-
[리눅스 커널] Timer - linux clockLinux/kernel 2023. 9. 30. 03:27
글의 참고
- https://docs.kernel.org/core-api/timekeeping.html
- https://stackoverflow.com/questions/3523442/difference-between-clock-realtime-and-clock-monotonic
- http://www.wowotech.net/timer_subsystem/clock-id-in-linux.html
- https://megastudy.net/mobile/smart/entinfo/brd/list.asp?t_Idx=319&t_Gubun=6
- https://namu.wiki/w/%EC%9C%A4%EC%B4%88
- http://www.wowotech.net/timer_subsystem/time_concept.html
- https://www.gnu.org/software/libc/manual/html_node/Broken_002ddown-Time.html
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" 리눅스에서 시간을 측정하는 방식은 굉장히 다양하다. 그러므로, 먼저 리눅스에서 사용하는 시간의 분류 기준을 알아보자. 먼저, `2시 42분` 이라고 했을 때, 이 기준이 뭘까? `2시 42분`을 어떤 기준으로 측정한 것일까? 시간이란 변화가 동반되는 개념이다. 그리고, 측정을 위해서는 단위가 필요하다. 즉, 인간이 `시간`을 측정하기 위해서는 시간의 변화가 규칙적이면서 일정하게 변화하는 현상으로 만들어야 했다.
" 그렇다면, 옛날 옛적에는 이런 주기적인 변화를 어디서 찾았을까? 자연 현상에서 찾을 수 밖에 없다. 왜냐면, 인간에 의해 만들어진 인위적인 변화는 시간이 지남에 따라 오차가 발생하기 마련이다. 자연 현상에서 주기적인 변화를 어디서 찾을 수 있을까? 최초에 거론된 것은 `천문학`이다. 천문학자들은 낮과 밤이 일정한 규칙을 띄고 있으며, 태양이 뜨고 지는 방향들이 항시 일정하다는 것을 알아냈다. 그래서, 이 기준을 토대로 시간을 표현하게 된다. 그래서, 지구 자전을 기준으로 24 시간을 정의하고, 1시간을 다시 60분으로 나누고, 1 분을 60 초로 나누었다. 즉, 천문학을 토대로 `시간` 을 표현하고 측정할 수 있게 된 것이다.
" 문제는 지구와 태양의 위치를 기준으로 시간 측정을 하다 보니, 날씨가 좋지 않으면 관측이 되지 않아 시간 측정이 불가능했다. 그리고, 시간에 지남에 따라 천체의 운동이라는 것이 기본적으로 안정적이지 않다는 것을 알게된다. 시간이 지남에 따라 기술의 발전함 하게 되고, 발진주파수를 통해 보다 안정적이면서 관측에 제약이 없는 시간 측정을 할 수 있게 되었다.
- Basic concepts about time
1. Epoch & wall time(wall clock)
" 현재 시간을 알기 위해서는 현재 얼마나 시간이 얼마나 지났는지를 알아야 한다. 여기서 `얼마나 지났는지` 라는 표현은 어떤 기준을 토대로 측정된 수치다. 이 기준을 `epoch` 라고 한다. `epoch` 는 주로 컴퓨터 시스템에서 시스템 시간을 측정하는 사용하는 `기준 시간`이라고 보면 된다. 대게 리눅스는 `epoch` 값을 `1970 00:00:00 UT`로 설정한다. 이 값을 기준으로 해서 시스템 부팅 시간이 얼마나 걸렸는등을 알 수 있다. 예를 들어, 시스템이 전원이 인가되는 시점에 시간을 `1970 00:00:00 UT`으로 설정하고, 시간을 카운트한다. 시스템 부팅이 끝나는 시점에 시간을 읽었을 때, `1970 00:00:21 UT` 라면, 부팅 시간이 21초 걸린 것이다.
In computing, an epoch is a fixed date and time used as a reference from which a computer measures system time. Most computer systems determine time as a number representing the seconds removed from a particular arbitrary date and time. For instance, Unix and POSIX measure time as the number of seconds that have passed since Thursday 1 January 1970 00:00:00 UT, a point in time known as the Unix epoch.
- 참고 : https://en.wikipedia.org/wiki/Epoch_(computing)" 위에서 봤다시피, 리눅스에서 `epoch`를 사용해서 측정하는 시간은 상대적인 시간 개념이다. 즉, 시스템 부팅 시점을 기준으로 현재 시간이 얼마나 흘렀는지를 알려준다. 이 시간은 실제 세상과의 시간과는 완전히 다른 개념이다. `wall time`이란 절대적인 시간을 말한다. 즉, 실제 세상의 시간을 의미한다. 당연하지만, 모든 컴퓨터 시스템은 2가지 시간 개념을 모두 필요로 한다.
2. leap second & TAI [참고1]
" 현재 시간을 정의할 때는 2 가지 방법이 사용된다.
1. atomic time - `원자시` or `세슘 133 원자 시` 라고도 불린다. 왜냐면, 세슘 133 원자의 진동 주기를 기준으로 1 초를 정의하기 때문이다. UTC 가 atomic time 을 사용한다.
2. universal time - `세계시` 혹은 UT 라고 불린다. 세계의 지방시 및 표준시는 모두 이 시간(세계시) 를 기준으로 결정된다. 세계시는 지구의 공전 및 자전 주기를 기준으로 1 초를 정의한다. 참고로, 세계시 는 GMT(그리니치 평균 천문시) 와 동의어다." 우리 나라를 비롯한 전 세계는 1972 년 1 월 1 일을 기준으로 하는 UTC 를 사용한다. UTC 는 `초` 를 정의할 때 원자시를 사용하지만, UTC 가 표시하는 시각은 세계시와 0.9 초 이내에 일치되도록 유지되어야 한다. 마지막 조건은 왜 붙은 것일까? UTC(원자시) 와 달리 실제 우리가 체감하는 하루 길이(세계시)는 매우 불규칙적이며 예측하기 어렵기 때문이다. UTC 에 기반이 되는 원자시는 원자의 진동수를 기준으로 하기 때문에, 기상 및 외부의 영향을 거의 받지 않아 매우 일정하다. 즉, 실제 하루 길이(세계시) 와 원자시가 동일하지 않기 때문에, 이걸 조정할 수 있는 방법이 필요했다. 그게 바로, `윤초(leap second)` 다. 결국, leap second 라는 것은 원자시와 세계시의 오차를 조정하기 위해 인위적으로 UTC 에 1 초를 더하거나 빼는 행위를 의미한다.
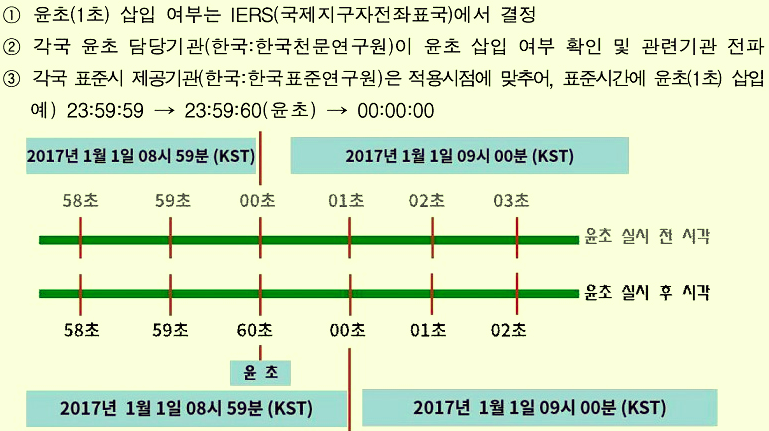
https://megastudy.net/mobile/smart/entinfo/brd/list.asp?t_Idx=319&t_Gubun=6" 리눅스 커널에서 사용하는 Linux epoch 는 UTC 를 기반으로 한다. 그러나, 리눅스 커널은 leap seconds 를 고려하지 않는다. 그 이유는 2 가지가 있다.
1. UTC(원자시) 와 GMT(세계시) 는 오랜 기간 지나야 차이가 어느 정도 있게 된다. 즉, 짧은 기간(Ex. 1 년) 은 거의 차이가 없기 때문에 실제 applications 들에게 영향을 주지 않는다.
2. 리눅스 커널은 leap second 를 고려하지 않는 대신, time synchronization 을 위해 NTP 프로토콜을 지원한다(엄밀히 말하면, NTP 프로토콜만 지원한다). 즉, NTP 를 통해 외부 time servers 들과 time synchronization 를 할 수 있고, 외부 타임서버들은 당연히 leap seconds 를 고려하기 때문에, 외부 타임서버와 리눅스 커널이 time synchronization 를 하면, 자동으로 leap second 가 적용된 것이라 볼 수 있다." TAI 란 `International Atomic Time` 의 약자로 atomic seconds 를 기반으로 동작하는 시간을 의미한다(한국어로는 `국제 원자시` 라고 한다). TAI 도 atomic seconds 를 기반으로 하기 때문에, GMT 및 UT 와는 달리 정확도가 상당히 높다. 그러나, atomic seconds 라는 것은 실제 하루 길이와는 관련이 없기 때문에, 인간의 일상과는 별개로 동작하는 시간이라고 볼 수 있다. 반면에, 지구의 공전 및 자전 주기로 동작하는 GMT 는 하루 길이를 정확히 표현하기 때문에 인간의 일상과 딱 들어맞는다 라고 말할 수 있지만, 문제는 정확도가 뒤떨어진다. 그래서, UTC 라는 시간이 도입되었다. UTC 는 TAI 를 기반으로 하지만, 실제 하루 길이 및 인간의 일상과도 유사한 시간으로 동작하기 위해 시간을 조정할 수 있다(leap seconds 를 통해서 가능).
" 즉, TAI 의 원자의 진동수를 통해 시간을 측정하기 때문에 완전히 정확한 시간을 측정하기 위해 존재하며, UT 는 지구의 공전 및 자전을 기준으로 시간을 측정하기 때문에 인간의 실제 일상에 가장 들어맞는 시간이라고 볼 수 있다. TAI 에 비해 정확도가 떨어진다. 전문가들은 정확하면서도(UTC) 실제 인간의 일상에 들어맞는(UT) 새로운 시간 체계인 UTC 를 만들게 되었다는 것이다.
" TAI 와 UTC 는 1972 년을 기준으로 시간을 맞췄고(이 때, 10 초 차이가 존재. 즉, 1972 년을 기준으로 서로 갈라설 때, 딱 10 초 차이를 기준으로 갈라서도록 설계) 그 이후부터는 서로 독립적인 시간으로 흐르고 있다. UTC 같은 경우는 TAI 를 기반으로 하지만, 특정 시점마다 시간 조정(leap seconds 작업) 을 하기 때문에, 현재는 UTC 와 TAI 의 시간이 꽤 차이가 난다. 예를 들어, 1972 년 부터 2023 년 까지 총 27 번의 leap seconds 작업이 진행됬기 때문에, TAI clock 은 UTC clock 보다 37 초 정도 빠르다(2016-12-31 일 마지막으로 지금까지 leap seconds 작업을 하지 않고 있다)[참고1].
3. How does linux calculate the current time ?
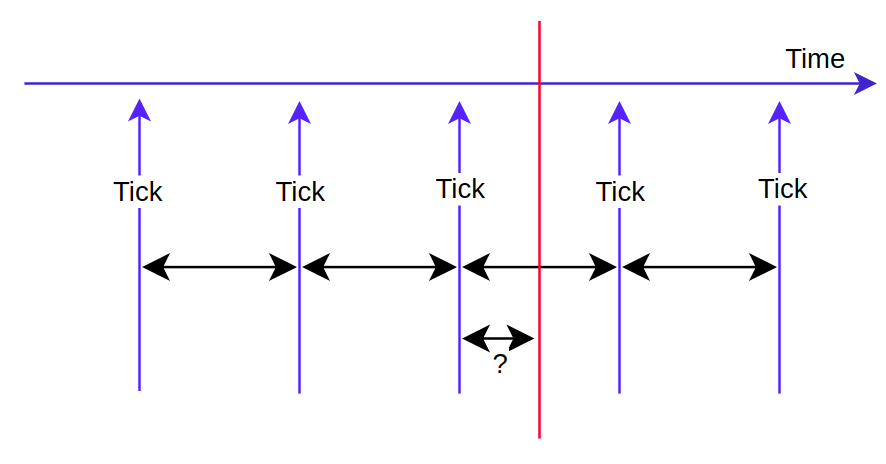
" 리눅스의 시간 계산은 `tick` 을 기반으로 한다. 그런데, tick 은 연속적인 값이 아닌, `이산적인` 값이다. 즉, 리눅스에서 `tick(이산적인 값)` 을 통해 정확한 시간(연속적인 값) 을 알기 위해서는 `특별한 연산` 이 필요하게 된다. 이 계산은 2 가지가 필요하다.
1. 현재 시점을 기준으로 바로 직전 tick 발생 시간(last tick)
2. 현재 cycle coutner" 위의 2가지 내용을 통해 `현재 시간 = 바로 직전 tick + 현재 cycle counter` 을 구할 수 있다. 그런데, 문제가 하나 있다. `사용자가 현재 시간을 요청한 지점`을 알기 위해서는 하드웨어에 접근해야 한다. 왜냐면, 현재 시간과 `tick` 을 기반으로 동작하기 때문에, 딱 `tick` 이 발생한 시점을 기준으로 시간을 구할 수 는 있지만, `tick` 이 발생하지 않은 곳에서의 시간은 하드웨어에 접근해서 주파수가 얼마나 발생했는지를 파악해야 한다. 예를 들어, `HZ == 100` 이라고 가정하면, `tick`의 주기가 10ms가 된다. 아래의 그림에서 빨간선(`사용자가 현재 시간을 요청한 지점`)에서 주파수가 50 번 발생했다고 치자. 그렇면, `tick` 의 주기인 10ms 의 절반인 5ms 가 된다. 그렇면, `바로 직전 tick 발생 시간`은 2 시 42 분 12 초 라고 해보자. 그렇다면, 빨간선의 시간은 `2시 42분 12초 + 0.5ms`가 된다.
" 그러나, 대부분의 경우 정교한 시간(`find-grained`)을 요구하는 경우는 많지 않다. 그래서, 사용자가 현재 시간을 요청하면 바로 직전 tick 값을 반환하는 경우가 많다. 즉, 퍼포먼스를 위해서 대략적인 시간(`coarse-grained`)을 반환하는 것이다(하드웨어에 접근할 필요없으므로, 속도가 빠름).
4. How to wake-up system in sleep state ?
" 5초 뒤에 타이머가 예약되어 있다고 치자. 그런데, 5 초가 되기전에 시스템이 sleep 에 들어가면 어떻게 될까? 이와 같은 경우, 일반적인 타이머 디바이스들은 모두 Off 된다. 즉, 5 초 뒤에 타이머가 실행되지 않는다는 소리다. 이럴 때, 어떻게 하면 sleep 상태에서도 타이머를 실행할 수 있을까? 이럴 때는, 시스템 sleep 상태에서도 Off 되지 않는 별도의 타이머가 반드시 필요하다. 일반적으로, 시스템 sleep 상태에서도 Always-on 으로 동작하는 타이머를 `시스템 글로벌 타이머` 혹은 `SoC 타이머` 라고 부른다. 그리고, 특별한 경우에는 `브로드 캐스트 타이머` 라고도 부른다.
- Convert clock cycle to nano-second in linux
" 현재 시간을 nano-second 단위로 얻기 위해서는 어떻게 해야 할까? 먼저, clock source 의 카운트 레지스터를 읽어 counter 값을 알아내야 한다. 그리고, clock source 가 1초 동안에 발생한 주파수로 나누면 된다. 그런데, 이 값은 단위는 1초이기 때문에, ns 의 단위인 1,000,000,000 으로 다시 나눠야 한다. 이 섹션에서는 리눅스 커널이 이 과정을 어떻게 계산하는지 알아본다.
1. Basic knowledge for calculation
" 계산을 들어가기전에 몇 가지 기본지식이 필요하다. 거듭제곱의 성질에서 `지수의 덧셈`을 어떻게 했는지 떠올려보자. 쉽게 2개의 수를 곱하면 지수를 더하는 것과 같다. 예를 들어, 아래와 같다.
1. 2^3 * 2^4 = 2^7
2. (2^3 * 3^2) * 3^3 = 2^3 * 3^5
3. 2^36 * 2^28 = 2^64" 만약, `2^32 * X = Y , Y > 2^64` 라면, X는 대략 어느정도의 값을 가질까? 확실한 건 2^32 보다 크다는 것을 알 수 있다. 그리고, 프로그래밍에서 사용하는 레지스터 크기는 32, 64비트라는 것도 기억해놓자.
" 컴퓨터에서 시간이 얼마나 흘렀는지를 알기 위해서는 현재 초당 주파수(1초당 발생하는 cycle 횟수)와 현재 system counter 에서 카운트 레지스터의 값을 알아야 한다. 즉, `Cycle(현재까지 발생한 사이클 횟수) / Frequency(초당 발생하는 사이클 횟수)` 를 통해서 현재 몇 초가 흘렀는지를 알 수 있다. 예를 들어, 카운트 레지스터 = 3823 이고, freq = 100 이라면, 38.23 초가 흘렀다는 것을 알 수 있다. 여기까지가 clock frequency 를 time 으로 바꾸는 방법에 대해 알아봤다. 그러나, 컴퓨터에서는 `sec` 보다는 너무 느리다. 최소 `ms` 단위 정도는 사용할 수 있어야 한다. 그리고, 더 정교한 타이머가 필요한 서비스들에서는 `ns` 까지도 요구한다. 그렇면, `Cycle / Frequency` 의 결과에 다시 nano-second 단위로 나누면 될 듯 싶다.
1. ms 단위를 원한다 -> `38.23s` 를 `ms` 단위로 바꾸기 위해 1,000 으로 나눈다(1ms 를 1,000번 더해야 1s 가 됨) -> 0.03823ms
2. ns 단위를 원한다 -> `38.23s` 를 `ns` 단위로 바꾸기 위해 1,000,000,000 으로 나눈다(1ns 를 1,000,000,000 더해야 1s 가 됨). -> 0.00000003823ns" 그런데, 일부 시스템에서 소수 연산을 지원해주는 물리적인 장치가 없을 수 도 있다. 그리고, 소수 연산은 하드웨어에 접근해야 하고, 시간도 오래 걸린다. 결국, 퍼포먼스 이슈가 발생한다는 것이다.
" 그래서, 소수를 사용하지 않기 위해 나눗셈을 사용하지 않는다. 대신 특정값을 곱해서 더 작은수를 표현한다. 예를 들어, 위에 38.23 에 1,000을 곱한 다음에 단위를 sec 가 아닌 msec 라고 설명하는 것이다. 그렇면, 38230 을 보고 많은 개발자들은 ms 단위라고 만드는 것이다. 이걸 초로 바꾸기 위해서는 오히려 1,000 으로 나눠야 한다. 그리고, 이렇게 곱셈을 이용하면 정수형으로 굉장히 작은 수 까지도 표현이 가능해진다. 예를 들어, `초` 로 표현된 시간에 ns 를 표현하기 위해서 1,000,000,000 을 곱하면 된다.
주의점은 이렇게 소수를 정수로 사용할 때는 변수명에 접두사 혹은 접미사에 ms, us, ns 등을 명시한다. 예를 들어, max_idle_ns = 192839023002 라고 하면, ns 단위라고 생각하면 된다. 이걸 초로 바꾸려면 1,000,000,000 으로 나누면 된다.
" 또 위에 과정을 봐서 알겠지만, 큰 값을 곱할 수 록 더 작은 단위 시간, 즉, 더 정확한 시간을 표현할 수 있다. 예를 들어, 1,000 를 곱하는 것보다 1,000,000,000 를 곱하는 것이 더 정확한 시간을 표현할 수 있다.
2. Linux calculation
" 위에 내용을 바탕으로 리눅스 커널에서는 어떻게 clock frequency 를 time 으로 바꾸는지 알아보자.
The clock source struct shall provide means to translate the provided counter into a nanosecond value as an unsigned long long (unsigned 64 bit) number. Since this operation may be invoked very often, doing this in a strict mathematical sense is not desirable: instead the number is taken as close as possible to a nanosecond value using only the arithmetic operations multiply and shift, so in clocksource_cyc2ns() you find:
ns ~= (clocksource * mult) >> shift
- 참고 : https://www.kernel.org/doc/Documentation/timers/timekeeping.txt" 위에서 ns 가 nano-second 를 의미하고, clocksource 는 clock frequency 를 의미한다. 그렇다면, mult 와 shift 의 정체는 뭘까? 위에서 우리는 clock frequency -> time 으로 변환되는 과정을 확인했다. 공식으로 하면 다음과 같다. 참고로, ns 로 변환한다고 가정하자.
ns = ( cycles / Frequency ) * NSEC_PER_SEC
" 그런데, 잘 보니 Frequency 와 NSEC_PER_SEC 가 고정값이다 보니, 매번 연산할 필요가 없다. 즉, NSEC_PER_SEC / Frequency 를 미리 계산해서 실제 변수인 cycle 만 곱하면 더 좋은 퍼포먼스가 나올 것 같다. 그래서 아래와 같이 식이 변경된다.
ns = cycles * ( NSEC_PER_SEC / Frequency ) = cycles * C
" 그런, 위에 식에는 큰 문제가 있다.
`NSEC_PER_SEC / Frequency` 연산 과정에서 소수가 발생해서 버려질 경우, 정확도가 매우 떨어질 수 있다.
" 예를 들어, freq 를 344,000,000 이라고 가정하자. 그러면, C = 1,000,000,000 / 344,000,000 = 2.906976744 이 된다. 그리고, cycle = 125,338 이라고 해보자. 그렇면, ns = 125,338 * 2.906976744 = 364354.6511 가 된다. 그런데, 리눅스 커널은 소수점 연산을 사용하지 않는다. 그렇기 때문에, C 는 내림이 되서 2가 된다. 즉, ns = 125,338 * 2 = 250676 가 된다. 정확도가 너무 낮아져버린다.
" 방법이 있다. 미리 계산을 하지 않는 것이다. 즉, 아래와 같이 식을 변경한다. 아래와 같이 연산의 순서만 변경해도, 364354.6512 가 정확하게 맞아떨어진다. 그런데, 리눅스 커널은 아래 연산이 빈번히 수행되며 나눗셈 연산이 포함되었다는 점을 토대로 최적화를 진행한다.
ns = ( cycles * NSEC_PER_SEC ) / Frequency
" 리눅스 커널은 `( NSEC_PER_SEC / Frequency )` 연산을 미리 계산해놓으면서 정확도도 ( cycles * NSEC_PER_SEC ) / Frequency 순서로 연산할 때와 비슷하면서, 나눗셈을 없앰으로써 퍼포먼스가 증가시킬 수 있는 방법을 생각해낸다.
- `NSEC_PER_SEC / Frequency` 를 수행하기 전에 NSEC_PER_SEC 에 특정한 값을 곱해서 정확도를 올린다.
" 예를 들어, 1,000,000 을 곱할 경우 2906976.744 가 나온다. 소수점을 버리면, 2,906,976 이 된다. 이전 결과인 `2` 에 비해 상당히 정확도가 올라갔다. 이 값을 cycles 에 곱하면, X = 125,338 * 2,906,976 = 364354.558 * 10^6 이 된다. 그런데, 이 값은 ns 초로 환산한 값이 아니다. 이 값은 fs(펨토초 : 10^15)로 환산된 값이다. 왜냐면, ns 로 환산된 값에 1,000,000 을 곱했기 때문이다. 이제 정확도가 증가했으니, 다시 1,000,000 을 나눠 ns 로 환산하면, 364354.558 * 10^6 / 10^6 = 364354.558 가 된다. 이렇게, 프로그래밍에서 소수점이 발생하는 연산에서는 연산의 결과보다는 순서가 더 중요하다는 것을 알게해준다. 그렇다면, 식이 아래와 같이 수정된다.
1. 양변에 특정한 수(C)를 곱함. 이 때, 중요한 건 프로그래밍 특성상 반드시 C는 NSEC_PER_SEC 에 곱해져야 한다.
" ns * C = ( cycles * NSEC_PER_SEC * C ) / Frequency
2. ns 로 환산하기 위해 왼쪽은 ns 만 남겨놓아야 한다.
" ns = (( cycles * NSEC_PER_SEC * C ) / Frequency ) / C" 여기서 또 중요한 점은 곱해지는 수 가 클수록 소수점은 더 뒤로가게 된다. 즉, 표현할 수 있는 수가 더 커지게 되고, 정확도가 그 만큼 증가한다. 그런데, 현대의 컴퓨터에서는 표현할 수 있는 수가 64비트가 한계다. 이 때문에 곱해지는 수에는 한계가 있다. 어떻게 해야 할까? 일반적으로는 10을 곱하겠지만, 이건 인간에게 편한 10진수 체계로 했을 때이다. 컴퓨터에서는 10의 거듭제곱을 곱할 경우, 64비트를 넘는지를 체크하기가 복잡해진다. 왜냐면, 컴퓨터가 이진수 체계를 따르고 있기 때문이다. 그렇다면, 1823 에 10의 거듭제곱을 곱할때 와 2의 거듭제곱을 곱할 때 어떤 차이가 있을까?
0. 기준값 : 1823 = 0000 0000 0111 0001 1111
1. 10의 거듭제곱
- 1823*10 = 0000 0000 0100 0111 0011 0110
- 1823*100 = 0000 0010 1100 1000 0001 1100
- 1823*1000 = 0001 1011 1101 0001 0001 1000
2. 2의 거듭제곱
- 1823*4 = 0000 0001 1100 0111 1100
- 1823*8 = 0000 0011 1000 1111 1000
- 1823*16 = 0000 0111 0001 1111 0000
- 1823*32 = 0000 1110 0011 1110 0000
- 1823*64 = 0001 1100 0111 1100 0000
- 1823*128 = 0011 1000 1111 1000 0000" 위에서 볼 수 있다시피 2의 거듭제곱을 사용할 경우, 규칙성이 있기 때문에 64비트 오버플로우를 간편하게 검사할 수 있다. 그리고, 곱해지는 수가 클 수록 정확도가 올라간다고 했다. 그렇기 때문에, 10의 거듭제곱으로 증가하는 것보다는 2의 거듭제곱으로 증가하는 것이 64비트에 딱맞게 증가시킬 수 있다. 사실, 2의 거듭제곱을 제외하고는 마지막 64번째 비트를 컨트롤하는 것이 쉽지 않다. 그런데, 2의 거듭제곱은 왼쪽 쉬프트와 동일하기 때문에 64번째 비트를 완벽하게 컨트롤할 수 있다는 장점이있다. 이렇게, 곱해지는 수를 2의 거듭제곱으로 변경해보자.
- `ns = (( cycles * NSEC_PER_SEC * 2^n ) / Frequency ) / 2^n`
or
- `ns = (( cycles * ( NSEC_PER_SEC << n )) / Frequency ) >> n`" 포퍼먼스를 위해서 값이 변하지 않는 고정값들은 미리 계산해놔야 한다. 아래와 같이 묶을 수 있다.
- ns = ( cycles * (( NSEC_PER_SEC << n ) / Frequency )) >> n
==> ns = (cycles * mult) >> n" mult 는 (( NSEC_PER_SEC << n ) / Frequency ) 를 의미한다. 이로써 리눅스 커널에서 `clock frequency to time` 변환식에 대해 알아봤다.
- The different clocks in linux kernel [참고1 참고2]
1. linux kernel system clocks
" 시간을 측정하기 위해서는 2 가지 요소를 정의해야 한다. 바로, `단위(unit)` 와 `특정 시점(reference point)` 이다. 예를 들어, 현재가 2 시 35 분 28 초 라는 것을 알기 위해서는 초, 분, 시 라는 시간의 단위를 정의해야 하고, `어떤 기준으로 현재가 2 시 35 분 28 초 라고 말할 수 있는가?` 에 대해 정의하려면, `특정 시점` 을 잡아야 한다. 리눅스 커널에서 사용하는 reference point 는 `Linux Epoch` 라고 한다. 이 값은 `1970-01-01 00:00:00 (UTC)` 로 정의되어 있다.
1. unit of time measurement
2. reference time point" 컴퓨터는 사람과 다르게 `년, 달, 주, 일` 등의 표현을 이해할 수 없다. 단지 숫자만을 사용해서 Linux epoch 를 기준으로 현재 시점까지 몇 초가 흘렀는지를 나타낸다. 그리고, POSIX-compatible systems 들은(예를 들면, 리눅스) 반드시 초 단위 이하까지도 측정 가능한 정밀도를 갖는 system clock 을 제공해야 한다.
" 리눅스 커널에서 제공하는 다양한 system clocks 들은 아래오 같다. CLOCK_PROCESS_CPUTIME_ID / CLOCK_THREAD_CPUTIME_ID 시간은 per-process / per-thread 로 사용되지만, 나머지 system clocks 들은 시스템 레벨에서 사용된다( `CLOCK_PROCESS_CPUTIME_ID` / `CLOCK_THREAD_CPUTIME_ID` 는 프로세스 & 스레드의 실행 시간을 측정하는데 사용된다(퍼포먼스 분석을 위해)). *_COARSE ID 를 제외하곤(jiffies 기반), 나머지 모두 resolution 은 ns 를 기반으로 한다.
// include/uapi/linux/time.h - v6.5 /* * The IDs of the various system clocks (for POSIX.1b interval timers): */ #define CLOCK_REALTIME 0 #define CLOCK_MONOTONIC 1 #define CLOCK_PROCESS_CPUTIME_ID 2 #define CLOCK_THREAD_CPUTIME_ID 3 #define CLOCK_MONOTONIC_RAW 4 #define CLOCK_REALTIME_COARSE 5 #define CLOCK_MONOTONIC_COARSE 6 #define CLOCK_BOOTTIME 7 #define CLOCK_REALTIME_ALARM 8 #define CLOCK_BOOTTIME_ALARM 91. CLOCK_REALTIME : 이 ID를 갖는 시간은 실제 세상과 동일한 시간을 갖는다는 것을 의미한다. 일반적으로, RTC에 의해 시간이 관리된다. 그러나, RTC의 수명에 대한 제약도 있을 뿐만 아니라, 시간이 지남에 따라 오차도 발생하게 된다. 그래서, 시스템 관리자는 NTP(`Network Time Protocol`)을 통해서 시스템 시간을 실제 세계 시간과 동기화할 수 있다. 즉, 이 id를 갖는 시간의 특성은 `시간 조정`이 가능하다.
2. CLOCK_MONOTONIC : 이 시간도 CLOCK_REALTIME 과 마찬가지로 real world clock 을 나타낸다. 그러나, 직접적인 시간 조정은 불가능하다.
이 ID 를 갖는 시간은 시스템이 부팅하고 나서 얼마나 시간이 지났는지를 나타낸다. 이 시간은 `jiffies` 를 기반으로 계산된다. 왜 `jiffies` 를 기반으로 계산할까? 리눅스 커널에서 `jiffies`가 `monotonic` 하게 증가하기 때문이다. 일반적으로 가장 많이 사용되는 `clock id` 이며, 두 이벤트간의 시간 차이를 계산하는데 주로 사용된다(부팅 타임 시간 측정도 결국 두 이벤트간에 시간 차이다). 그리고, 시스템이 `suspend` 상태일 때, 이 시간 또한 일시 중지된다.
: 그리고, 이 시간은 시스템 관리자에 의해 초기화가 될 수 도 있다(`jiffies` 오버플로우). 그리고, 이 값은 `NTP time adjustments`로 인해서 값이 변경않는다. 그러나 주파수가 바뀔 수 있다. 예를 들어, NTP가 `local oscillator`와 `upstream server` 사이에 주파수 싱크가 맞지 않을 수 있다[참고1 참고2].
3. CLOCK_PROCESS_CPUTIME_ID : 프로세스의 실행 시간을 기록할 때 사용한다. 즉, 프로세스가 TASK_RUNNING 일 때만 기록된다.
4. CLOCK_THREAD_CPUTIME_ID : 스레드의 실행 시간을 기록할 때 사용한다. 즉, 스레드가 TASK_RUNNING 일 때만 기록된다.
5. CLOCK_MONOTONIC_RAW : 이 ID를 갖는 시간은 기본적으로 `CLOCK_MONOTONIC`과 동일하지만, NTP에 영향을 받지 않는다[참고1].
6. CLOCK_REALTIME_COARSE : 이 ID를 갖는 시간은 기본적으로 `CLOCK_REALTIME`과 동일하지만, 정교한 시간이 아닌 대략적인 시간(`corase-grained`)을 반환한다. 즉, 다른 CLOCK ID 와는 다르게 resolution 이 tick 을 기반으로 한다.
7. CLOCK_MONOTONIC_COARSE : 이 ID를 갖는 시간은 기본적으로 `CLOCK_MONOTONIC`과 동일하지만, 정교한 시간이 아닌 대략적인 시간(`corase-grained`)을 반환한다. 즉, 다른 CLOCK ID 와는 다르게 resolution 이 tick 을 기반으로 한다.
8. CLOCK_BOOTTIME : 이 ID를 갖는 시간은 기본적으로 `CLOCK_MONOTONIC`과 동일하지만, `suspend` 상태에서도 이 시간은 계속 측정된다. `CLOCK_MONOTONIC` id를 갖는 시간은 `suspend` 상태에서는 측정되지 않는다.
9. CLOCK_REALTIME_ALARM : 이 ID를 갖는 시간은 기본적으로 `CLOCK_REALTIME`과 동일하지만,
`suspend` 상태에서도 이 시간은 계속 측정된다. 이름에서 봐도 알겠지만, 타이머의 시간을 설정할 때 사용된다.
10. CLOCK_BOOTTIME_ALARM : 이 ID를 갖는 시간은 기본적으로 `CLOCK_BOOTTIME`과 동일하지만, `suspend` 상태에서도 이 시간은 계속 측정된다. 이름에서 봐도 알겠지만, 타이머의 시간을 설정할 때 사용된다.2. Broken-down Time [참고1]
" 컴퓨터가 같은 경우는 특정 시간을 표현하기 위해 Linux epoch 를 기준으로 현재까지 시간이 얼마나 흘렀는지를 `초` 단위로 표현할 수 있다. 그러나, 인간에게 현재 시간을 linux epoch 를 기준으로 얼마나 흘렀는지를 초로 보여주면, 상당히 난감하다. 예를 들어, shell 에서 `date +%s` 를 치면, 1970-01-01 00:00 UT 를 기준으로 현재 얼마나 시간이 흘렀는지를 나타낸다. 그러나, 아래에서 볼 수 있다시피, 이 값은 인간이 직관적으로 알아볼 수 있는 시간이 아니다.
$ date +%s 1704017356" `Broken-down Time` 이란, 위와 같이 시간(Ex. 1704017356) 이 컴퓨터만이 인식할 수 있는 binary representation 으로 표현될 때, 이 값을 인간이 알아볼 수 있는 `년, 월, 일 등` 으로 구분하는 것을 의미한다. 리눅스 커널에서는 Broken-down time 을 표현하기 위한 구조체로 struct tm 을 사용한다. 주석에 설명이 구체적으로 잘 되어있기 때문에 자세한 설명은 생략한다.
// include/linux/time.h - v3.17 /* * Similar to the struct tm in userspace <time.h>, but it needs to be here so * that the kernel source is self contained. */ struct tm { /* * the number of seconds after the minute, normally in the range * 0 to 59, but can be up to 60 to allow for leap seconds */ int tm_sec; /* the number of minutes after the hour, in the range 0 to 59*/ int tm_min; /* the number of hours past midnight, in the range 0 to 23 */ int tm_hour; /* the day of the month, in the range 1 to 31 */ int tm_mday; /* the number of months since January, in the range 0 to 11 */ int tm_mon; /* the number of years since 1900 */ long tm_year; /* the number of days since Sunday, in the range 0 to 6 */ int tm_wday; /* the number of days since January 1, in the range 0 to 365 */ int tm_yday; };3. The differenet time precisions(second, micro-seconds and nano-seconds)
" UNIX 에서 전통적으로 사용되던 시간 단위는 `초` 였다. 그리고, 이와 관련된 구조체로 time_t 가 있다. time_t 는 POSIX 표준에 의해 정의된 구조체로 초단위의 시간을 저장한다. 아래에서 볼 수 있다시피, 32-bit architecture 에서는 time_t 가 long 으로 re-define 되기 때문에 2038 년 되면(Linux epoch 를 기준으로), overflow 가 발생한다.
// include/uapi/asm-generic/posix_types.h - v3.14 typedef long __kernel_long_t; .... typedef __kernel_long_t __kernel_time_t;// include/linux/types.h - v3.17 #ifndef _TIME_T #define _TIME_T typedef __kernel_time_t time_t; #endif" timer service 가 필요할 때, 초 단위가 필요한 경우도 있지만, 350us 와 같은 micro-seconds 단위까지도 필요한 경우도 상당히 많다(Ex. device boot-up sequence 에 따라 350us 뒤에 LDOx 를 On 하고, 다시 250us 뒤에 LDOn 을 On 해야 하는 경우가 있음). 이럴 때는, time_t 구조체 만으로는 micro-seconds 를 표현할 수 없다. 그래서 struct timeval 구조체가 등장했다.
// include/uapi/linux/time.h - v3.14 struct timeval { __kernel_time_t tv_sec; /* seconds */ __kernel_suseconds_t tv_usec; /* microseconds */ };" struct timeval 구조체는 tv_sec 필드만 보면 time_t 와 유사하지만, micro-seconds 를 표현하는 추가 필드가 있다(tv_usec). 만약, Linux epoch 부터 현재 시점까지의 micro-seconds 를 구해야 한다면, `tv_sec * 10^6 + tv_usec` 로 구하면 된다. 그러나, micro-seconds 만으로 부족한 경우가 있다. 예를 들어, real-time application 은 nano-seconds 단위의 정밀도를 요구하는 경우가 많다. 그래서, POSIX 표준은 또한 nano-seconds 단위의 정밀도를 구현할 수 있는 struct timespec 구조체를 제공한다.
// include/uapi/linux/time.h - v3.17 #ifndef _STRUCT_TIMESPEC #define _STRUCT_TIMESPEC struct timespec { __kernel_time_t tv_sec; /* seconds */ long tv_nsec; /* nanoseconds */ }; #endif" timespec.tv_sec 값이 valid 하려면, 0 보다 크거나 같아야한다. timespec.tv_nsec 값이 valid 하려면, 0 보다 크거나 같아야 하며, 10^9(NSEC_PER_SEC) 보다 작아야 한다.
'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] LDM - uevent (0) 2023.10.03 [리눅스 커널] Timer - timekeeping (0) 2023.10.03 [리눅스 커널] Timer - high resolution timer (0) 2023.09.30 [리눅스 커널] Timer - tick layer (0) 2023.09.28 [리눅스 커널] Timer - clock event device (0) 2023.09.25