-
[리눅스 커널] CPU topologyLinux/kernel 2023. 8. 3. 02:32
글의 참고
- https://www.kernel.org/doc/Documentation/devicetree/bindings/cpu/cpu-topology.txt
- http://www.wowotech.net/pm_subsystem/cpu_topology.html
- https://www.kernel.org/doc/html/next/admin-guide/cputopology.html
- https://docs.openstack.org/nova/latest/admin/cpu-topologies.html
- https://www.kernel.org/doc/Documentation/x86/topology.txt
- https://www.kernel.org/doc/Documentation/devicetree/bindings/arm/topology.txt
- https://www.kernel.org/doc/Documentation/cputopology.txt
- https://www.cnblogs.com/lingjiajun/p/15268122.html
- https://www.kernel.org/doc/ols/2004/ols2004v1-pages-89-102.pdf
- http://www.qdpma.com/ServerSystems/EndOfMultiProcessors.html
- https://www.kernel.org/doc/html/v4.18/vm/numa.html
- https://lazure2.wordpress.com/tag/big-little-cpu-migration/
- https://en.wikipedia.org/wiki/ARM_big.LITTLE
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
글의 내용
- CPU topology
: `cpu topology`는 SMP 환경에서 물리적으로 여러 개의 CPU 들이 어떠한 `layout`을 이루고 있는지를 나타낸다. 소프트웨어 입장에서 `CPU 토폴로지`는 스케줄러에게 굉장히 중요한 역할을 한다. 스케줄러는 `CPU 토폴로지`를 통해서 태스크를 어떤 CPU에게 할당해야 하는지에 대한 정보를 얻게 된다(`로드 밸런스`).
: 코드를 분석하기 전에 간단히 서비스 레벨에서 명령어를 통해 자신의 CPU 토폴로지를 확인할 수 있다. 파란색으로 표시된 부분을 주목하자.
xxx@cs ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Stepping: 4
CPU MHz: 2100.118
BogoMIPS: 4199.92
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23: 현재 위의 정보로 파악한 가능한 `CPU 토폴로지` 정보는 아래와 같다.
CPU 개수 : 24개
소켓 개수 : 2개
소켓 당 CPU 개수 : 6개
코어 당 스레드 개수 : 2개
누마 노드 개수 : 2개- SMP, SMT and NUMA
: `SMP`란 `Symmetric multi-processing`의 약자로 한 칩에 여러 개의 CPU 코어가 장착되어 있는 것을 의미한다. `SMT`는 `Simultaneous multi-threading`의 약자로, 한 개의 CPU 코어가 여러 개의 스레드를 지원하는 것을 의미한다. 지금 앞에 말한 용어들은 모두 하드웨어 측면에서 살펴본 용어들이다.
: 그런데, 운영 체제, 즉, 소프트웨어 측면에서 `SMP` 이건 `SMP`건 관계없이 CPU 코어들은 단지 `execution process` 기능을 수행하는 요소로만 보일 뿐이다.
: 옛날 싱글 코어가 지배하던 시대에는 CPU의 성능을 높이는 유일한 방법은 `주파수` 즉, `CPU 클락`을 증가시키는 방법밖에 없다고 생각했다. 그러나, 주파수를 증가할수록 발열량도 그에 비례해서 증가했기 때문에 계속 주파수를 높이는 것은 물리적으로 한계각 명확했다. 그래서, 발상의 전환을 하게 된다. 즉, 싱글 코어가 아닌 멀티 코어를 통해 성능을 높일 생각을 하게 된 것이다.
: 싱글 코어에서, 한 개의 CPU 코어에게 4GHz를 할당하면 발열량이 어마무시했다. 그런데 멀티 코어 프로세서의 경우에는, CPU 코어 수가 증가했기 때문에, 각 CPU 코어에 1.5GHz만 할당하면 비슷한 퍼포먼스를 내면서 발열량 문제를 해결할 수 있게 되었다. 거기다가, `멀티 태스킹`의 시대가 도래하면서 사용자들은 컴퓨터 및 스마트폰에서 동시에 다양한 작업을 `빠르게` 하기를 원했다. 멀티 프로세서는 이러한 요건에 맞게 등장한 `CPU 토폴리지`다.
: 일반적으로 `멀티 프로세서` 라고 하면, 한 칩에 동일한 여러 개의 CPU 코어들로 구성되어 있다. 코어들은 시스템 자원인 `버스`, `메모리` 등을 공유하게 된다. 이러한 구조를 `Symmetric Multi-processor` 라고 한다. SMP의 구조를 이해하려면, `Asymmetric Multi-processor(AMP)` 구조와의 차이를 통해 이해하는 것이 가장좋다. 기본적으로, SMP는 각 CPU 코어가 시스템에 존재하는 한 개의 메모리를 여러 CPU 코어가 공유한다. 그러나, `AMP` 구조는 각 CPU 코어가 자신만의 별도의 메모리를 갖는다. 그리고, `Master Processor`에서만 운영 체제가 동작하기 때문에 시스템 리소스를 사용하는 권한이 높은 동작들은 모두 `Master Processor`에서 처리된다. 유저 애플리케이션들이 주로 `Slave Processor`에서 처리된다.

https://www.electricalvolt.com/2023/04/difference-between-symmetric-and-asymmetric-multiprocessing/
https://www.electricalvolt.com/2023/04/difference-between-symmetric-and-asymmetric-multiprocessing/: `AMP` 구조에서는 동기화 메커니즘이 딱히 필요가 없다. 왜냐면, 모든 하드웨어 액세스 처리를 `Master Processor`에서 진행하기 때문이다. `SMP`는 `AMP`에 대한 특징을 반대로 생각하면 된다. 리소스를 별도로 가지고 있지 않으며, 모든 프로세서에서 운영 체자가 동작이 가능하다.
: 칩 제조업체는 여러 개의 코어를 하나의 칩에 패키징하는데 이를 `소켓`이라고 한다. `소켓` 이라는 용어는 주로 `x86` 아키텍처에서 많이된다. 소켓 하나에 2개의 코어를 접착시킬 수 있다고 가정하면, 메인보드에 2개의 소켓이 존재하면 4코어 시스템, 4개의 소켓이 존재하면, 8코어 시스템이 된다. `ARM` 진영에서 소켓이라는 용어보다 `Cluster`라는 용어를 사용한다.
: 대부분의 운영 체제(예: Windows, Linux)에는 프로세스 및 스레드 개념이 존재한다. 프로세스는 프로세스는 스레드가 실행될 환경 및 공간을 제공해주는 컨테이너와 같다. 실제 실행 주체인 스레드다. 스레드는 스케줄링의 최소 단위다. 일반적으로는 CPU 코어 하나 당 개별적인 하드웨어 레지스터 세트를 한 개만 갖고 있다. 그러나, 일부 프로세서(Core)에는 한 개의 CPU 코어에 여러 개의 하드웨어 컨텍스트(상태 레지스터, 범용 목적 레지스터, FPU 레지스터 등등)가 존재하는 경우가 있다. 이럴 경우, 한 코어에서 `동시성`이 아닌 `병렬성`으로 여러 쓰레드를 동시에 실행할 수 있으며 이를 `SMT(Simultanous Multi-Thread)`라고 한다.
: 아래 그림은 위에서 설명한 `Core`, `Socket(Cluster)`, `Thread`의 개념을 하드웨어 관점으로 보여주고 있다.
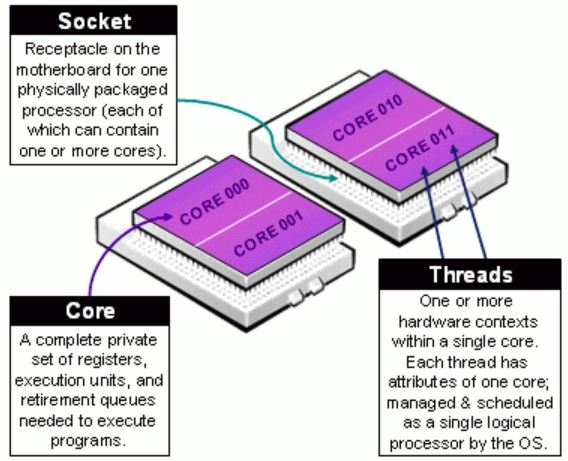
출처 - http://www-x-wowotech-x-net.img.abc188.com/content/uploadfile/201505/8b44b18608d5f29ebb7b151da6cebde420150530135848.gif
http://www.wowotech.net/pm_subsystem/cpu_topology.html
https://michael2012z.medium.com/virtual-cpu-topology-20b67633ca19: 앞에서 자세히 언급하지는 않았지만, `SMP` 구조에서 심각한 문제가 하나있다. 바로, `동기화` 문제다. 왜냐면, 버스 및 메모리와 같은 시스템 공유 리소스를 여러 CPU 코어들이 공유하기 때문이다. `SMP`에서도 코어 수가 적을 때는 크게 문제가 되지 않는다. 그러나, 코어 수가 증가함에 따라 시스템 공유 자원인 버스와 메모리에서 매우 큰 병목 현상이 발생하는 문제가 발생했다. 이러한, 해결책으로 등장한 개념이 바로 `NUMA(Non-Uniform Memory Access)` 아키텍처다.
: NUMA에서는 `노드`라는 개념이 등장한다. 아래 그림에서 볼 수 있다시피 노드는 하나의 `하드웨어 리소스들을 모아놓은 공간`이다. 예를 들어, 노드에는 여러 개의 CPU 코어, 각 노드안에서만 사용할 전용 로컬 메모리, 각 노드안에서만 사용할 전용 I/O 버스등이 포함된다. 즉, 누마 아키텍처에서는 노드하나만 있어도 OS 같은 프로그램을 동작시킬 수가 있다.
: NUMA는 메모리 계층을 나눔으로써 병목 현상을 완화시킨다. 즉, 하나의 노드안에 여러 CPU 코어들은 1차적으로 자신이 속해있는 노드안에 있는 로컬 메모리를 이용해서 작업을 진행한다. 그리고, 다른 노드의 메모리에 접근할 일이 생길 때만 각 노드를 연결해주는 `inter-nodes connection`을 이용한다. 이로써, 일반적인 UMA기반의 SMP 보다 더 좋은 퍼포먼스를 낼 수가 있다. 그러나, 동전의 양면성처럼, 소프트웨어적으로 복잡한 프로세스 스케줄링 및 동시성 문제가 따라오게 된다.

https://unix.stackexchange.com/questions/92302/enabling-numa-for-intel-core-i7
https://www.researchgate.net/figure/Shared-memory-NUMA-system_fig1_280155788- ARM HMP (Heterogeneous Multi-Processing)
: 앞서 언급한 `CPU 토폴로지` 구조들은 대부분 x86 아키텍처를 기준(PC 및 Server)으로 설명했다. 즉, 주요 관심사가 CPU 퍼포먼스를 향상시키는 것이다. 전력 소비 따위는 안중에도 없는 것이다. 당연하다. x86 기반의 제품들은 모두 `Wall adapter`를 기반으로 하기 때문에 소비 전력 문제를 걱정할 필요가 없었다. 그러나, `ARM` 같은 프로세서는 `Portable device`를 대상으로 한다. 즉, 벽걸이 충전기가 아닌, 배터리를 통해서 전력 공급을 받게 된다. 그래서 `ARM` 프로세서의 주요 관심사는 성능 보다는 소비 전력이다.
: 그런데, 스마트폰이 대중화되면서 프로세서에서 시간 당 처리해야 할 작업량이 훨씬 더 많이 필요했다. 왜냐면, 사용자들이 그것을 원했기 때문이다. 대부분의 사람들은 고정적인 위치에서만 작업해야 하는 PC를 떠나 움직이면서 작업할 수 있는 스마트폰을 통해 대부분의 업무를 처리하고 싶어했다. 그와 동시에 사람들은 더욱 더 스마트폰이 빨라지기를 원했다. 그래서 스마트폰 칩 제조업체들이 처음에는 `배터리` 자체에 포커싱했다. 그러나, 배터리의 발전 속도는 스마트폰의 발전 속도를 따라올 수 가 없었다. 그래서, 다시 스마트폰 칩 제조업체들은 사람들의 기대에 부응하기 위해 성능과 전력을 모두 잡을 수 있는 구조들을 내놓기 시작한다. 그중에서 ARM 에서 내놓은 `HMP` 기술에 대해 알아보자.
: Heterogeneous 라는 뜻은 `이기종` 이라는 뜻으로, `SoC`안에 다수의 코어들이 서로 다른 종류의 코어들로 구성되어 있다는 것을 의미한다. HMP는 2가지 경험적 토대를 기반으로 하는 `CPU 토폴리지`다.
1. 동일한 양의 일을 처리를 받더라도, 성능이 높은 프로세서 일수록, 더 높은 전력 소비를 야기한다. 반대로, 성능이 낮은 프로세서 일수록, 더 낮은 전력 소비를 야기한다.
2. 스마트폰과 같은 디바이스들에서는 높은 성능을 요구하는 작업들, 예를 들어, 고해상도 비디오 처리 작업들이 매우 드물다. 즉, 스마트폰에서 높은 성능을 요구하는 작업들이 거의 없다.: 이에 따라 ARM에서 `HMP 아키텍처`라는 것을 제안하였는데, 이 아키텍처는 하나의 chip에서 고성능 코어(Cortex-A15, big core라고도 함)와 저성능 코어(Cortex-A7, little이라고도 함), 이렇게 두 종류의 ARM 코어를 함께 패키징했다. 그래서 HMP를 big-little 아키텍처라고도 한다. `big`과 `little` 차이는 다음과 같다.
1. big core - 처리 성능은 높지만, 전력 소비량이 상대적으로 높다.
2. little core : 처리 성능은 낮지만, 전력 소비량이 상대적으로 낮다.: 따라서, `ARM` 칩을 사용하는 소프트웨어(예: OS 스케줄러)는 성능과 전력 소비의 균형을 맞추기 위해 필요에 따라 작업을 big-cire 또는 little-core에 할당할 수 가 있게 되었다. ARM big.little 아키텍처는 기본적으로 하드웨어 아키텍처다. 즉, 소프트웨어에서 이 구조를 어떻게 사용할지는 각 제조사마다 다를 수 있다. HMP를 소프트웨어로 구현할 때, 정말 여러 가지 구현 방법들이 있다. 그중에서 2가지만 알아보자(참고로, ARM은 여러 CPU 코어를 묶어서 하나의 `cluster`를 이룬다).

https://lazure2.files.wordpress.com/2013/04/image21.png
https://lazure2.files.wordpress.com/2013/04/image20.png: 첫 번째는 낮은 로드가 오면 LITTLE 클러스트를 전체를 사용하고, 높은 로드가 들어오면 BIG 클러스터 전체를 사용하는 방식이다. 두 번째는 낮은 로드에서는 LITTLE 클러스트만 사용하고, 높은 로드에서 BIG에서 한 개와 LITTLE에서 3개를 섞어서 사용하는 구조다.
- Linux kernel CPU topology driver
: 앞에서 CPU topology의 물리적 기반을 공부했으니, Linux kernel의 CPU topology driver를 보면 훨씬 간단할 것이다. 소프트웨어 계층은 다음과 같습니다.
--------------------------------------------- -------------------------------------------- | CPU topology driver | | Task Scheduler etc. | --------------------------------------------- ------------------------------------------- ---------------------------------------------------------------------------------------------- | Kernel general CPU topology | ---------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------- | arch-dependent CPU topology | ----------------------------------------------------------------------------------------------: 운영체제의 기본은 `인터페이스 추상화` 다. 그래서 리눅스 커널은 `Kernel general CPU topology`를 이용해서 모든 CPU 제조사의 독립적인 기능들을 통일화된 인터페이스로 추상화 해주는 역할을 한다. `Kernel general CPU topology` 인터페이스는`include/linux/topology.h`에 위치하고 있다. `arch-dependent CPU topology`는 CPU 제조사의 아키텍처 의존적인 코드들이 존재하게 된다. 일반적인 구조는 `arch-dependent CPU topoloty`가 `Kernel general CPU topology`에서 제공하는 표준 인터페이스를 구현하는 식으로 개발을 진행한다.
: 리눅스 커널의 `CPU topology driver`는 2가지 중요한 기능을 제공한다.
1) 시스템에 존재하는 모든 CPU 코어 정보들을 유저 스페이스에서 확인할 수 있도록 루트 파일 시스템에 export 한다(i.e `lscpu`)
2) 효율적인 프로세스 스케줄링을 위해 CPU 코어 정보를 스케줄러에 제공한다.: 이제 진짜 본격적으로 리눅스 커널의 `CPU topology` 소스를 분석할 것이다. 크게 3가지를 분석한다.
1. Kernel general CPU topology
2. Arch-dependent CPU topology
3. CPU topology driver: 위에서 `arch-dependent CPU topology`는 `ARM64` 아키텍처를 분석할 것이다.
- Kernal general CPU topology
: `Kernel general CPU topology`는 주로 "#ifndef...#define" 형식의 매크로를 통해 API를 제공한다. 이렇게 하는 이유는 `arch-dependent CPU topology`가 이러한 매크로를 재정의할 수 있도록 하기 위해서다. 예를 들어, `arch-dependent CPU topology` 에서 `topology_core_cpumask` 함수를 정의했으면, 리눅스 커널에서 디폴트로 정의한 `#define topology_core_cpumask(cpu) cpumask_of(cpu)` 코드는 사용되지 않는다. 그렇지 않으면, `Kernel general CPU topology`에서 정의한 default API를 사용한다.
: 대개 리눅스 커널은 아래와 같은 구조를 특히나 아키텍처 종속적인 코드가 있는 부분에서 자주 사용한다. 왜냐면, 컴파일 에러를 없애기 위해서다. 만약, 커널이 아래 매크로들을 정의하지 않았다고 정의하자. 그런데, 아키텍처 제조사에서도 정의하지 않았을 경우, `topology_core_cpumask`가 임의의 디바이스 드라이버 코드에서 사용중이라면, 컴파일 에러가 발생하게 된다.
// include/linux/topology.h - v6.5 .... #ifndef topology_physical_package_id #define topology_physical_package_id(cpu) ((void)(cpu), -1) #endif #ifndef topology_die_id #define topology_die_id(cpu) ((void)(cpu), -1) #endif #ifndef topology_cluster_id #define topology_cluster_id(cpu) ((void)(cpu), -1) #endif #ifndef topology_core_id #define topology_core_id(cpu) ((void)(cpu), 0) #endif #ifndef topology_book_id #define topology_book_id(cpu) ((void)(cpu), -1) #endif #ifndef topology_drawer_id #define topology_drawer_id(cpu) ((void)(cpu), -1) #endif #ifndef topology_ppin #define topology_ppin(cpu) ((void)(cpu), 0ull) #endif #ifndef topology_sibling_cpumask #define topology_sibling_cpumask(cpu) cpumask_of(cpu) #endif #ifndef topology_core_cpumask #define topology_core_cpumask(cpu) cpumask_of(cpu) #endif #ifndef topology_cluster_cpumask #define topology_cluster_cpumask(cpu) cpumask_of(cpu) #endif #ifndef topology_die_cpumask #define topology_die_cpumask(cpu) cpumask_of(cpu) #endif #ifndef topology_book_cpumask #define topology_book_cpumask(cpu) cpumask_of(cpu) #endif #ifndef topology_drawer_cpumask #define topology_drawer_cpumask(cpu) cpumask_of(cpu) #endif #if defined(CONFIG_SCHED_SMT) && !defined(cpu_smt_mask) static inline const struct cpumask *cpu_smt_mask(int cpu) { return topology_sibling_cpumask(cpu); } #endif static inline const struct cpumask *cpu_cpu_mask(int cpu) { return cpumask_of_node(cpu_to_node(cpu)); } ....: 몇 가지 중요한 매크로들만 설명한다. 위의 매크로 함수들은 구현은 제조사마다 구현 방식이 다르기 때문에, 구체적인 구현 방식보다는 어떤 값을 반환하는지에 초점을 두는 것이 더 현명하다. 위의 매크로들에 자세한 설명은 이 글을 참고하자.
1. topology_physical_package_id : 위에서 설명한 `소켓` 및 `클러스터`의 ID를 반환한다.
2. topology_core_id : 코어 ID를 반환한다.
3. topology_sibling_cpumask(구버전 `topology_thread_cpumask`) : 동일 CPU 코어에 속한 모든 스레드를 반환한다.
4. topology_core_cpumask : 동일 CLUSTER에 속한 모든 CPU 코어를 반환한다.
5. cpu_cpu_mask : 인자로 전달된 CPU 코어가 속한 노드의 모든 CPU 코어들을 반환한다. 예를 들어, 노드A에 CPU 코어[2,3,5]이 있을 경우, `cpu_cpu_mask(5)`는 CPU 코어[2,3,5]을 반환한다.
6. cpu_smt_mask : 시스템에서 SMT 기능을 지원해야 사용 가능한 함수로, 인자로 전달받은 CPU 코어에 속해있는 모든 스레드 개수를 반환한다.- arch-dependent CPU topology
: ARM64의 경우 arch-dependent CPU topology는 `arch/arm64/include/asm/topology.h` 및 `arch/arm64/kernel/topology.c`에 있으며 ARM64와 관련된 `CPU 토폴로지` 변수 및 함수가 작성되어 있다. 아래의 기능들을 수행한다. 그러나, 실제로 `arch/arm64/include/asm/topology.h` 에는 어떠한 구조체 및 매크로 선언도 확인할 수 없다. 즉, `arm64`에서 `CPU topology` 관련 아키텍처 독립적인 코드는 확인되지 않는다.
: `arm64`는 커널의 표준 인터페이스를 따르고 있다. 그리고, 커널에서 제공해주는 표준 인터페이스의 디폴트 동작을 그대로 사용하고 있다. 그래서, `arch/arm64/include/asm/topology.h` 파일을 보면 `linux/arch_topology.h`와 `asm-generic/topology.h` 파일을 확인할 수 있다. 그중에서 `arm64`는 `linux/arch_topology.h` 파일에 정의된 구조체 및 매크로를 사용한다. `arch_topology.h` 파일의 정체가 뭘까?
: 일반적인 커널 코드를 작성할 때, 제조사의 독립적인 코드들은 인터페이스를 통해서 추상화가 되었다. 즉, 인터페이스안에 구체적인 내용은 각 제조사가 작성하고, 외부 인터페이스만 통일하도록 한 것이다. 그런데, `architectures common topology code` 는 `CPU 토폴로지` 외부 인터페이스 뿐만 아니라, 인터페이스안에 내용까지 OS가 작성한다. `linux/arch_topology.h` 파일을 보자.
Enable support for architectures common topology code: e.g., parsing CPU capacity information from DT, usage of such information for appropriate scaling, sysfs interface for reading capacity values at runtime.
- 참고 : https://cateee.net/lkddb/web-lkddb/GENERIC_ARCH_TOPOLOGY.html: 아래의 매크로 함수들이 커널에 의해서 이미 정의가 되어있는 것을 확인할 수 있다. 이제 CPU 제조사는 매크로 함수의 내용에 맞게 `struct cpu_topology` 필드에 적당한 값을 넣어놔야 한다.
// include/linux/arch_topology.h - v6.5 /* SPDX-License-Identifier: GPL-2.0 */ /* * include/linux/arch_topology.h - arch specific cpu topology information */ .... struct cpu_topology { int thread_id; int core_id; int cluster_id; int package_id; cpumask_t thread_sibling; cpumask_t core_sibling; cpumask_t cluster_sibling; cpumask_t llc_sibling; }; #ifdef CONFIG_GENERIC_ARCH_TOPOLOGY extern struct cpu_topology cpu_topology[NR_CPUS]; .... #define topology_physical_package_id(cpu) (cpu_topology[cpu].package_id) #define topology_cluster_id(cpu) (cpu_topology[cpu].cluster_id) #define topology_core_id(cpu) (cpu_topology[cpu].core_id) #define topology_core_cpumask(cpu) (&cpu_topology[cpu].core_sibling) #define topology_sibling_cpumask(cpu) (&cpu_topology[cpu].thread_sibling) #define topology_cluster_cpumask(cpu) (&cpu_topology[cpu].cluster_sibling) #define topology_llc_cpumask(cpu) (&cpu_topology[cpu].llc_sibling) .... #endif .... // arch/arm64/include/asm/topology.h - v6.5 /* SPDX-License-Identifier: GPL-2.0 */ #ifndef __ASM_TOPOLOGY_H #define __ASM_TOPOLOGY_H #include <linux/cpumask.h> #ifdef CONFIG_NUMA struct pci_bus; int pcibus_to_node(struct pci_bus *bus); #define cpumask_of_pcibus(bus) (pcibus_to_node(bus) == -1 ? \ cpu_all_mask : \ cpumask_of_node(pcibus_to_node(bus))) #endif /* CONFIG_NUMA */ #include <linux/arch_topology.h> void update_freq_counters_refs(void); /* Replace task scheduler's default frequency-invariant accounting */ #define arch_scale_freq_tick topology_scale_freq_tick #define arch_set_freq_scale topology_set_freq_scale #define arch_scale_freq_capacity topology_get_freq_scale #define arch_scale_freq_invariant topology_scale_freq_invariant #ifdef CONFIG_ACPI_CPPC_LIB #define arch_init_invariance_cppc topology_init_cpu_capacity_cppc #endif /* Replace task scheduler's default cpu-invariant accounting */ #define arch_scale_cpu_capacity topology_get_cpu_scale /* Enable topology flag updates */ #define arch_update_cpu_topology topology_update_cpu_topology /* Replace task scheduler's default thermal pressure API */ #define arch_scale_thermal_pressure topology_get_thermal_pressure #define arch_update_thermal_pressure topology_update_thermal_pressure #include <asm-generic/topology.h> #endif /* _ASM_ARM_TOPOLOGY_H */: `struct cpu_topology` 구조체는 CPU 코어 한 개에 대응된다. 그 아래 전역 변수로 선언된 `cpu_topology`가 실제 시스템 전체 `CPU topology`를 의미한다. `NR_CPUS` 값은 시스템에 존재하는 전체 CPU 개수를 의미한다. 각 코어에 접근하기 위해서는 해당 코어에 대응하는 배열 인덱스값을 통해서 접근이 가능하다. `struct cpu_topology` 구조체 필드의 자세한 설명은 이 글을 참고하자.
1. cluster_id, core_id, thead_id는 `arm64`에서 제시하는 `CPU 토폴로지` 세 계층을 대응한다. `pakage_id`는 인텔을 위해서 만들어논 필드다.
2. thread_sibling : arm64를 기준으로 동일 `core id`에 속한 모든 thread를 나타내는 변수
3. core_siblings : arm64를 기준으로 동일 `cluster_id`에 속한 모든 CPU 코어들을 나타내는 변수: `Kernel general CPU topology` 에서 정의한 매크로를 재정의하는 것을 볼 수 있다. `arm64`는 별도의 아키텍처 종속적인 파일을 생성하기도 보다는 `include/linux/arch_topology.h`에서 정의한 방식을 채택하고 있다. 아래에서 보여주는 매크로 함수들은 `struct cpu_topology` 구조체에서 특정 필드들을 반환하는 형식으로 간단하게 구현되어 있다.
// include/linux/arch_topology.h - v6.5 #ifdef CONFIG_GENERIC_ARCH_TOPOLOGY .... #define topology_physical_package_id(cpu) (cpu_topology[cpu].package_id) #define topology_cluster_id(cpu) (cpu_topology[cpu].cluster_id) #define topology_core_id(cpu) (cpu_topology[cpu].core_id) #define topology_core_cpumask(cpu) (&cpu_topology[cpu].core_sibling) #define topology_sibling_cpumask(cpu) (&cpu_topology[cpu].thread_sibling) #define topology_cluster_cpumask(cpu) (&cpu_topology[cpu].cluster_sibling) #define topology_llc_cpumask(cpu) (&cpu_topology[cpu].llc_sibling) .... #endif: 실제 하드웨어 `CPU 토폴로지`를 소프트웨어로 컨버팅하는 과정에서 아래의 함수들이 사용된다. 이 함수들 또한 `drivers/base/arch_topology.c` 파일에서 정의하고 있다. 즉, 아래 함수들 또한 `architectures common topology code` 이다. 그런데, 앞에서 언급한 `컨버팅` 이라는 것은 어떻게 진행이 될까? `컨버팅`은 결국, `하드웨어 CPU 토폴로지`의 정보를 전역 변수인 `struct cpu_topology`에 어떻게 저장할 것인가에 대한 내용이다.
// include/linux/arch_topology.h - v6.5 #ifdef CONFIG_GENERIC_ARCH_TOPOLOGY .... void init_cpu_topology(void); void store_cpu_topology(unsigned int cpuid); const struct cpumask *cpu_coregroup_mask(int cpu); const struct cpumask *cpu_clustergroup_mask(int cpu); void update_siblings_masks(unsigned int cpu); void remove_cpu_topology(unsigned int cpuid); void reset_cpu_topology(void); int parse_acpi_topology(void); .... #endif: 그렇다면, 위에 함수들은 `하드웨어 CPU 토폴로지`를 어떻게 알 수 있을까? 리눅스 커널에서 하드웨어 정보를 어디에 저장할까? 바로 `디바이스 트리`에 작성한다. 각 제조사들은 디바이스 트리에 `CPU 토폴로지` 정보를 저장하게 된다. 그렇다면, 우리는 `arm64`의 `하드웨어 CPU 토폴로지`를 어떻게 작성해야 하는지 알아봐야 한다. 이 문서를 참고하자.
- ARM CPU topology in device-tree
: `ARM CPU 토폴로지`는 `cpu-map` 노드안에 작성해야 한다. 그리고, 이 `cpu-map` 노드는 반드시 `cpus` 노드의 자식 노드여야 한다. `cpu-map` 노드는 실제 `ARM CPU topology`를 구성하는 노드들의 컨테이너같은 역할을 한다. `cpu-map` 노드안에는 딱 3개의 노드만이 포함될 수 있다.
1. cluseter node
2. core node
3. thread node: 위에 노드중에서 `cpu-map` 노드의 자식 노드로 올 수 있는 노드는 `cluster` 노드뿐이다. 그리고, 위의 노드들은 `cpu-map` 안에 작성될 때, `clusterN`, `coreN`, `threadN` 네이밍 컨벤션을 따라야 한다(`N` = {0, 1, 2, ...}).
: `cluster node`의 사용 목적은 ARM big.Little 아키텍처를 생각하면 된다. 예를 들어, `cluster0`에 높은 성능을 자랑하는 CPU 코어들을 배치하고, `cluster1`에 저전력 코어들을 배치할 수 가 있다. `cluster node`는 절대 `leaf node`가 될 수 없다. 즉, 반드시 자식이 있어야 한다. `cluster node`는 여러 개의 `cluster node`와 여러 개의 `core node`를 가질 수 있다.
: `core node`는 반드시 `cluster node` 안에서만 작성되어야 한다. 그리고, 프로세서가 `SMT` 기능을 지원하면 `core node`안에 여러 개의 `thread node`를 작성할 수 있다. 그러나, `SMT`를 지원하지 않는다면 `core node`는 반드시 `leaf node`가 되야한다. 즉, 자식 노드가 없는 노드가 된다는 뜻이다.
: `thread node`는 반드시 `core node` 안에서만 작성되어야 한다. 만약, 프로세서가 `SMT` 기능을 지원하면 `thread node`는 반드시 `leaf node`가 되어야 한다. 그리고, `thread node` 안에는 반드시 `cpu` 속성을 작성해야 한다. 이 속성을 통해서 실제 특정 CPU가 `CPU 토폴로지`에서 어디에 속하는지를 알 수 있게된다. 예를 들어, 아래에서 `theard1 { cpu = <&CPU1> }` 노드를 보자. 여기서 `CPU1` 노드는 실제 물리적인 CPU 정보를 나타내는 노드가 된다. 즉, 아래 디바이스 트리는 크게 2개로 나눠볼 수 있다.
1. CPU 토폴로지 구조
2. 실제 물리적인 CPU 정보: 아래 디바이스 트리는 위에서 설명한 내용을 통해 쉽게 해석이 가능할 것이므로, 구체적인 설명은 생략한다.
// https://www.kernel.org/doc/Documentation/devicetree/bindings/arm/topology.txt .... Example 1 (ARM 64-bit, 16-cpu system, two clusters of clusters): cpus { #size-cells = <0>; #address-cells = <2>; cpu-map { cluster0 { cluster0 { core0 { thread0 { cpu = <&CPU0>; }; thread1 { cpu = <&CPU1>; }; }; core1 { thread0 { cpu = <&CPU2>; }; thread1 { cpu = <&CPU3>; }; }; }; cluster1 { core0 { thread0 { cpu = <&CPU4>; }; thread1 { cpu = <&CPU5>; }; }; core1 { thread0 { cpu = <&CPU6>; }; thread1 { cpu = <&CPU7>; }; }; }; }; cluster1 { cluster0 { core0 { thread0 { cpu = <&CPU8>; }; thread1 { cpu = <&CPU9>; }; }; core1 { thread0 { cpu = <&CPU10>; }; thread1 { cpu = <&CPU11>; }; }; }; cluster1 { core0 { thread0 { cpu = <&CPU12>; }; thread1 { cpu = <&CPU13>; }; }; core1 { thread0 { cpu = <&CPU14>; }; thread1 { cpu = <&CPU15>; }; }; }; }; }; CPU0: cpu@0 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x0>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU1: cpu@1 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x1>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU2: cpu@100 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x100>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU3: cpu@101 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x101>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU4: cpu@10000 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x10000>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU5: cpu@10001 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x10001>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU6: cpu@10100 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x10100>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU7: cpu@10101 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x0 0x10101>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU8: cpu@100000000 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x0>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU9: cpu@100000001 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x1>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU10: cpu@100000100 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x100>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU11: cpu@100000101 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x101>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU12: cpu@100010000 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x10000>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU13: cpu@100010001 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x10001>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU14: cpu@100010100 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x10100>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; CPU15: cpu@100010101 { device_type = "cpu"; compatible = "arm,cortex-a57"; reg = <0x1 0x10101>; enable-method = "spin-table"; cpu-release-addr = <0 0x20000000>; }; };: 참고로, 이 글에서는 `CPU 토폴로지`가 어떻게 스케줄러에서 사용되는지 설명하지 않았다. 해당 내용은 SMP 파트에서 자세히 다루도록 한다.
- CPU topology driver
: CPU topology driver는 'drivers\base\topology.c'에 위치하고 'include/linux/topology.h'에서 제공하는 API를 기반으로 sysfs의 형태로 CPU topology 정보를 얻기 위한 인터페이스를 사용자 공간에 제공하며, 이 인터페이스를 기반으로 `lscpu` 애플리케이션이 구현된다고 보면 된다. 구체적인 구현은 비교적 간단하며 sysfs의 형식은 "Documentation\cputology.txt"를 참고바란다.
'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] pinctrl - raspberry pi 3 overview (0) 2023.08.04 [리눅스 커널] SMP - cpumask (0) 2023.08.03 [리눅스 커널] CPU overview (0) 2023.08.03 [리눅스 커널] Bus Types. (0) 2023.08.03 [리눅스 커널] PM - System Power Management (0) 2023.08.03
{kind=link}