 통한 디버깅은 불가능하다. GDB는 ELF 포맷을 가진 실행 파일을 디버깅을 할 수 있다. 대개 16비트 부트 로더는 ELF 포맷으로 만들어지지 않는다. 단순 플랫 바이너리 포맷인 BIN 파일로 만들어진다. 즉, 파일을 디버깅 할 수 있는 심볼 및 메타 정보들이 모두 삭제된 상태이다. 그런데, 역시나 방법은 존재한다. 그 과정을 알아보자.
: 일단 디버깅에 필요한 심볼 및 메타 데이터를 생성하기 위해 ELF 포맷으로 파일을 빌드해야 한다.
nasm -f elf32 -g3 -F dwarf pbl.asm -o pbl.o: `-f` 옵션을 통해 파일 포맷을 설정하고, `-g` 옵션을 통해 디버깅 정보도 넣어준다. 저 ELF 파일은 GDB에게 디버깅 정보를 전달해주는 용도로만 사용할 것이다. 왜냐면, 우리에게 실제로 필요한 파일은 디버깅 정보가 들어가 있지 않은, 512B 16비트 부트 로더다. 그래서 저 파일에서 데이터와 코드 영역을 추출 할 것이다. 실행시에 그냥 저 ELF 파일을 쓰면 안되나? 큰일난다. ELF 파일은 기본 크기 2K는 기본이다. MBR의 부트 섹터는 512B 밖에 안되기 때문에, ELF는 사용할 수 없다.
objcopy -O binary pbl.elf pbl.bin: 위의 명령어를 통해서 pbl.elf 파일에서 데이터와 코드영역만 분리할 수 있다. 그런데, 사실 위의 nasm 에서 문제가 있을 것이다. ELF 포맷은 `ORG 지시어`를 지원하지 않는다. 즉, 명시적인 메모리 주소 지정을 허용하지 않는다. 만약, 작성한 부트 로더의 맨 위에 `ORG 0x7C00`이 작성되어 있다면, 이것과 동일한 기능을 구현해주는 다른 방법을 강구해야 한다. 그 방법은 바로 링커를 이용하는 것이다. 우리는 링커를 통해서 저 파일을 0x7C00부터 시작하도록 할 것이다.
ld -Ttext=0x7c00 -melf_i386 pbl.o -o pbl.elf: 링커스크립트를 굳이 작성하지 않아도, 커맨드 라인에 명시적으로 `-T` 옵션을 지정해서 텍스트의 영역의 시작 주소를 전달할 수 있다. 플랫 바이너리를 디버깅하는 과정에서 굳이 링커 스크립트를 작성할 필요가 없으니 이 방법을 사용하자. 그리고 포맷은
: 최종적으로 합치면 아래와 같은 형태가 된다. 아래의 명령어에서 링크시에 엔트리 포인트가 없다고 경고 문구가 나올 수 있는데, 무시해도 된다.
nasm -f elf32 -g3 -F dwarf pbl.asm -o pbl.o ld -Ttext=0x7c00 -melf_i386 pbl.o -o pbl.elf objcopy -O binary pbl.elf pbl.bin: 그리고 실행 방법은 다음과 같다. i386 버전의 QEMU의 실행을 주의하자. 64비트가 아니다.
qemu-system-i386 [-hda|-fda] pbl.bin -S -s: 대개 위와 같은 형태로 실행을 한다. 뒤에, `-S -s` 옵션은 쌍으로 붙어 다니는 QEMU 디버깅 옵션이다. GDB와 함께 사용할 때, 필수적으로 쓰인다.
: GDB를 실행할 때는 다음의 옵션들이 필요하다. 아래의 `gdb-multiarch`는 gdb에서 더 많은 아키텍처들을 지원해주는 GDB이다. 우리와 같은 임베디드 개발자들에게 필수다.
gdb-multiarch pbl.elf \ -ex 'target remote localhost:1234' \ -ex 'set architecture i8086' \ -ex 'break *0X7C00' \ -ex 'continue': gdb-multiarch를 쓰는 이유는 일반 gdb가 16비트 처리를 하지 못하기 때문이다. 일반 gdb는 리얼 모드에서 사용하느 세그먼트 주소 지정 방식을 알지 못하기 때문에, `x/10i $pc`와 같은 명령어를 통해 다음 PC 포인터가 실행할 명령어들을 확인해보면, 중간중간 건너뛰는 현상을 보게된다. 그러나, gdb-multiarch는 제대로 인식한다.
: `target remote localhost:1234`로 QEMU의 머신과 연결한다. 중요한 부분이 `set architecture i8086` 부분이다. 16비트 아키텍처로 설정을 해야한다. 왜냐면, GDB가 16비트 작성된 코드를 32비트로 실행해서 `n` 키를 누르면, 2칸씩 이동할 수 있기 때문이다. GDB는 기본적으로 architecture의 값이 `auto`이다. `break *0x7C00`을 통해서, 우리의 부트 로더가 로드되는 위치에 브레이크 포인트를 건다. 그리고 실행한다.
- 섹션 위치
: 어셈블리어로 부트 로더를 제작할 때, 섹션의 배치는 굉장히 중요하다. `SECTION .text` 하나만 선언하고 모든 코드를 넣어도 상관은 없다. 데이터 선언도 텍스트 섹션에 들어가는 것이다. 그런데, 이렇게 텍스트 섹션 하나만 사용할 거면, 데이터는 전부 맨 뒤에 배치해야 한다. 왜냐면, CPU는 텍스트 섹션에 존재하는 명려어들을 모두 실행 명령어로 처리하기 때문이다. 예를 들어, `SECTION .text`을 소스의 최상위에 선언하고 중간중간에 데이터를 선언하는 코드를 넣어보자. 데이터를 정의하는 코드는 대개 데이터 섹션으로 들어가야 하는데, 이걸 텍스트 섹션으로 인식해서 이상한 주소로 점프하게 되는 걸 볼 수 있을거다. 데이터를 선언하는 기계 코드값과 코드를 실행하는 기계 코드값과 아예 다르다. 예를 들어, A 파일라는 인텔 명령어로 작성된 A라는 파일이 있다. 이 파일에는 텍스트 섹션만 존재한다고 치자. 인텔 명령어들은 인텔만의 기계어 코드값(Opcode)이 있다. 그런데, 데이터, 즉, 변수들은 인텔 기계어 코드값이 없다. 여기서 인텔 크로스 컴파일로 A 파일을 빌드하면, 인텔 기계 코드값으로 컨버팅된 바이너리 파일이 나온다. 이 바이너리 포맷이 ELF 라고 해보자. 이게 링킹되는 시점에 이 바이너리 파일은 전부 텍스트 섹션에 배치된다. 여기가 문제다. A 라는 파일에는 변수를 선언하는 코드도 있는데, 그것마저 링커는 텍스트 섹션에 배치하는 것이다. 그렇면, 인텔 CPU는 변수를 선언하는 부분까지 인텔 기계 명령어로 인식해서 잘못된 명령어를 실행하게 된다. 그래서, 실제 변수가 선언되는 코드는 데이터 섹션에 배치해야 한다.
- 1MB 로딩
: 1MB에 로딩하기 위해서는 16비트 부트 로더는 한계가 있다. 왜냐면, 세그먼트 주소지정 방식은 최대 1MB 까지만 지원되기 때문이다(FFFF:FFFF). A20 라인이 활성화해도 16비트는 답이없다. 최대, `0xFFFF + 0xFFFF` 까지만 접근이 가능하기 때문이다. 그래서, GRUB은 `리얼 모드`와 `보호 모드`를 왔다리갔다리 하면서 로딩한다. 언리얼 모드를 고려해 볼 수 있지만, BIOS를 사용하는 순간 데이터 세그먼트 다시 초기화되버려서 #GP가 발생한다. 최신 PC라면 BIOS의 확장 기능을 통해서 가능할 거 같긴한데, Yohda OS는 예전 모델들에 대한 호환성을 지킬 것이기 때문에 GRUB과 같은 방법으로 커널을 로딩하려고 한다.
- 커널 로딩
: 부트 로더가 커널을 로딩하기 위해서는 기본적으로 2가지를 알고 있어야 한다.
0" 커널 사이즈
1" 메모리에 로딩될 물리 주소 시작 번지: 이 2가지가 가장 기본이다. 그렇면, 어떻게 부트 로더는 커널의 위 정보들을 언제, 어떻게 알 수 있을까? 대개, 부트 로더와 커널은 별도로 빌드될 수 도 있지만, 같이 빌드될 수 있다. 컴파일 시점에 커널을 먼저 빌드한 뒤에, 사이즈를 측정해서 부트 로더 빌드 시에 파라미터로 넘겨주는 것은 어떨까? 예를 들어, 부트 로더를 빌드할 때, 아래와 같이 매크로값으로 커널 사이즈를 던져주는 것이다.
nasm -f elf -g3 -F dwarf -DKERN32_SECS=${KERN32_SECS}
: 그런데, 이렇게 빌드 커맨드를 통해 부트 로더에게 직접 커널 사이즈를 제공하면, 커널보다 먼저 빌드될 수 가 없다. 왜냐면, 부트 로더가 커널 사이즈를 모르기 때문에, 먼저 빌드할 수 없기 때문이다. 그렇면, 어떻게 해야 할까? 앞에 구조의 문제는 커널 사이즈를 빌드 시에 값을 정적으로 할당하기 때문에 문제가 발생한다. 이건 마치, Makefile에서 특정 변수에 `:=` 연산자를 통해 값을 할당한 것과 같다. 이 문제를 해결하려면, 아무때 나 값이 할당될 수 있게 해야한다. 즉, 값을 참조하는게 아니라, 주소를 참조하도록 해야한다. Makefile에서 `?=` 연산자와 같이 말이다. 주소를 전달할 경우, 부트 로더가 커널 보다 먼저 빌드되도 상관이없다.
nasm -f elf -g3 -F dwarf -DKERN32_SIZE_SEC=${KERN32_SIZE_SEC}
: 예를 들어, 커널과 부트 로더는 100번째 섹터의 오프셋 0 바이트, 사이즈 4바이트로 저장한다고 치자. 그리고 이제 부트 로더가 먼저 빌드된다고 하자. 그렇면, 부트 로더 빌드시에 `KERN32_SIZE_SEC`에 `100`을 전달하면 된다. 이 값은 하드코딩값이다. 즉, 커널이나 부트 로더가 빌드되어야 생성되는 값이 아니다. 그러므로, 의존성이 사라진다. 그런데, 커널 사이즈말고 커널 주소도 보내야 한다. 커널 주소는 전달되는 섹터의 오프셋 4바이트, 사이즈 4바이트라고 하자.
nasm -f elf -g3 -F dwarf -DKERN32_META_SEC=${KERN32_META_SEC}
: 근데 파라미터가 매크로 변수 이름으로 줄 경우, 변수 이름이 바뀌면 코드가 전부 바뀌는 문제가 있다. 가장 좋은 방법은 스펙을 정의하는 것과 같이 100 번째 섹터가 메타 데이터를 가지고 있다고 서로 약속하고, 처음 4바이트는 커널 사이즈, 그 다음은 4바이트 커널 로딩 위치로 문서를 만드는 것이다. 그러면, 커널은 헤더를 만들 때, 부트 로더는 커널 헤더를 파싱할 때, 문서를 참고하면 된다. 그렇면, 위의 파라미터 또한 사라진다.
nasm -f elf -g3 -F dwarf
: 근데, 이 프로젝트가 유명해져서 다른 플랫폼들과 호환성을 지키려고 하다보니 주소 100 번째 섹터를 다른 디바이스가 사용하는 것을 알게됬다. 이 문제가 발생하게되면서 메모리의 특정 위치에 정보를 저장하는 것이 힘들다는 것을 알게됬다. 이제 어떻게 해야 할까? 우리가 필요한 건 커널의 메타 정보다. 이 정보를 커널과 관련없는 이상한데다 저장하지 말고, 커널에 저장하는 것은 어떨까? 즉, 커널 앞쪽에 64바이트에 이 정보를 저장하는건 어떨까? 왜 앞인가? 뒤는 안되나? 빌드 타임에 부트 로더 이미지 시작 섹터와 커널 이미지위 시작 섹터는 대게 미리 알고 있게 된다. 그런데, 끝 주소를 알려면, 사이즈까지 알아야 한다. 그러므로, 간단하게 구현하려면 메타 정보는 앞쪽에 저장하는 것이 좋다. 여기까지 실행 파일에서 `헤더`가 필요한 이유에 대해 설명했다.
'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
[운영체제 만들기] FAT (0) 2023.08.05 GDT (1) 2023.08.05 [빌드] Makefile (0) 2023.08.03 [xv6] entry (0) 2023.08.01 [xv6] mkfs (0) 2023.07.30