-
[메모리] Fixed-size blocks allocation프로젝트/운영체제 만들기 2023. 8. 5. 17:03
글의 참고
http://www.thinkmind.org/index.php?view=article&articleid=computation_tools_2012_1_10_80006
https://en.wikipedia.org/wiki/Memory_pool
https://en.wikipedia.org/wiki/Memory_management#FIXED-SIZE
https://gee.cs.oswego.edu/dl/html/malloc.html
글의 전제
- 내가 글을 쓰다가 궁금한 점은 파란색 볼드체로 표현했다. 나도 모르기 때문에 나중에 알아봐야 할 내용이라는 뜻이다.
- 밑줄로 작성된 글은 좀 더 긴 설명이 필요해서 친 것이다. 그러므로, 밑 줄 처친 글이 이해가 안간다면 링크를 따라서 관련 내용을 공부하자.
글의 내용
- YohdaOS 메모리 풀
: YohdaOS의 메모리 풀은 `Fast Efficient Fixed-Size Memory Pool: No Loops and No Overhead` 의 내용을 기반으로 한다. 다른 메모리 할당 방식에 비해 난이도가 정말 쉬운 편이므로, 꼭 읽어라. 실제 동작 방식도 단순해서 알고리즘 자체가 깔끔하다.
- http://www.thinkmind.org/index.php?view=article&articleid=computation_tools_2012_1_10_80006
ThinkMind(TM) Digital Library
DataSys 2023 CongressJune 26, 2023 to June 30, 2023 - Nice, Saint-Laurent-du-Var, France AICT 2023, The Nineteenth Advanced International Conference on Telecommunications ICIW 2023, The Eighteenth International Conference on Internet and Web Applications a
www.thinkmind.org

: 위의 알고리즘은 시간안에 완료되어야 하는 시스템에 굉장히 적합한 알고리즘이라고 한다. 루프가 없다는 말은 이해했는데, `no-memory overhead`는 이해하지 못했다. 글을 보면서 알아봐야 겠다.

: 메모리 관리의 중요 요소에 대해 말해줍니다. 첫 번째에 아주 중요한 내용이 있습니다. 공간과 시간을 모두 챙기는 건 이상적인 겁니다. 메모리 단편화 문제는 메모리 할당에서 정말 핵심적인 부분이죠. 위키피디아에서도 나와있지만, 메모리 관리는(메모리 할당과 별개로 두었을 때) 결국 메모리의 corruption과 leaks에 대한 부분이다. 즉, 메모리를 빠짐없이 잘 사용하고 있는지와 사용되지 않는 메모리가 있는지를 모니터링하는 것이라고 볼 수 있다.
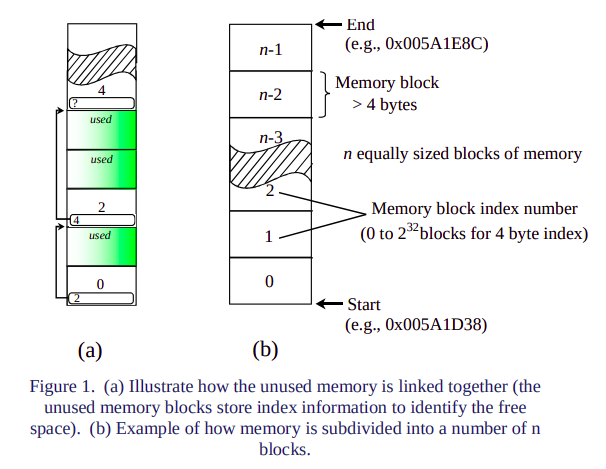
출처 - Fast Efficient Fixed-Sized Memory Pool : 왼쪽 사진만 보자. 저 그림으로 메모리 풀에 대한 설명은 충분하다. 이 메모리 풀의 각 블락은 `헤더 + 블락` 형태로 이루어져 있다. 헤더는 최소 다음 블락을 가리키는 포인터가 존재해야 한다. 헤더의 크기는 최소 다음 블락을 가리키는 포인터는 있어야 하므로, 32비트라면 최소 4바이트, 64비트라면 최소 8바이트가 된다. 위에서 왼쪽 그림을 보면, 0번 블락의 헤더에 `2`라고 써져있다. 이 말은 다음 FREE 블락이 2번 블락이라는 소리다. 2번 블락의 헤더를 보면, 4번 블락을 가리키는 것을 알 수 있다. 각 헤더의 포인터는 다음 FREE 블락을 가리킨다는 것을 기억하자.
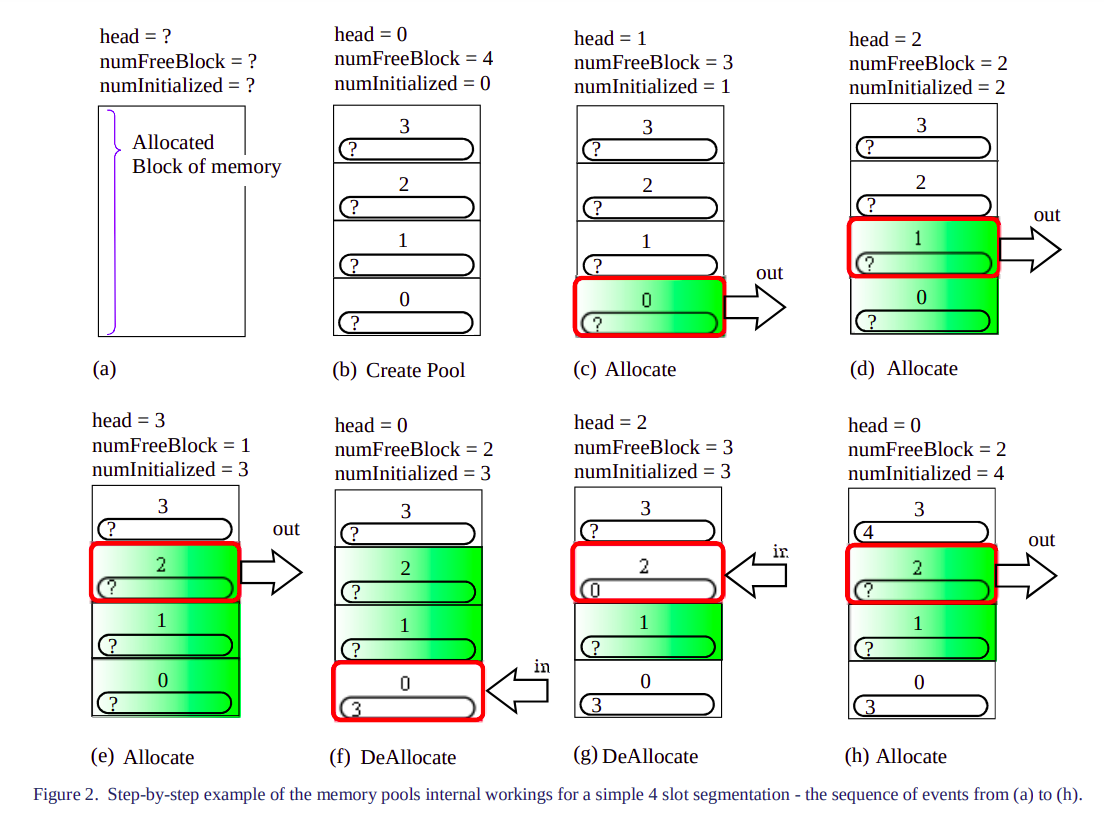
출처 - Fast Efficient Fixed-Sized Memory Pool : 좀 더 자세한 그림으로 설명하면 어떻게 구현해야 할지 감이 잡힐 것이다. (a)를 보면 3개의 변수가 보인다. HEAD는 POOL의 맨 앞 FREE BLOCK(흰색 배경 BLOCK)을 가리킨다. (a)는 아직 초기화가 이루어지지 않은 상황이다.
: (b)에서 새로운 POOL이 생성되면서 간단한 초기화를 진행한다. 이 때, HEAD가 0번 블락을 가리키고 전체 블락들을 카운트해서 FREE BLOCK 카운트에 대입한다. 말 그대로, 정말 간단한 초기화다. 아마 루프가 필요없을 것이다. 일단 이 단계에서는 각 블락은 Next free block에 대한 알 수가 없다.
: (c)에서 BLOCK에 대한 요청이 들어왔다. HEAD가 바라보는 BLOCK을 제공하면 된다. 주의할 점은 HEAD는 자신이 가리키는 BLOCK의 헤더의 Next block pointer의 값이 NULL일 때만 바로 다음 블락으로 이동해야 한다는 것이다. 그리고 이 단계에서 0번 블락이 할당되면서 HEAD, numFreeBlcoks, numInitialized 값이 어떻게 변하는지 확인하자.
: (d), (e) 단계 모두 앞에 (c) 단계와 동일하므로, 문제 없을 것이라 보인다.
: (f) 단계는 중요하다. 0번째 블락이 De-allocation 되었다. 그러면서, HEAD가 0번째 블락을 가리키고, 0번째 블락이 3번째 블락을 가리키는 것을 주의해서 봐야 한다.
: (g) 단계에서 2번째 블락도 De-allocation 되었다. HEAD가 2번째 블락을 가리킨다. 그리고 2번째 블락은 0번째 블락을 가리킨다. De-allocation의 특징은 다음과 같다.
1" HEAD는 De-allocation되는 블락을 가리킨다.
2" De-allocation된 블락은 HEAD가 바로 직전에 가리켰던 노드를 가리킨다.: (h) 다시 Allocation 요청이 들어왔다. HEAD가 가리키는 2번 블락이 할당되는 것을 확인할 수 있다. 그러면서, HEAD 다음 FREE BLOCK인 0번 블락(2번 블락이 가리키던)을 가리키는 것을 확인할 수 있다.
: 위 그림에서 이해가 안가는 부분이 있다. 마지막 (h)에서 3번 째 블락의 Next blcok pointer가 4를 가리킨다는 것이다. 그러면서, numInitialized의 값이 증가하는데 이 부분은 그럴 필요가 있나 싶다. 왜냐면, (h) 단계 이후에, 또 Allocation이 발생했다고 치자. 그러면, HEAD가 가리키는 0번째 블락이 할당될 것이고 HEAD는 3번 째 블락을 가리키게 될 것이다. 그런데, 3번째 블락의 Next block pointer가 NULL 이라면, 자동으로 바로 다음 주소로 이동하면 될 것 같은데 굳이 (h) 단계에서 저기에 4로 작성을 해서 혼란을 주는 건지 모르겠다. 아니면, 내가 말한 구현과 다를 수도 있다고 생각이 든다.

출처 - Fast Efficient Fixed-Sized Memory Pool : 그리고 또 이 알고리즘은 Allocation 동안에만 새로운 FREE BLOCK을 FREE LIST에 추가한다고 한다. 이게 잘 이해가 가지 않는다. 나는 이 알고리즘을 보면서, 해제 시에만 FREE BLOCK 들이 추가된다고 생각하고 있었다. 지금도 마찬가지다. New unused block 이라는 용어가 Unused block과 다르게 쓰일 것으로 보인다. 예를 들어, (c) 단계에서 0번 째 블락이 할당되면서, 1번 째 블락이 unused block으로 잡히게 된다. 그러면서, numInitialized값이 증가한다. 여기서 1번 째 블락이 처음으로 unused block이 되었으므로, new unused block 이라고 표현하는 듯 한데 이게 좀 애매한 듯 하다...

출처 - Fast Efficient Fixed-Sized Memory Pool : 위의 내용은 Verification 관련 내용인데, Memory guard를 이용해서 Verificaton을 진행하는 과정에 대해서 간단하게 설명되어 있다. 메모리 풀은 고정 사이즈로 나눠져 있으므로, 절대 오버랩이 발생해서는 안되는 구조다. 그러므로, 헤더쪽에 Next block pointer, Memory guard signature를 선언해서 이 시그니처들이 선언하고나서, 메모리 풀을 모두 사용할 때 까지 Allocation을 진행하자. 그런 다음, 메모리 풀은 고정된 사이즈이므로, 메모리 가드 시그니처 위치 또한 고정일 것이다. 이제 루프를 돌려서 모든 시그니처가 정상인지 확인해보자. 모두 정상이라면 오버랩이 발생하지 않았다고 볼 수 있을 것 같다.
: 메모리 릭에 대한 Verification도 생각보다 간단하게 검사하는 듯 하다. 할당받은 모든 메모리에 Memory guard signature를 wrtie하고, 메모리 풀에 할당된 모든 메모리를 Allocation 받는다. 그리고 할당된 메모리 공간은 초기화 되지 않은 공간이므로, 0으로 초기화한다. 그리고 루프를 돌려서 Memory guard signature가 사라졌는지 확인한다. 만약, 검사한 모든 공간이 0이라면 leaks이 없다고 판단한다.
: 당연히 이 메모리 풀도 단점이 많이 존재한다.
: 메모리 풀은 정렬된 메모리를 기준으로 동작한다. 메모리 풀의 메모리가 정렬되어 있지 않을 경우, 알고리즘 자체가 이렇게 심플할 수가 없다. 그리고 페이지 폴트가 발생할 시, 엄청나게 느려질 수 있다. 게다가, 멀티 스레드에 대한 고려가 전혀되어 있지 않다. 뿐만 아니라, 이 메모리 풀은 메모리에 직접 접근이 가능해야 하므로 Java 및 C# 같은 언어로는 구현이 불가능하다.
: 그리고 가장 큰 문제는 메모리 풀도 결국 단편화가 존재하게 된다. 너무 작은 메모리를 요청할 경우, 내부 단편화는 당연하고 더 심각해지는 상황은 메모리 풀이 감당할 수 없는 사이즈를 요청할 경우이다. 이럴 경우는, 아예 할당이 불가능하다.

출처 -
Fast Efficient Fixed-Sized Memory Pool: 위 글에서는 그럼에도 불구하고 memory wastage와 largely miss-sized allocations 들의 문제를 줄이기 위해 ad hoc solution을 사용할 수 있다는데 ad hoc 솔루션이 뭔지를 모르겠다. 그래서 알아보니 ad hoc은 메모리 풀을 보완 해주는 다른 메모리 할당자를 의미하는 것으로 보인다. 아래 글에서는 C++의 new와 delete 연산을 같이 사용할 경우, 실행 시간이 꾀나 감소했다는 내용인 것 같다. new와 delete 연산자는 대개 best-fit 방식의 알고리즘으로 알고있다. 즉, malloc()과 비슷하다. 그래서 속도가 느리다. 그런데 여기에 메모리 풀을 추가해서 특정 사이즈가 메모리 풀에 best-fit으로 들어맞으면 메모리 풀이 해당 메모리를 반환해주는 식으로 보완해서 속도를 높였다는 내용인 것 같다.

출처 -
Fast Efficient Fixed-Sized Memory Pool- 메모리 할당
: 현재 YohdaOS에의 메모리 관리 방식인 버디와 풀에는 메모리 보호 기능은 없다.
: 여러 개의 풀로 구성이 되어 있다. 예를 들어, 16B, 32B, 64B, ... 1K의 풀로 구성되어 있다. 각 풀에 할당된 메모리는 서로 독립적이기 때문에, 64B 풀에서 할당한 메모리는 16B 풀에 영향을 주지 않는다.

: YohdaOS의 버디에서는 2000K를 할당받을 경우, 1024K를 버디 메모리로 할당한다. 그리고 만약 1024K를 요청하면 그것보다 작은 사이즈들의 블락들은 할당을 하지 못한다.
: 그러나 YohdaOS의 메모리 풀은 2000K를 할당받을 경우, 메모리를 적절하게 분배해서 각 풀(16B 풀, 32B 풀, 64B 풀 등등)에 분배한다. 즉, 16B에 64K, 32B에 128K, 64B 풀에 256K 과 같은 방식으로 말이다. 그래서 각각의 풀이 서로 독립적으로 동작할 수 있게 구성되어 있다.
: YohdaOS의 메모리 풀의 각 청크들의 사이즈는 1K 이하로 설정했다. 버디의 하한 블락 사이즈를 페이지 크기와 동일하게 잡았는데, 페이지 크기는 대게 작게는 2K, 보통 4K, 크게는 2MB 이상을 잡기도 한다.
: YohdaOS의 메모리 풀의 주목적은 버디의 내부 단편화를 줄이는 목적이다. 버디만 있을 경우, 8B를 요청해도 2K 및 4K를 할당한다. 엄청 난 내부 단편화가 발생한다. 그래서 작은 사이즈들에게 할당할 메모리 풀을 보조 역할로 만들게 되었다.
: YohdaOS 메모리 풀은 내부 단편화를 줄이기 위해 등장했기 때문에,
자주 사용되는 풀의 사이즈는 유동적으로 변경이 된다. 메모리 풀중에 32B 풀이 자주 사용된다고 치자. 그런데, 어느 순간 32B 풀을 다 사용했다. 그러면 버디에서 새로 메모리를 할당받아서 32B 풀에 할당한다.: 메모리 풀의 사이즈가 부족해서 버디 할당자에서 할당받을 경우, 버디에서 큰 사이즈의 데이터를 할당해주지 못하는 경우가 발생한다. 버디 할당자의 메모리 관리 구조상, 제일 작은 청크 단위의 메모리를 할당 받는 순간 제일 큰 블락은 일단 무조건 할당받지 못하게 된다. 그래서 메모리 풀이 버디 할당자에서 메모리를 할당받지 못하도록 해야 한다.
: 버디 할당자에 도움을 받지 않고, 메모리 풀이 각 풀의 개수를 동적으로 늘릴 경우, 외부 단편화가 발생할 수 있다. 메모리 풀안에 작은 청크들은 여기서 문제가 되지 않지만, 메모리 풀 자체가 사용되지 않을 경우 해당 메모리 풀을 제거해야 할 수 도 있다. 그런데, 이 메모리 풀을 삭제할 경우, 중간에 `hole`이 생길 수 있다. 바로 이 부분이 외부 단편화가 발생되는 지점이다. 예를 들어, 16B 메모리 풀이 자주 사용되서 새로운 16B 메모리 풀을 하나 더 생성했다고 치자. 그런데 시간이 지나서 이 16B 메모리 풀이 잘 사용되지 않게 된 것이다. 이럴 경우 이 풀을 반환해서 다른 데 사용해야 할 상황이 생길 수 있다. 그래서 결국 반환을 했다. 그런데, 이 16B 메모리 풀뒤에 할당된 영역이 없다면 모를까 뒤에 다른 사용되는 영역이 있다면, 이 영역은 외부 단편화 구간이 되버린다. 아래 그림과 풀의 개수를 늘릴 경우 외부 단편화가 발생한 것을 볼 수 있다.
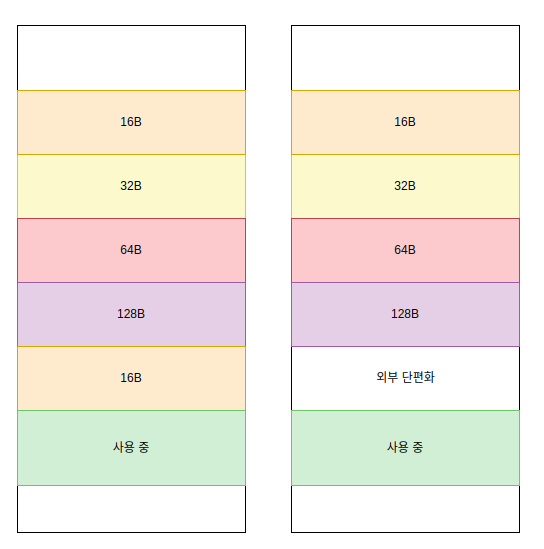
: 그렇면 풀의 사이즈를 늘리는 방안은 어떨까? 즉, 최초에 16B 풀의 사이즈가 4096B 였는데, 이걸 8192B로 늘리는 것이다. 메모리의 확장을 하면 그 경계에 있던 메모리들이 영향을 받기 어마 무시한 동기화가 발생할 수 있다. 이러한 동기화는 결국 퍼포먼스의 저하로 이어진다.
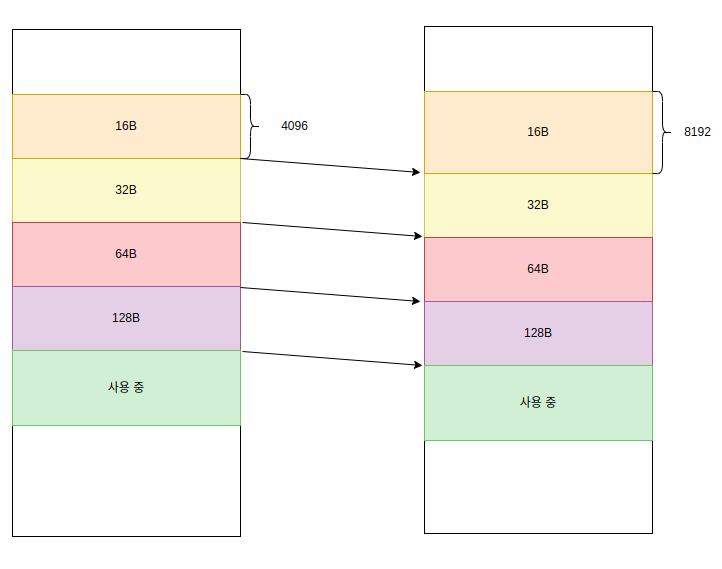
: 각 메모리 사이에 약간 어느 정도 갭을 두는 방안도 생각할 수 있지만, 그 갭은 해당 메모리 풀이 잘 사용되지 않을 경우, 결국 또 외부 단편화로 남아버릴 수도 있는 부분이 된다. 결국 메모리 풀의 외부 단편화를 막기 위해서는 최초에 정적으로 할당되는 시점에 고정되어야 한다. 그리고 동적으로 사이즈를 늘린다거나 개수를 늘려서도 안된다.

: 위와 같이 메타 데이터를 맨 앞쪽에 두고, 그 뒤로 정적 사이즈의 각 메모리 풀들의 데이터 영역을 배치할 것이다. 저 `Pool Metadata`는 각 메모리 풀에 대한 비트맵 영역이다. 나머지 관리 데이터는 전역 변수를 정적으로 선언해서 커널 영역으로 선언했지만, 비트맵은 데이터 영역 사이즈에 따라 동적으로 변경되기 때문에 커널 영역으로 정적으로 선언할 수가 없었다.
: 비트맵을 제외한 메모리 풀의 메타 데이터를 커널 영역에 선언한 이유는 메모리 풀의 영역 바로 앞이 버디 할당자 영역이기 때문이다. 버디 할당자와 연장선상안에 두기 위해 메타 데이터를 최소화했다.
: YohdaOS의 메모리 풀의 각 청크 사이즈는 2의 거듭제곱 사이즈다. 최소 16B 부터 최대 1K를 갖고, 2의 거듭제곱으로 사이즈가 증가한다. 즉, 7개의 메모리 풀이 존재한다. 2의 거듭제곱으로 정한 이유는 버디와의 연계를 위해서다. 메모리 풀의 각 청크 사이즈가 2의 거듭제곱이 아닐 경우, 내부 단편화가 발생한다.
: 최초에 메모리 풀에게 메모리가 할당될 때, 메모리 풀 개수로 나눠서 각 풀에게 동등한 메모리 사이즈를 제공한다. 메모리에 할당은 가장 작은 청크 풀부터 할당한다(내부 단편화를 줄이기 위해서는 작은 사이즈의 청크들이 많이 필요할 것으로 추정됨). 메모리가 남을 수 있다. 그에 대한 대책이 필요하다.
: 버디에서 먼저 메모리를 할당하고 남은 메모리를 할당하기 때문에, 거의 2의 거듭제곱으로 메모리가 떨어질 경우 메모리 풀에는 메모리가 할당되지 않을 수도 있다. 예를 들어, 8208B를 할당받을 경우 8K(8192)에 거의 근접한 값임으로 이 값은 딱 16B가 남게 된다. 위에서 말했다 시피, YohdaOS 메모리 풀은 가장 작은 청크 풀부터 메모리 할당을 받는다. 그리고 각 풀들은 기본 할당 값이라는 것이 존재한다. 그 기본 할당값만큼 할당을 받아야 다음 풀이 할당을 받을 수 있다. 예를 들어, 16B 풀의 기본 할당 값이 4K라면 4K를 모두 할당받아야 다음 풀인 32B 풀로 넘어간다.
: 각 풀에게 메모리 요청이 들어왔는데, 할당할 메모리가 없는 경우 버디에게 메모리를 요청한다. 이 값은 각 풀의 기본 할당 값만큼 요청한다.
- 메모리 반환
: 메모리 풀에서 메모리 반환은 간단하다. 버디 할당자에서는 반환되는 주소가 몇 번째 깊이에서 할당된 지를 알아야, 해제가 가능했다.그러나 메모리 풀은 아래와 같은 방식으로 어떤 메모리 풀에서 할당된 주소인지를 알 수 있다.
1" 각 메모리 풀은 베이스 데이터 어드레스가 존재한다.
2" 반환 주소가 각 메모리 풀 베이스 데이터 어드레스와 비교하여 어느 메모리 풀에 속하는지 알 수 있다.
3" 반환 주소가 어느 메모리 풀에 속하는지 알았다면, 그 주소가 메모리 풀에 몇 번지 였는지 알아야 한다. 이건 해당 메모리 풀의 베이스 데이터 어드레스와 빼고 나서, 청크 사이즈로 나누면 오프셋을 알 수 있다.: 버디 할당자에서는 위와 같이 하지 못하는 이유가 하나의 메모리를 공유하기 때문이다. 메모리 풀은 하나의 메모리를 공유하지 않는다. 자신만의 메모리 영역을 가지고 있다.
'프로젝트 > 운영체제 만들기' 카테고리의 다른 글
[운영체제 만들기] Lazy Buddy Allocator (0) 2023.08.07 [운영체제 만들기] Buddy Allcator (0) 2023.08.07 Real mode (0) 2023.08.05 Protected mode (0) 2023.08.05 [운영체제 만들기] FAT (0) 2023.08.05