-
[리눅스 커널] IRQ - workqueueLinux/kernel 2023. 12. 30. 15:21
글의 참고
- https://docs.kernel.org/core-api/workqueue.html
- https://lwn.net/Articles/355700/
- https://lwn.net/Articles/23634/
- https://lwn.net/Articles/329464/
- https://lwn.net/Articles/211279/
- https://lwn.net/Articles/393171/
- https://lwn.net/Articles/403891/
- http://www.wowotech.net/irq_subsystem/workqueue.html
- http://www.wowotech.net/process_management/schedule-in-interrupt.html
- https://www.kernel.org/doc/html/v5.11/x86/kernel-stacks.html
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" v2.6.36 전에 workqueue 코드는 대략 800 줄 정도밖에 안됬지만, CMWQ(Concurrency Managed Workqueue) 가 v2.6.36 에 도입되면서 5,000 줄 까지 코드가 확장되었다. CMWQ 를 제대로 이해하기는 상당히 어렵기 때문에, 이 글은 v2.6.23 을 기준으로 작성되었고, CMWQ 에 대한 개론을 다룬다고 보면 될 것 같다.
- Why workqueue is nedded ?
1. What are interrupt conext and process context ?
" workqueue 에 대해 알아보기 전에 interrupt context 가 무엇인지 알아야 한다. 그렇다면, interrupt context 란 무엇일까? 리눅스 커널에서 정의한 interrut context 는 특정 상황을 의미한다. 이 상황은 크게 2 가지로 나눠볼 수 있다.
1. top half - 우리가 일반적으로 알고 있는 interrupt handling 을 할 때, 현재 context 가 interrupt context 라고 정의한다.
2. bottom half - softirq, tasklet 를 처리할 때, 현재 context 가 interrupt context 라고 정의한다." top half 는 이해하기 쉬울 것 이다. 말 그대로 발생한 interrupt 를 처리할 때, interrupt contex 라고 정의한다는 것이다. 그런데, bottom half 는 조금 감이 안온다. bottom half 를 조금 더 구체적으로 정의해보자. 즉, 언제 bottom half 가 발생하는지를 조금 더 구체적으로 알아보자.
1. top half 가 끝난 이후, 즉각적으로 bottom half 가 실행된다.
2. interrupt 가 자주 발생할 경우(즉, 부하가 심할 경우), 일정 기간 동안은 interrupt handler 와 softirq 를 처리하느라, process 를 scheduling 하지 못하게 된다(interrupt context 에 있는 동안에는 process scheduling 이 불가능). 그래서, 리눅스 커널은 softirq 처리를 ksoftirqd 라는 kernel thread 에게 위임함으로써 delayed execution 을 사용한다(이 글에서 __do_softirq() 함수를 분석한 내용을 참고).
3. process 가 kernel space 에서 critical section 내에 코드를 실행중일때, 동기화 목적으로 local_bh_disalbe() / local_bh_enable() 함수를 사용할 수 있다. critical section 에 진입하기 전에 local_bh_disable() 함수를 호출하면, softirq 에 의한 선점을 막을 수 있다. 그리고, interrupt 가 발생하더라도, softirq 가 disabled 되어 있기 때문에, interrupt 가 return 되는 시점에 즉각적으로 softirq 가 실행될 수 없다. critical section 작업이 마무리 되고, local_bh_enable() 함수를 호출하면, 이전 raised 되었던 softirq handler 가 호출된다(local_bh_*() 함수에 대한 내용은 이 글을 참고하자)." 1, 3 번 케이스는 실제 bottom half(or softirq handler) 를 수행하기 때문에, interrupt context 라고 불러도 전혀 이상하지 않다. 그런데, 2 번 케이스는 softirq 를 처리하다가 너무 오랫동안 process scheduling 을 하지 않았으므로, 잠시 softirq 처리를 멈추고 process scheduling 을 하겠다는 뜻이다. 이 때, 남아있는 softirqs 가 있다면, ksoftirqd 라는 kernel thread(process context) 에게 위임한다는 내용이다. 이렇게 되면, ksoftirqd 도 kernel thread 이기 때문에, 다른 kernel thread 들과 CPU 를 두고 동일하게 경쟁하게 된다. 그런데, 문제는 ksoftirqd 가 software interrupt context 에서 수행된다고 볼 수 있을까? 내 개인적인 생각은 아니라고 생각이 들지만(RT-Linux 가 아니라면, ksoftirqd 는 일반 kernel thread 와 우선 순위가 동일), 리눅스 커널은 ksoftirqd 도 software interrupt context 에서 실행된다고 분류한다.
" process context 는 기본적으로 자신만의 hardware context, user stack, kernel stack, user space text segment, data segment 등 다양한 resources 들을 가지고 있다. 그러나, interrupt context 는 process context 가 가지고 있는 많은 resources 들을 가지고 있지 않다. 여기서 의문이 든다. 사실, interrupt hander 도 결국은 함수이기 때문에, 지역 변수를 선언할텐데, 지역 변수는 stack 에 선언된다. 그렇다면, interrut context 에서 사용하는 stack 은 대체 어디에 있는걸까? 만약, interrupt context 전용 stack 이 없다면, 어떻게 해야할까? 빌리는 방법밖에 없다. 바로, interrupt 에 의해 선점당했던 process 및 thread 의 stack 을 빌려야 한다(x86 에서는 이전 프로세스의 stack 을 빌려 사용했다. 이게 가능한 이유는 interrupt context 에서 하는 일이 별로 없으니 stack 을 많이 사용하지 않았다. 그래서, 이전 프로세스의 stack 을 공유하더라도 stack overflow 가 발생할 확률이 적었던 것이다. 그러나, x86_64 부터는 IST(Interrupt Stack Table) 을 제공하면서 Interrupt 가 발생하면, TSS 에 명시된 7 개의 stacks 중에 하나를 할당받아서 거기서 interrupt 를 처리한다).
2. How to know the current context ?
(1) hard interrupt context
" 현재 실행중인 코드의 context 를 어떻게 구분할까? in_irq() 함수는 현재 코드가 `hard interrupt context` 에서 실행중 인지를 판별한다. top half 를 처리할 때는 irq_enter() 와 irq_exit() 함수로 둘러쌓였다. 즉, top half 를 처리하기 전에 irq_enter() 호출하고, top half 가 마무리되면, irq_exit() 함수를 호출했다. irq_enter() 함수 내부에는 preempt_count_add(HARDIRQ_OFFSET) 함수가 호출되어서 hardirq count 를 1 증가시켰다.
// include/linux/hardirq.h - v2.6.23 #define hardirq_count() (preempt_count() & HARDIRQ_MASK) /* * Are we doing bottom half or hardware interrupt processing? * Are we in a softirq context? Interrupt context? */ #define in_irq() (hardirq_count())" irq_exit() 함수내부 에서는 preempt_count_sub(HARDIRQ_OFFSET) 함수가 호출되서 hardirq count 를 1 감소시켰다. 그러므로, in_irq() 함수가 0 이 아닌 값을 반환하면, 현재 코드는 interrupt context 에서 실행됨을 의미했고, interrupt context 중에서도 top half 를 처리중임을 의미했다(참고로, v6.5 를 기준으로 in_irq() 함수를 deprecated 되었다. 대신, in_hardirq() 를 사용한다).
(2) software interrupt context
" 그렇다면, 현재 실행중인 코드가 software interrupt context 인지는 어떻게 알 수 있을까? 다른 말로, 현재 실행중인 코드가 bottom half 를 처리 중 인지를 알 수 있을까? in_serving_softirq() 함수를 사용하면 된다(참고로, v6.5 를 기준으로 in_softirq() 함수를 deprecated 되었다. 대신, in_serving_softirq() 를 사용한다).
// include/linux/hardirq.h - v2.6.23 #define softirq_count() (preempt_count() & SOFTIRQ_MASK) /* * Are we doing bottom half or hardware interrupt processing? * Are we in a softirq context? Interrupt context? */ .... #define in_softirq() (softirq_count())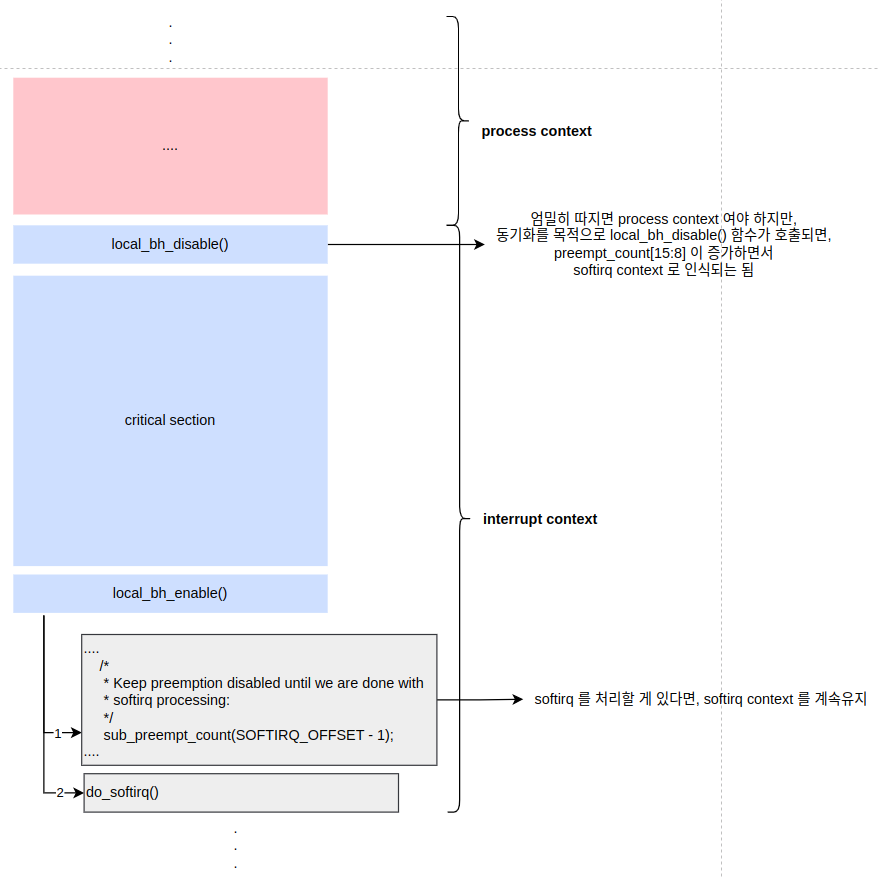
" 커널 동기화를 위해서 특정 critical section 에서는 softirq 가 disabled 될 수 도 있다. critical section 에서 bottom half 에 선점되지 않기 위해 커널은 local_bh_disable() / local_bh_enabl() 함수를 제공한다. local_bh_disable() 함수를 호출하면, softirq 가 trigger 되는 것을 막을 수 있다. 그래서, critical section 에 진입하기전에 local_bh_disable() 함수를 호출하고, critical section 이 끝난뒤 softirq handler 가 trigger 될 수 있도록 local_bh_enable() 함수를 호출한다(local_bh_disable() 함수를 호출해도 critical section 내에서 softirq 를 rasied 될 수 있다. 그러나, softirq handler 가 trigger 되지는 않는다). 참고로, in_softirq() 함수는 현재 softirq 가 처리중이여서 softirq context 인지 혹은 process context 에서 동기화를 목적으로 local_bh_disable() 함수를 호출해서 softirq context 로 인식하는지를 구분하지 못한다(in_serving_softirq() 함수는 현재 softirq 처리중인지만 판별한다)
(3) interrupt context
" 앞에서 현재 실행중인 코드가 hardirq context 인지 softirq context 인지를 구분하는 방법에 대해 알아봤다. 구분하지 말고, 그냥, interrupt context 인지를 알아보고 싶을 때가 있다. 그 때, in_interrupt() 함수를 사용하면 된다.
// include/linux/hardirq.h - v2.6.23 #define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK)) /* * Are we doing bottom half or hardware interrupt processing? * Are we in a softirq context? Interrupt context? */ #define in_interrupt() (irq_count())3. Why can`t the interrupt context sleep ? [참고1]
" linux driver engineers 라면, 한 번쯤은 들어봤을 법한 명언이 있다. 바로, `interrupt context 에서는 sleepable`s APIs 를 사용하면 안된다` 이다. 왜 그럴까? sleep 은 기본적으로 context switching 을 유발한다. 즉, scheduler 는 현재 실행중 인 task 를 sleep 하고(block queue 에 삽입), runqueue 에서 runable task 를 꺼내서 실행한다. 사실 이게 말이 쉽지, 실제 동작은 상당히 복잡하다. 예전에 wifi driver 를 디버깅할 때, stress test 를 진행하면 system 이 down 되는 이슈가 있었다. debugging 결과 timer callback 함수안에서 kmalloc() 함수가 여러 번 호출해서 발생한 이슈였던 것이다. 왜 timer callback 에서 kmalloc() 함수를 호출하는게 문제가 될까? kmalloc() 함수 같은 경우 특정 케이스에서 현재 동작중인 process 를 blocked 할 수 있기 때문이었다.
" 대부분의 운영 체제에서는 interrupt context 에서는 sleep 을 허용하지 않는다(Solaris 는 예외). 일반적으로, interrupt 가 발생하면, 해당 interrupt 에 대응하는 interrupt handler 가 있다. 그리고, 해당 interrupt handler 에 대응하는 interrupt task(process or thread) 가 존재한다. 대다수의 RTOS 에서는 interrupt handler 에서 interrupt 를 처리하지 않는다(즉, interrupt context 가 상당히 짧음). 거의 interrupt task 에게 interrupt handling 을 위임한다. 즉, interrupt context 를 상당히 짧게 가져간다. interrupt task 는 process context 에서 동작할 수 있기 때문에, interrupt task 안에서는 context switching 을 유발하는 sleepable`s APIs 들도 호출할 수 있다.
" 리눅스 커널 스케줄러는 thread 단위로 scheduling 을 한다. 그리고, process scheduling 에서 thread 는 struct sched_entity 로 인식된다. 그렇다면, 리눅스 커널에서 사용하는 interrupt context 용 scheduling entity 는 뭘까? 당연히 없다. 왜냐면, 애초에 리눅스 커널은 설계 단계에서 interrupt context 를 scheduling 대상으로 두지 않았기 때문이다. 결국, hardirq 와 softriq 와 같은 interrupt context 는 리눅스 커널의 scheduling 대상이 아니다(리눅스 커널의 scheduler 는 process scheduling 만 인식한다). 이렇게 설계한 이유는 scheduling 을 thread 단위로만 unified 함으로써, 설계의 복잡성을 줄이기 위해서다. 만약, interrupt scheduling entity 를 별도로 만들고 thread 와 interrupt 를 동시에 scheduling 했다면, 구조가 상당히 복잡해졌을 것이다(threaded irq 같은 경우, interrupt 를 스레드화한다. 즉, interrupt 와 thread 를 별도의 scheduling entity 를 생성하는게 아니라, unified scheduling 으로 다루기 위해서 interrupt 를 thread 로 만들어버림. 대신, 비교는 process prioriy 로 설정하고, threaded irq 는 일반 kernel thread 보다 우선 순위가 높게 설정한다).
" 그리고, interrupt 가 발생하면 CPU 는 무조건 선점된다. 예외가 없다. 이 말은 하드웨어 설계 자체가 interrupt 의 우선 순위를 다른 무엇보다 높게 인식한다는 것이다. 즉, 이 말은 모든 interrupt context 는 항상 process context 보다 높은 우선 순위를 갖는다는 것을 의미한다. 위에 내용을 정리하면, 리눅스 커널이 interrupt context 를 설계할 때, 아래 2 가지 내용을 기반으로 한다는 것을 알 수 있다.
1. interrupt context 는 scheduling entity 가 아니다.
2. 하드웨어 설계 메커니즘에 따라 interrupt context 는 항상 process context 보다 우선 순위가 높다." interrupt context 에서 scheduling 함수를 사용하면, interrupt context 는 scheduling entity 가 아니기 때문에 복귀가 불가능하다. 즉, 처리중이던 interrupt 가 사라지는 것이다. 그리고,
4. The difference between workqueue and other bottom half ?
" 다른 bottom half 들과 달리 workqueue 는 process context 에서 동작하기 때문에, sleepable`s APIs 를 사용할 수 있다. interrupt handling 시에 sleep 관련 함수를 사용할 수 있다는 것은 driver engineers 들에게는 축복이라 말할 수 있다. 왜냐면, 실제 대부분의 APIs 들이 sleep 을 유발하기 때문이다. 물론, driver 에서 별도의 kernel thread 를 생성해서 자신만의 defering work 를 구현할 수 도 있다. 그러나, 이 방식을 추천하지 않는다. 왜냐면, 전체 system performance 가 떨어질 수 있기 때문이다. 상황을 하나 가정해보자. 리눅스 커널에서 driver code 안에 kernel thread 를 생성하는 것을 권고한다고 가정하자. 이렇게 되면, 모든 drivers 에서 자신만의 kernel thread 를 생성하고, scheduler 에게 엄청난 load 가 걸리면서, 전체 system performance 가 낮아질 우려가 있다. 그리고, 모든 kernel thread 에 대한 생성 및 관리를 kernel 에게 위임하는 이유는 stability 때문이다. 커널은 이미 견고한 software 다. 심지어, 리눅스 커널은 open source 로서 전 세계 수 많은 천재 개발자들에 의해서 수십년 동안 수정된 코드다. 그에 비하면, driver code 는 engineer 의 역량에 절대적으로 좌지우지되고, kernel thread 에 대한 생성 및 관리도 kernel 에 비하면 굉장히 떨어질 수 밖에 없다. 그렇기 때문에, 직접적으로 kernel thread 에 대한 생성 및 관리는 kernel 에게 위임하고, 간접적으로 kernel thread service 요청하는 workqueue 를 사용해서 driver code 를 작성하는 것이 stability 면에서 훠얼씬 안전하다고 볼 수 있다.
'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Dmesg Buffer Size 변경 (0) 2024.08.15 [리눅스 커널] /proc/config.gz 없을 경우 (0) 2024.08.14 [리눅스 커널] Interrupt - Driver interrupt handler (0) 2023.12.29 [리눅스 커널] Interrupt - High-level flow irq handler (1) 2023.12.27 [리눅스 커널] interrupt - IRQ number (1) 2023.12.27