-
[리눅스 커널] LDM - kobj_type & sysfs & kernfsLinux/kernel 2023. 9. 23. 16:26
글의 참고
- https://blog.csdn.net/sinat_32960911/article/details/128382773
- https://zhuanlan.zhihu.com/p/531355852
- http://www.wowotech.net/device_model/dm_sysfs.html
- https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=b8441ed279bff09a0a5ddeacf8f4087d2fb424ca
- https://blog.csdn.net/sinat_32960911/article/details/128582089
글의 전제
- 밑줄로 작성된 글은 강조 표시를 의미한다.
- 그림 출처는 항시 그림 아래에 표시했다.
글의 내용
- Overview
" `sysfs`는 RAM-based 파일 시스템이다. sysfs에서는 3가지 내용을 살펴본다.
1. sysfs 와 kobject 의 관계
2. attribute 개념
3. sysfs operation 란" 위에 글들에서 반복해서 언급했던 내용이 있다. 바로 `kobj는 sysfs 의 폴더와 대응`된다고 했다. 즉, `kobj` 하나가 추가될 때 마다, sysfs에 디렉토리 하나가 생성된다는 소리다.
" sysfs 관련 동작(read/write)도 마찬가지다. sysfs 에서 read / write 동작은 `attribute` 에서 이루어진다. 왜냐면, attribute 가 `파일`로 표현되기 때문이다. 그렇다면, kobject 는 동작이 없나? 있긴 있다. 그러나, 구체적인 동작이기 보다는 다수에게 적용되는 공통(범용)적인 동작을 kobject 에서 수행하게 된다. 왜냐면, kobject 가 `폴더`로 표현되기 때문이다.
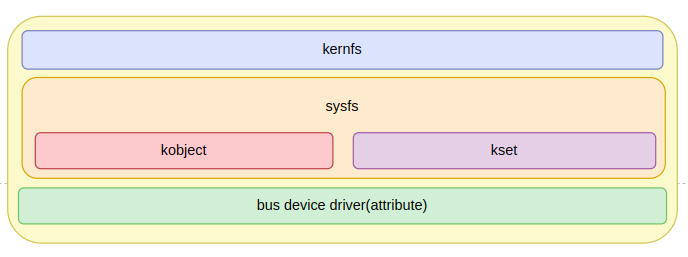
" sysfs / kernfs 를 알아보기 전에 전체 큰 그림을 알고가자. 위쪽에 있을 수 록 high-level 에 가깝고, 아래에 있을 수 록 low-level 이다. 아래 구조에서 sysfs 파일을 하나 생성하면, sysfs -> kernfs -> vfs 순으로 호출되면서 파일이 하나 만들어진다. 물론, sysfs 가 RAM-based 파일 시스템이기 때문에, VFS 에서 디스크에 해당 파일의 내용을 쓰지는 않을 것이다. 반대로, sysfs 파일에 유저가 `cat 혹은 echo` 명령어를 실행할 경우, vfs -> kernfs -> sysfs 순으로 호출되면서 해당 파일에 명령이 실행된다. 이 글에서 2가지 내용을 알아볼 것이다.
1. 파일 생성
2. 파일 읽고 쓰기" VFS 는 이 글에서 다루지 않는다. 이 글에서는 파일 생성 및 읽고 쓸 때, sysfs & kernfs 가 어떻게 연동되는지에 대해 알아볼 것이다.
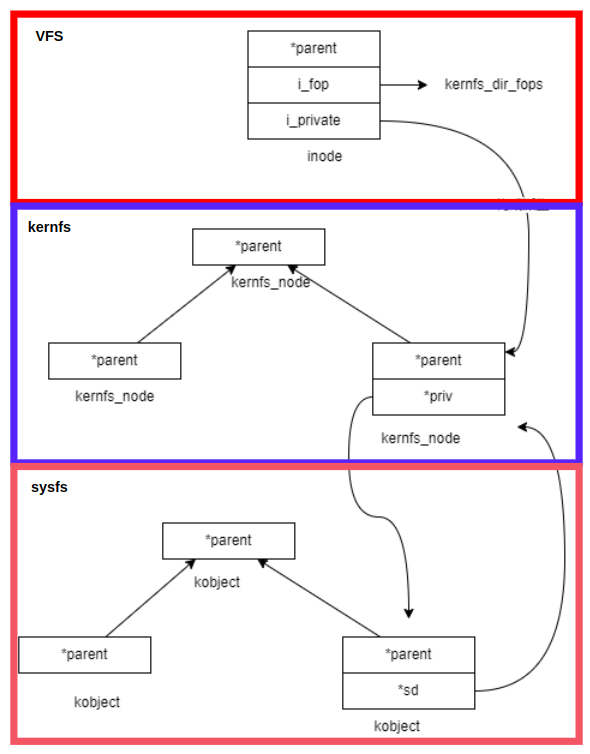
https://www.cnblogs.com/yangxinrui/p/16951751.html- Attribute
" sysfs 에서 `attribute`은 어떤 개념일까? 위에서 말했다싶이, sysfs에서 kobject는 폴더에 대응한다. 그렇다면, attribute는 sysfs에서 무엇에 대응할까? sysfs는 파일 시스템이다. 파일 시스템은 `폴더`와 `파일`로 구성되어 있다. 앞에서 폴더가 kobject 라고 했으니, attribute는 파일이 된다는 것을 추측할 수 있을 것이다. sysfs 에서 폴더와 파일은 하나의 객체를 나타낸다. 예를 들어, 디바이스 및 버스 등은 sysfs 에서 폴더 및 파일로 표현할 수 있다. 그리고, sysfs 에서 폴더 및 파일을 모두 `상태`와 `동작`을 갖는다. 여기서는 파일만 논한다고 했을 때, sysfs 에서 파일의 상태는 attribute 가 표현해준다. 그렇다면, 동작은 어떻게 나타낼까? 바로 `show / store` 함수들이 `동작`을 나타낸다.
- sysfs 파일 상태 : struct attribute
- sysfs 파일 동작 : show / store 계열 함수" attribute 는 sysfs 에서 파일의 상태를 나타난다고 했다. 그래서 기본적으로 이름, 접근 권한 등 파일을 표현할 수 있는 정보들을 가지고 있다. 유저 레벨에서 attribute 를 읽거나 씀으로써 파일의 동작인 show / store 함수들이 호출된다. attribute 의 특징을 정리하면 다음과 같다.
1. attribute 는 커널 스페이스와 유저 스페이스가 통신할 수 있는 방법을 제공한다.
2. attribute 는 파일의 상태를 나타낸다.
3. attribute 를 통해 드라이버를 제어할 수 있다." 리눅스 커널에서는 2가지 attribute가 존재한다.
1. struct attribute : 이 구조체를 통해 만들어진 sysfs 파일은 문자열만 읽고 쓸 수 있다. 거의 대부분은 이 구조체를 사용한다. 그리고, 이 구조체 또한 kobject 와 마찬가지로 단독적으로 사용되기 보다는 다른 구조체에 내장되어 사용된다.
2. struct bin_attribute : 바이너리 데이터를 사용하기 위한 구조체다. 속도는 빠르지만, 특정 용도로만 사용된다. 즉, 거의 사용되지 않는다." 위에서도 말했다싶이 `struct attribute` 구조체 자체만으로는 큰 의미가 없다. kobject 와 같이 다른 구조체에 내장되어 사용된다. `name`은 sysfs 에 파일로 등륵될 때, 이름을 나타낸다. `mode`는 파일 액세스 권한(8진수)를 나타낸다.
//include/linux/sysfs.h - v6.5 struct attribute { const char *name; umode_t mode; #ifdef CONFIG_DEBUG_LOCK_ALLOC bool ignore_lockdep:1; struct lock_class_key *key; struct lock_class_key skey; #endif };" `struct bin_attribute` 구조체는 사이즈가 큰 바이너리 데이터를 다룰 때 사용된다. 이 구조체는 sysfs 를 통해서 펌웨어 이미지를 업로드하려고 할 때, 사용된다고 한다[참고1]. 그리고, PCI config space 영역을 sysfs 파일로 할당하는 것 같다. 이 때, bin_attribute 를 사용한다고 한다[참고1 참고2].
// include/linux/sysfs.h - v6.5 struct bin_attribute { struct attribute attr; size_t size; void *private; struct address_space *(*f_mapping)(void); ssize_t (*read)(struct file *, struct kobject *, struct bin_attribute *, char *, loff_t, size_t); ssize_t (*write)(struct file *, struct kobject *, struct bin_attribute *, char *, loff_t, size_t); int (*mmap)(struct file *, struct kobject *, struct bin_attribute *attr, struct vm_area_struct *vma); };" `struct kobj_type` 은 kobject 의 동작을 표현하기 위해서 사용된다. 즉, 파일이 아닌 폴더에 적용되는 `동작`을 의미한다. 그런데, 폴더를 read / write 할 때, `동작`이 수행될 텐데 폴더를 read / write 한다는게 어떤 의미일까? 리눅스 커널에서 kobject 의 동작(kobj_type)은 자식들에게 공통으로 적용되는 동작들을 정의한다. 지금은 이해가 안갈 수 도 있다. 뒤에서 다시 다루도록 한다.
// include/linux/kobject.h - v6.5 struct kobj_type { void (*release)(struct kobject *kobj); const struct sysfs_ops *sysfs_ops; const struct attribute_group **default_groups; const struct kobj_ns_type_operations *(*child_ns_type)(const struct kobject *kobj); const void *(*namespace)(const struct kobject *kobj); void (*get_ownership)(const struct kobject *kobj, kuid_t *uid, kgid_t *gid); };- release : 모든 kobject 는 자신을 release 할 수 있는 방법을 반드시 제공해야 한다. 이 내용은 이 글을 참고하도록 하자.
- sysfs_ops : 리눅스 커널에서 각 서브-시스템은 자신의 자식들에게 `공통`으로 `먼저` 적용되야 하는 동작들을 수행할 수 있다. 예를 들어, /sys/bus/i2c/devices/i2c-0 , /sys/bus/i2c/devices/i2c-1 이 있다고 가정하자. 이 때, `cat /sys/bus/i2c/devices/i2c-1` 을 입력하면, `/sys/bus/i2c/devices/ ->sysfs_ops` 가 제일 먼저 적용되고, `/sys/bus/i2c/devies/i2c-1->show` 가 그 다음으로 적용된다." `struct sysfs_ops` 는 자체적으로 서브-시스템을 새로 만들 때, 혹은 kobject 의 기본 동작을 변경하고 싶을 때, 사용하는 구조체다.
// include/linux/sysfs.h - v6.5 struct sysfs_ops { ssize_t (*show)(struct kobject *, struct attribute *, char *); ssize_t (*store)(struct kobject *, struct attribute *, const char *, size_t); };- Default operation of attribute in kset and kobject
1. default ktype in kset and kobject
" `struct kset` 구조체에는 kobj_type 필드가 없다. 왜냐면, kset 은 단지 여러 kobject 를 묶기 위한 컨테이너이기 때문이다. 실제 kset 을 움직이는 주체는 kset->kobject 다. sysfs 에서 kset 이 폴더로 나타날 수 있는 것은 kobject 덕분이다. 그러므로, struct kset 이 아닌, struct kobject 구조체안에 연산을 표현하는 `kobj_type` 필드가 있는 것이 옳다. 그렇다면, 새로운 kset 이 생성될 때 기본적으로 등록되는 ktype이 있을까? 그걸 알기 위해서는 `kset_create` 함수 내부를 살펴봐야 한다. kset 의 디폴트 ktype 은 `kset_type`을 사용한다.
// lib/kobject.c - v6.5 static const struct kobj_type kset_ktype = { .sysfs_ops = &kobj_sysfs_ops, .release = kset_release, .get_ownership = kset_get_ownership, }; static struct kset *kset_create(const char *name, const struct kset_uevent_ops *uevent_ops, struct kobject *parent_kobj) { .... kset->kobj.ktype = &kset_ktype; .... }" kset 을 생성할 때, 디폴트로 설정되는 ktype 을 확인했다. 그렇다면, kobject 를 생성할 때도 디폴트 ktype 이 설정될까? 만약, 설정되면 kset 가 동일할까? kobject 가 단독으로 생성될 때는 ktype 으로 `dynamci_kobj_ktype`을 사용한다. 그런데, kset & kobject 는 release 방식이 달라서 ktype 이 달라진 것이지, sysfs_ops 는 동일하다. 즉, 둘다 `kobj_sysfs_ops`를 기본 동작으로 사용한다.
// lib/kobject.c - v6.5 static const struct kobj_type dynamic_kobj_ktype = { .release = dynamic_kobj_release, .sysfs_ops = &kobj_sysfs_ops, }; void kobject_init(struct kobject *kobj, const struct kobj_type *ktype) { .... kobj->ktype = ktype; .... } static struct kobject *kobject_create(void) { .... kobject_init(kobj, &dynamic_kobj_ktype); .... }" `kobj_sysfs_ops` 변수는 kobj 와 kset 모두에게 설정되는 공통 ktype 이다. 그러나, 사실, 정확히 말하면 kset 도 kobj 이기 때문에 kobj 에만 적용된다고 볼 수 있다.
- kobj_attr_show : 읽기 함수. 내부적으로 kobj_attribute->show 콜백 함수를 호출한다.
- kobj_attr_store : 쓰기 함수. 내부적으로 kobj_attribute->store 콜백 함수를 호출한다.// include/linux/kobject.h - v6.5 struct kobj_attribute { struct attribute attr; ssize_t (*show)(struct kobject *kobj, struct kobj_attribute *attr, char *buf); ssize_t (*store)(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count); };// lib/kobject.c - v6.5 /* default kobject attribute operations */ static ssize_t kobj_attr_show(struct kobject *kobj, struct attribute *attr, char *buf) { struct kobj_attribute *kattr; ssize_t ret = -EIO; kattr = container_of(attr, struct kobj_attribute, attr); if (kattr->show) ret = kattr->show(kobj, kattr, buf); return ret; } static ssize_t kobj_attr_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t count) { struct kobj_attribute *kattr; ssize_t ret = -EIO; kattr = container_of(attr, struct kobj_attribute, attr); if (kattr->store) ret = kattr->store(kobj, kattr, buf, count); return ret; } const struct sysfs_ops kobj_sysfs_ops = { .show = kobj_attr_show, .store = kobj_attr_store, };" 결국, sysfs 파일을 read / wrtie 하면, 제일 먼저 kobject 에 설정된 sysfs_ops가 먼저 호출된다. 그리고, 개별 attribute 에 맞게 커스텀된 kobj_attribute 콜백 함수들이 호출된다. 왜, kobject의 sysfs_ops 가 먼저 호출될까? 공통적인 부분은 부모(서브-시스템)에서 먼저 처리하고(struct sysfs_ops) 이후에 개별적인 부분은 자식들이 처리하는 것(struct *_attribute)과 같다고 보면된다. 그런데, 뒤에서 보겠지만, sysfs operation 레이어는 sysfs_ops(kobject) 와 kobj_attribute(attribute) 2개만 있는게 아니다. 커널 레이어도 있고, 파일 시스템 레이어도 있다. 즉, 파일 시스템 레이어, 커널 레이어에서도 먼저 처리해야 할 부분들을 수행한 뒤, 뒤로 넘기는 구조를 이루고 있다. 이 내용은 뒤에서 다시 다룰 것이다.
struct kobj_type struct kobject dynamic_kobj_ktype struct kset kset_ktype 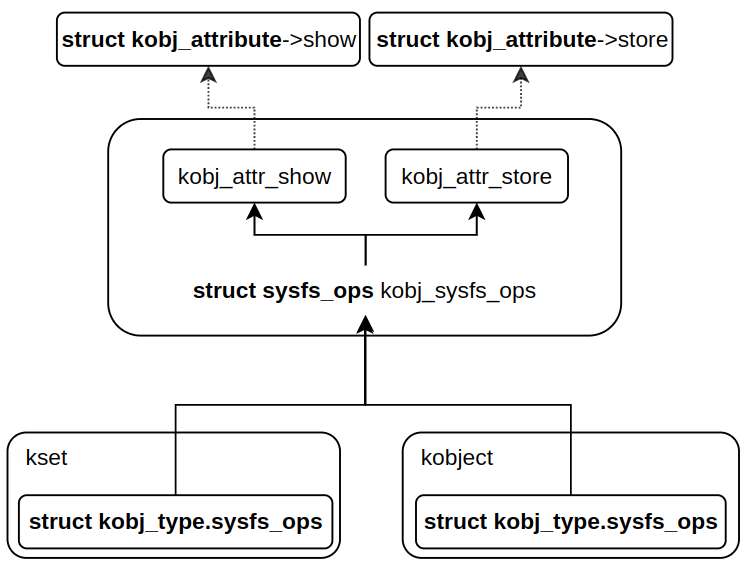
2. kobj_type in struct device
" 위에서 kobj 와 kset 을 생성할 때, 디폴트로 설정된 sysfs_ops(kobject) 와 kobj_attribute(attribute)` 는 변경이 가능하다. `/drivers/base/core.c` 파일을 보면, 리눅스 커널의 모든 디바이스(struct device)는 ktype 으로 `dev_sysfs_ops` 를 사용한다. struct device 구조체는 struct kobject 를 내장하고 있다보니, 자신만의 sysfs_ops 를 만들지 않으면, 디폴트로 kobj 나 kset 에서 사용했던 kobj_sysfs_ops 가 사용된다.
// drivers/base/core.c - v6.5 static ssize_t dev_attr_show(struct kobject *kobj, struct attribute *attr, char *buf) { struct device_attribute *dev_attr = to_dev_attr(attr); struct device *dev = kobj_to_dev(kobj); ssize_t ret = -EIO; if (dev_attr->show) ret = dev_attr->show(dev, dev_attr, buf); if (ret >= (ssize_t)PAGE_SIZE) { printk("dev_attr_show: %pS returned bad count\n", dev_attr->show); } return ret; } static ssize_t dev_attr_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t count) { struct device_attribute *dev_attr = to_dev_attr(attr); struct device *dev = kobj_to_dev(kobj); ssize_t ret = -EIO; if (dev_attr->store) ret = dev_attr->store(dev, dev_attr, buf, count); return ret; } static const struct sysfs_ops dev_sysfs_ops = { .show = dev_attr_show, .store = dev_attr_store, }; .... static const struct kobj_type device_ktype = { .... .sysfs_ops = &dev_sysfs_ops, }; void device_initialize(struct device *dev) { .... kobject_init(&dev->kobj, &device_ktype); .... } int device_register(struct device *dev) { device_initialize(dev); .... }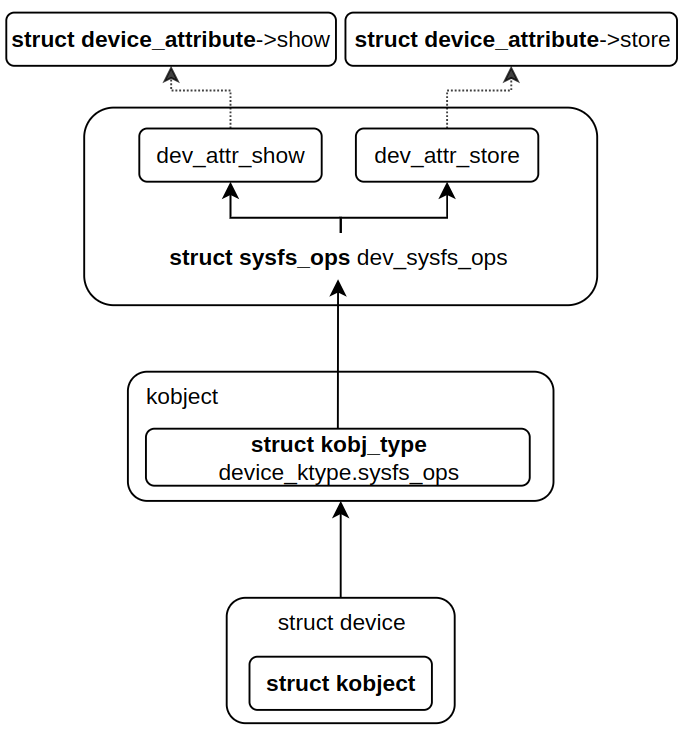
" 그렇다면, 만약에 struct device 를 내장하는 구조체들중에서 별도의 sysfs_ops 를 구현하지 않았다면 어떻게 될까? 예를 들어, 리눅스 커널 RTC 서브-시스템을 알아보자. RTC 디바이스 하나가 생성될 때, 함수 호출 관계는 아래와 같다.
1.1 devm_rtc_device_register
2.1 devm_rtc_allocate_device
3.1 rtc_allocate_device
4.1 device_initialize
2.2 __devm_rtc_register_device
3.1 cdev_device_add
4.1 device_add
5.1 device_add_attrs
6.1 device_add_groups
7.1 sysfs_create_groups" 위의 호출 관계에서 `device_add` 함수가 호출되기전에, LDM 관련 내용만 추출하면, 아래의 3가지 내용을 뽑아낼 수 있다. LDM 관련 세 가지 내용은 다음과 같다(platform device 를 통해 RTC 디바이스를 커널에 등록한다고 가정한다).
1. `rtc->dev.parent = dev(platform device 같은 `&pdev->dev` 가 전달 됨)` in devm_rtc_allocate_device
2. `rtc->dev.class = rtc_class` in rtc_allocate_device
3. `rtc->dev.groups = rtc_get_dev_attribute_groups` in rtc_allocate_device" 새로 생성된 RTC device 에게 부모 디바이스와 서브-시스템인 class 와의 관계가 생성되었다. 그러나, 아직 kobject 들 끼리의 부모-자식 관계는 형성되지 않았다. 즉, struct device 들끼리의 부모-자식 관계는 형성됬지만, 디바이스 내부에 존재하는 struct kobject 들끼리의 부모-자식 관계는 형성되지 않았다. 이 내용을 알려면, device_add 함수를 알아봐야 한다.
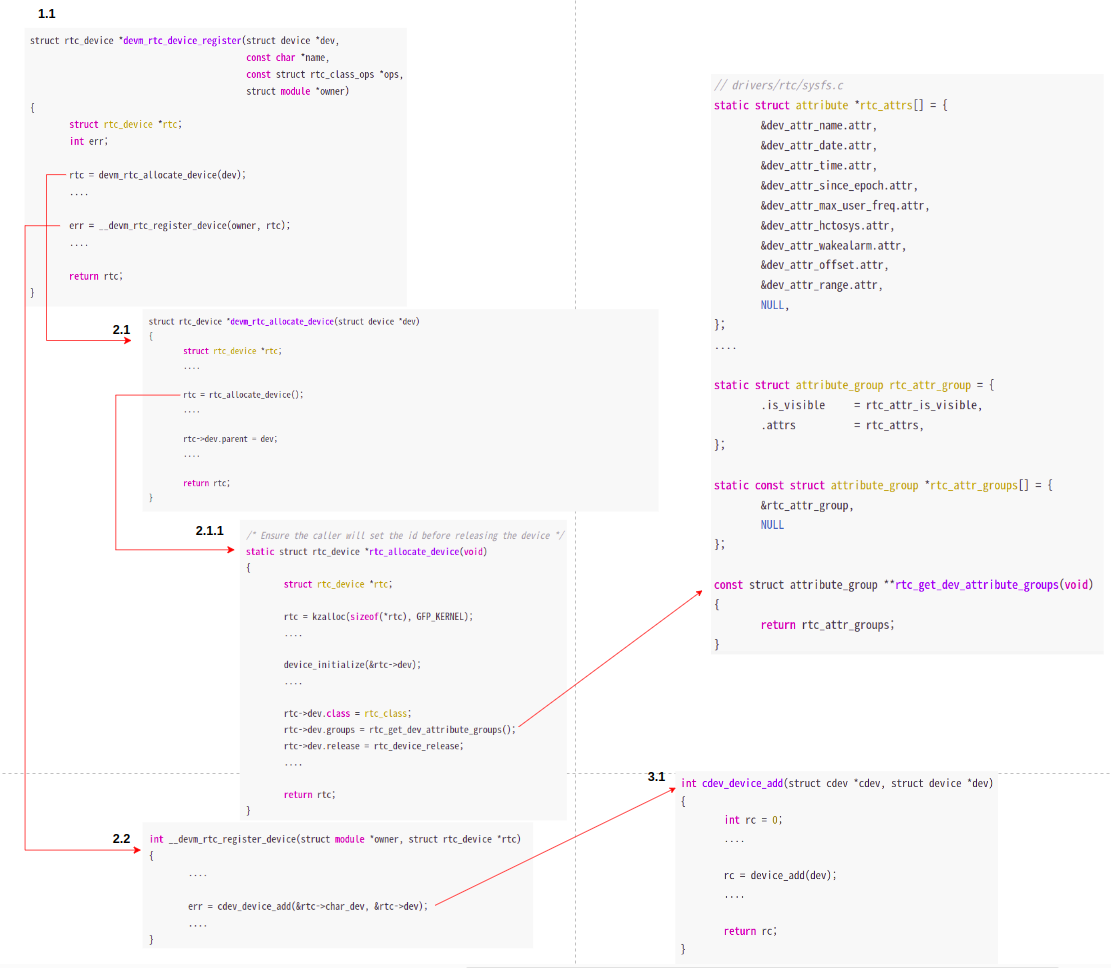
" `device_add` 함수의 자세한 내용은 이 글을 참고하자. device_add 함수는 생성 및 초기화된 디바이스를 연결시키는 작업을 수행한다. 이 때, 여러 가지 작업을 수행하는데, 제일 먼저 디바이스간의 부모-자식 관계를 통해서 그들의 kobj 들 또한 부모-자식 관계가 될 수 있는지를 검사 및 적용한다. 그 이후에, 여러 가지 작업을 수행한 뒤, device_add_attrs 함수를 호출해서 인자로 전달된 디바이스에 설정되어 있는 모든 attribute 들을 sysfs 에 등록한다.
int device_add(struct device *dev) { struct subsys_private *sp; struct device *parent; struct kobject *kobj; struct class_interface *class_intf; int error = -EINVAL; struct kobject *glue_dir = NULL; .... parent = get_device(dev->parent); kobj = get_device_parent(dev, parent); .... if (kobj) dev->kobj.parent = kobj; if (parent && (dev_to_node(dev) == NUMA_NO_NODE)) set_dev_node(dev, dev_to_node(parent)); error = kobject_add(&dev->kobj, dev->kobj.parent, NULL); .... error = device_create_file(dev, &dev_attr_uevent); .... error = device_add_class_symlinks(dev); .... error = device_add_attrs(dev); .... }" `device_add_attrs` 함수는 struct device 에 설정된 class attribute, type attribute, device attribute 를 모두 생성한다. RTC 같은 경우는 dev->class 에 `rtc_class` 전역 변수를 참조하고 있지만, rtc_class->dev_groups 은 없다. 또, dev->type 또한 존재하지 않는다. 그렇다면, dev->groups 은 있을까? 위에서 `rtc_allocate_device` 함수를 통해서 dev->groups = rtc_get_dev_attribute_groups()` 를 확인할 수 있다.
static int device_add_attrs(struct device *dev) { const struct class *class = dev->class; const struct device_type *type = dev->type; int error; if (class) { error = device_add_groups(dev, class->dev_groups); if (error) return error; } if (type) { error = device_add_groups(dev, type->groups); if (error) goto err_remove_class_groups; } error = device_add_groups(dev, dev->groups); .... return error; }" 최종적으로 sysfs_create_groups 함수를 통해 attribute 들이 생성된다. 그렇다면, 결과물은 어떻게 만들어질까?
int device_add_groups(struct device *dev, const struct attribute_group **groups) { return sysfs_create_groups(&dev->kobj, groups); }- How does kernel make sysfs files correspoding to a kobject ?
" 리눅스 커널이 어떻게 attribute 들을 sysfs 파일로 만드는지 알아보자. 그리고, 각 sysfs 파일에 operation 들이 어떻게 매핑되는지 알아본다. 분석을 위해서 먼저 sysfs 파일이 생성될 때, 함수 호출 관계는 아래와 같다.
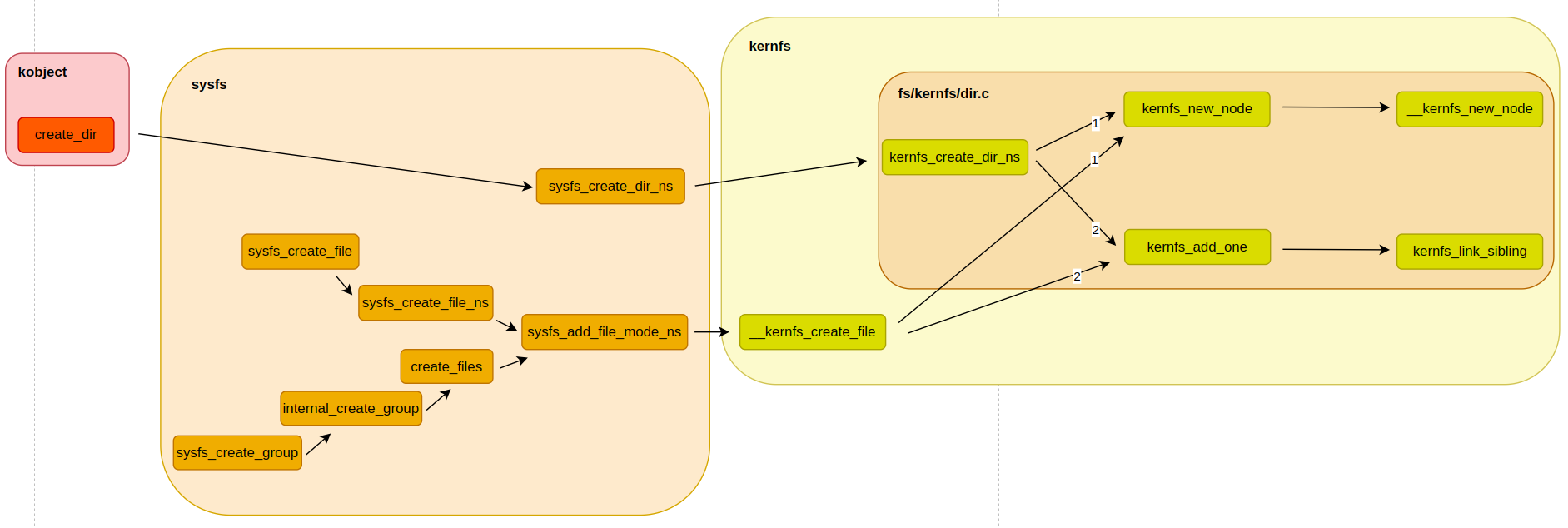
" 위 그림을 통해서 sysfs 파일을 만드는 entry function 이 `sysfs_add_file_mode_ns` 라는 것을 알 수 있다. 함수 이름에서 볼 수 있다시피, 이 함수는 새로운 kernfs_node 를 생성하는 함수가 아니다. 이 함수는 kernfs_node 를 생성하는 함수(`__kernfs_create_file`)에게 접근 권한과 같은 추가 속성들을 전달하는 역할을 한다. 실제 sysfs 파일을 생성하는 함수는 __kernfs_create_file 함수다.
// fs/sysfs/file.c - v6.5 int sysfs_add_file_mode_ns(struct kernfs_node *parent, const struct attribute *attr, umode_t mode, kuid_t uid, kgid_t gid, const void *ns) { .... const struct kernfs_ops *ops = NULL; struct kernfs_node *kn; .... kn = __kernfs_create_file(parent, attr->name, mode & 0777, uid, gid, PAGE_SIZE, ops, (void *)attr, ns, key); .... return 0; }" sysfs_create_file_ns 함수에서 sysfs_add_file_mode_ns 함수를 호출할 때, 첫 번째 인자 이름이 `parent`로 되어있다. 왜 kernfs_node 이름을 왜 parent 라고 지었을까? 위에 과정은 sysfs attribute 를 만드는 과정이다. sysfs attribute 는 파일이다. 그리고, sysfs kobject 폴더이다. 그런데, 이건 sysfs 관점에서 본것이고, kernfs 에서는 파일이건 폴더이건 모두 kernfs_node로 표현된다. kernfs_node 관점에서 폴더와 파일은 부모와 자식 관계와 같다. 정리하면, sysfs(kobject, attribute)의 계층 구조를 kernfs 구조로 변경하는 과정에서 kobject 는 부모, attribute 는 자식으로 컨버팅된다고 보면 된다. 이제 본격적으로 kernfs 영역으로 넘어가보자.

" kernfs 에서 새로운 노드를 만들 때, 반드시 2가지 과정을 거친다.
1. kernfs_new_node() : kernfs 노드 생성
2. kernfs_add_one() : 새로 만들어진 kernfs 노드를 kernfs 계층 구조에 추가" kernfs_new_node / kernfs_add_one 함수는 뒤에서 다시 다루도록 하고, 여기서 kernfs 파일과 폴더의 차이만 간단하게 짚고 넘어가자. kernfs_node 구조체에 공용체가 하나있는데, 만약, kernfs_node 가 파일이라면 공용체는 attr 이 사용된다. 왜 그럴까? sysfs 에서 폴더는 operation 이 필요가 없다. 왜냐면, 폴더를 read / write 하는게 의미가 없기 때문이다. 그런데, 파일은 다르다. read / write 가 의미가 있다.
// include/linux/kernfs.h - v6.5 struct kernfs_node { .... union { struct kernfs_elem_dir dir; struct kernfs_elem_symlink symlink; struct kernfs_elem_attr attr; }; .... };// fs/kernfs/file.c - v6.5 struct kernfs_node *__kernfs_create_file(struct kernfs_node *parent, const char *name, umode_t mode, kuid_t uid, kgid_t gid, loff_t size, const struct kernfs_ops *ops, void *priv, const void *ns, struct lock_class_key *key) { struct kernfs_node *kn; unsigned flags; int rc; flags = KERNFS_FILE; // --- 1 kn = kernfs_new_node(parent, name, (mode & S_IALLUGO) | S_IFREG, uid, gid, flags); // --- 1 .... kn->attr.ops = ops; // --- 2 kn->attr.size = size; // --- 2 kn->ns = ns; // --- 2 kn->priv = priv; // --- 2 .... rc = kernfs_add_one(kn); // --- 3 .... return kn; }1. KERNFS_FILE 은 현재 생성되는 kernfs_node 가 `파일` 임을 나타낸다. kenrfs_new_node 함수는 인자로 전달된 정보를 가지고 새로운 kernfs_node 를 생성하고 초기화한다.
2. __kernfs_create_file() 함수는 `생성 -> 초기화 -> 등록` 을 수행한다. 이 단계는 `초기화` 를 의미한다 (kernfs_new_node() 에서는 kernfs_node 를 생성하는데, 초점을 맞춘다).
3. 생성 및 초기화가 완료된 kernfs_node 를 커널에 등록한다. 이 함수가 성공적으로 호출되면, 커널이 관리하는 kernfs 레드 블랙트리에 kernfs_node 가 연결된다." 다수의 attribute 들을 관리할 수 있는 구조체가 있다. 바로, `struct attribute_group` 구조체다.
// include/linux/sysfs.h - v6.5 struct attribute_group { const char *name; umode_t (*is_visible)(struct kobject *, struct attribute *, int); umode_t (*is_bin_visible)(struct kobject *, struct bin_attribute *, int); struct attribute **attrs; struct bin_attribute **bin_attrs; };" `internal_create_group()` 함수는 attribute 를 sysfs 파일로 만들기전에, 파일을 담을 수 있는 폴더가 있는지 확인하는 함수다.
`update`는 attribute visibility(1) 혹은 mode(0) 를 변경할 지를 나타낸다[참고1]. 여기서 update 는 파일의 부모, 즉, 디렉토리를 기준으로 검사하는 것이다. 파일을 update 한다는 것이 아니다. update 가 참이라는 것은 이미 폴더가 존재한다는 것을 의미한다. 만약, update 거짓(0)이라면 폴더가 없으므로, kernfs_create_dir_ns 함수를 통해 생성된다.
// fs/sysfs/group.c - v6.5 static int internal_create_group(struct kobject *kobj, int update, const struct attribute_group *grp) { struct kernfs_node *kn; kuid_t uid; kgid_t gid; int error; .... kobject_get_ownership(kobj, &uid, &gid); if (grp->name) { if (update) { kn = kernfs_find_and_get(kobj->sd, grp->name); .... } else { kn = kernfs_create_dir_ns(kobj->sd, grp->name, S_IRWXU | S_IRUGO | S_IXUGO, uid, gid, kobj, NULL); .... } } } else { kn = kobj->sd; } kernfs_get(kn); error = create_files(kn, kobj, uid, gid, grp, update); .... kernfs_put(kn); if (grp->name && update) kernfs_put(kn); return error; }" create_files() 함수는 attribute 를 group 으로 받았기 때문에, 다수의 파일을 생성한다(for 문을 통해 다수의 attributes 가 생성되는 것을 볼 수 있다).
// fs/sysfs/group.c - v6.5 static int create_files(struct kernfs_node *parent, struct kobject *kobj, kuid_t uid, kgid_t gid, const struct attribute_group *grp, int update) { struct attribute *const *attr; struct bin_attribute *const *bin_attr; int error = 0, i; if (grp->attrs) { for (i = 0, attr = grp->attrs; *attr && !error; i++, attr++) { umode_t mode = (*attr)->mode; /* * In update mode, we're changing the permissions or * visibility. Do this by first removing then * re-adding (if required) the file. */ if (update) kernfs_remove_by_name(parent, (*attr)->name); if (grp->is_visible) { mode = grp->is_visible(kobj, *attr, i); if (!mode) continue; } .... mode &= SYSFS_PREALLOC | 0664; error = sysfs_add_file_mode_ns(parent, *attr, mode, uid, gid, NULL); .... } // for .... } // grp->attrs if (grp->bin_attrs) { ..... } exit: return error; }- Kernfs operations
" struct attribute 구조체를 보면 굉장히 심플하다. name은 파일 이름을 나타내고, mode는 파일의 권한을 나타낸다. 그런데, 이 파일을 읽고 쓰기 위한 인터페이스가 필요한데, struct attribute 에는 그게 없다. 어디에 있을까? 모든 파일 시스템은 `struct file_operations` 구조체를 정의해서 해당 파일시스템의 operations 들을 리눅스 커널에 제공해야 한다. 당연히, sysfs 도 예외는 아니다.
// fs/kernfs/file.c - v6.5 const struct file_operations kernfs_file_fops = { .read_iter = kernfs_fop_read_iter, .write_iter = kernfs_fop_write_iter, .llseek = generic_file_llseek, .mmap = kernfs_fop_mmap, .open = kernfs_fop_open, .release = kernfs_fop_release, .poll = kernfs_fop_poll, .fsync = noop_fsync, .splice_read = copy_splice_read, .splice_write = iter_file_splice_write, };" `struct file_opeations` 구조체는 파일 시스템에서 구현해야 하는 자료 구조다. 이 구조체를 통해서 유저 프로세스가 직접 데이터에 액세스할 수 있다. 아래 그림을 보면, 유저 프로세스는 /sys/test/access 파일에 액세스하고 있다. 이 때, VFS 에 접근하지만, 실제로는 커널 내부적으로는 구체적으로 매핑된 ext4 혹은 kenrfs 등과 같은 파일 시스템에 접근하게 된다(엄밀히 말하면, 아래 내용은 정확한 비유는 아니다. 왜냐면, ext4 나 ntfs 는 디스크 파일 시스템이고, kernfs 는 램 파일 시스템이기 때문이다).

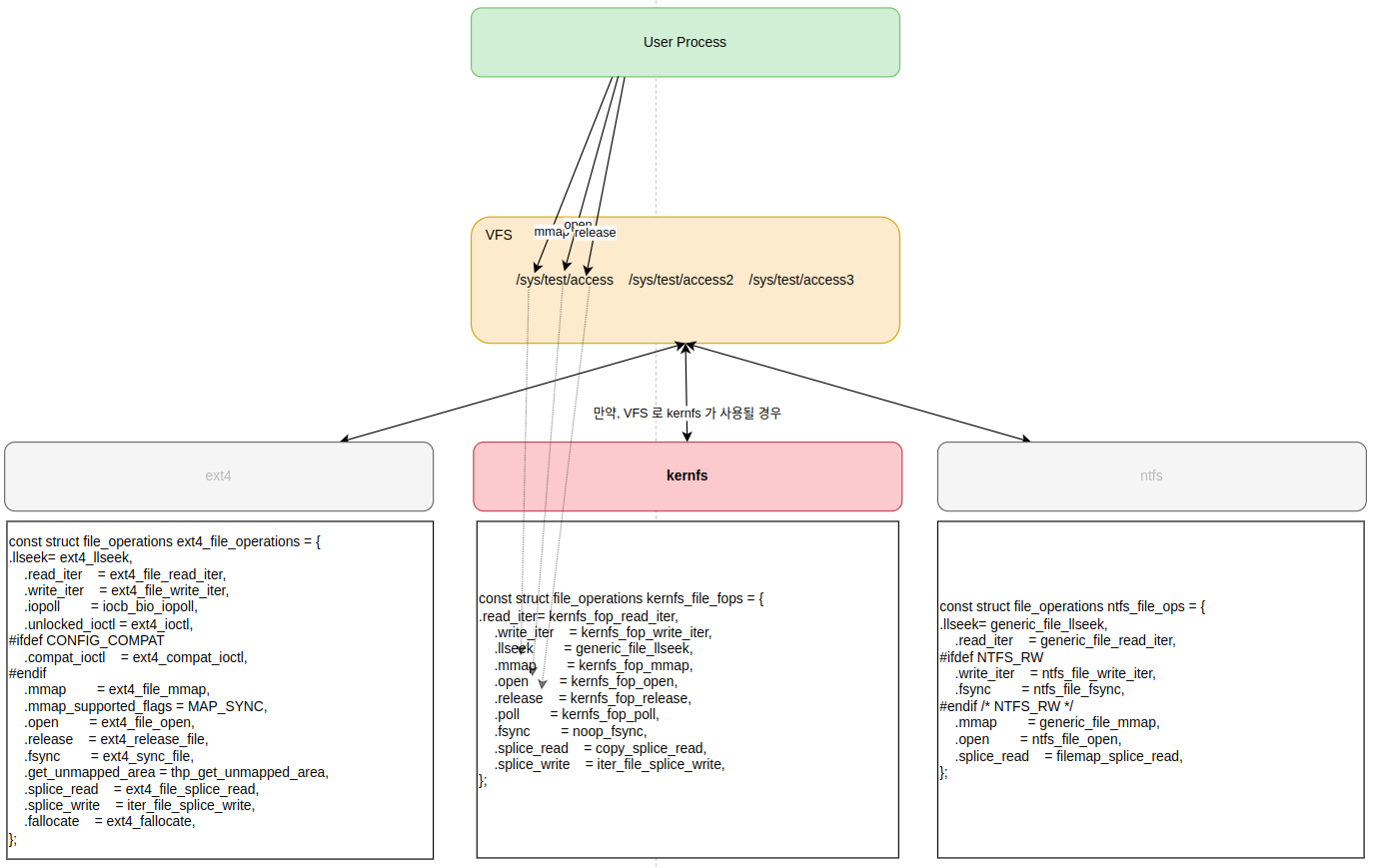
" 이제부터는 언급되는 파일 시스템은 모두 kernfs 라고 가정한다. 만약, 유저 스페이스에서 /sys/test/access 파일을 읽으면 어떻게 될까? 커널 내부적으로 `kernfs_fop_read_iter -> kernfs_file_read_iter` 함수가 호출된다. 그런데, 내부적으로 `kernfs_ops->read` 함수가 호출되고 있다. 그렇다면, `struct kernfs_ops` 구조체는 또 어디서 정의되는 것일까?
// fs/kernfs/file.c - v6.5 static const struct kernfs_ops *kernfs_ops(struct kernfs_node *kn) { .... return kn->attr.ops; }// fs/kernfs/file.c - v6.5 static ssize_t kernfs_file_read_iter(struct kiocb *iocb, struct iov_iter *iter) { struct kernfs_open_file *of = kernfs_of(iocb->ki_filp); ssize_t len = min_t(size_t, iov_iter_count(iter), PAGE_SIZE); const struct kernfs_ops *ops; char *buf; .... ops = kernfs_ops(of->kn); if (ops->read) len = ops->read(of, buf, len, iocb->ki_pos); else len = -EINVAL; .... }// fs/kernfs/file.c - v6.5 static ssize_t kernfs_fop_read_iter(struct kiocb *iocb, struct iov_iter *iter) { .... return kernfs_file_read_iter(iocb, iter); }" attribute 를 만들 때, 커널에서 이미 정의 해놓은 struct kernfs_ops 할당한다. 아래 코드를 보면 알겠지만, 여러 개의 struct kernfs_ops 를 정의 해놓았다. 어떤걸 선택할지에 대한 기준은 다음과 같다.
1. sysfs 에 만들 속성이 struct attribute 인지 struct bin_attribute 인지
2. pre-alloc 사용 여부
3. `->show` 및 `->store` 함수의 구현 여부// fs/sysfs/file.c - v6.5 .... static const struct kernfs_ops sysfs_file_kfops_ro = { .seq_show = sysfs_kf_seq_show, }; static const struct kernfs_ops sysfs_file_kfops_wo = { .write = sysfs_kf_write, }; static const struct kernfs_ops sysfs_file_kfops_rw = { .seq_show = sysfs_kf_seq_show, .write = sysfs_kf_write, }; .... static const struct kernfs_ops sysfs_bin_kfops_ro = { .read = sysfs_kf_bin_read, }; static const struct kernfs_ops sysfs_bin_kfops_wo = { .write = sysfs_kf_bin_write, }; static const struct kernfs_ops sysfs_bin_kfops_rw = { .read = sysfs_kf_bin_read, .write = sysfs_kf_bin_write, }; ...." 위에서는 6개의 kernfs_ops 를 보여줬지만, 실제로는 더 많이 정의되어 있다. 그리고, 위에 정의된 kernfs_ops 안에는 sysfs operation 들이 작성되어 있는 것을 확인할 수 있다.
" sysfs_add_file_mode_ns() 함수는 구현되어 있는 operation 여부에 따라 어떤 kernfs_ops 를 사용할지를 결정한다. 예를 들어, read 만 구현하면 kernfs_ops 는 `sysfs_file_kfops_ro` 가 등록된다. 만약, read & write 를 모두 지원하면, sysfs_file_kfops_rw` 가 등록된다.
static const struct kernfs_ops sysfs_file_kfops_rw = { .seq_show = sysfs_kf_seq_show, .write = sysfs_kf_write, }; .... int sysfs_add_file_mode_ns(struct kernfs_node *parent, const struct attribute *attr, umode_t mode, kuid_t uid, kgid_t gid, const void *ns) { .... if (mode & SYSFS_PREALLOC) { if (sysfs_ops->show && sysfs_ops->store) ops = &sysfs_prealloc_kfops_rw; else if (sysfs_ops->show) ops = &sysfs_prealloc_kfops_ro; else if (sysfs_ops->store) ops = &sysfs_prealloc_kfops_wo; } else { if (sysfs_ops->show && sysfs_ops->store) ops = &sysfs_file_kfops_rw; else if (sysfs_ops->show) ops = &sysfs_file_kfops_ro; else if (sysfs_ops->store) ops = &sysfs_file_kfops_wo; } .... return 0; }" sysfs_kf_seq_show() / sysfs_kf_write() 함수는 kernfs operation 이다. 이 안에서는 다시 sysfs operation 을 호출해주는 관계를 이룬다.
// fs/sysfs/file.c - v6.5 /* * Reads on sysfs are handled through seq_file, which takes care of hairy * details like buffering and seeking. The following function pipes * sysfs_ops->show() result through seq_file. */ static int sysfs_kf_seq_show(struct seq_file *sf, void *v) { struct kernfs_open_file *of = sf->private; struct kobject *kobj = of->kn->parent->priv; const struct sysfs_ops *ops = sysfs_file_ops(of->kn); .... count = ops->show(kobj, of->kn->priv, buf); if (count < 0) return count; .... return 0; } static ssize_t sysfs_kf_write(struct kernfs_open_file *of, char *buf, size_t count, loff_t pos) { const struct sysfs_ops *ops = sysfs_file_ops(of->kn); .... return ops->store(kobj, of->kn->priv, buf, count); }" 여기까지 sysfs operation 프로세스를 정리해보자. 호출 프로세스가 모두 동일하기 때문에, `읽기 / 쓰기` 만 정리한다. 그리고, bin_attribute 가 아닌, attribute 를 사용했고, prealloc 은 사용하지 않는다고 전제한다.
1. struct file_opeartions(kernfs_fop_read_iter) -> struct kernfs_ops(sysfs_kf_seq_show) -> struct sysfs_ops(kobj_attr_show) -> struct kobj_attribute->show
2. struct file_opeartions(kernfs_fop_write_iter) -> struct kernfs_ops(sysfs_kf_write) -> struct sysfs_ops(kobj_attr_store) -> struct kobj_attribute->store
" kernfs_* / sysfs_kf_* 함수들은 변경이 불가능하다. 왜냐면, 커널이 등록한 함수이기 때문이다. sysfs attribute 를 등록하고, read / write 동작을 수행하면, 무조건 kernfs_* / sysfs_kf_* 함수들은 호출된다. sub-system 레이어는 개별 드라이버에서 수정이 가능하다. 참고로, bin_attribute 라면, 부모 kobject 에서 sysfs_ops를 가져오지(`sysfs_file_ops`) 않고, 자신이 직접 호출한다. 즉, kernfs_fop_read_iter -> sysfs_kf_seq_show -> bin_attribute.[show|store]
- Attributes define macro
" 리눅스 커널에서 sysfs 가 너무 자주 사용되니 매크로를 통해서 간편하게 sysfs attribute 를 생성할 수 있다. 대표적인 DEVICE_ATTR 만 가볍게 살펴보자. DEVICE_ATTR 매크로는 __ATTR 매크로와 `struct device_attribute`를 기반으로 만들어졌다. 그리고, __ATTR 매크로는 struct device_attribute 구조체를 기반으로 만들어졌다. 그런데, __ATTR 매크로는 모든 sysfs attribute 매크로의 기본이다. 즉, 현재 리눅스 커널의 sysfs attribute 기본 형태는 struct deivce_attribute 구조체 형태라는 뜻이다.
" 굳이, device_attribute 여야 하는 이유가 뭘까? 애초에 struct attribute 구조체는 `상태`만 표현하기 때문에, `동작`을 별도로 추가해줘야 한다. 그래서, 디바이스도 sysfs attribute 로 만들기 위해 struct device_attribute 구조체를 만든것이다. 그런데, 리눅스 커널이 LDM 을 기반으로 하다보니 `struct device` 구조체가 안쓰이는 곳이 없다. 특히나, sysfs 에 리눅스 커널에 등록된 모든 디바이스가 export 된다. 그러다 보니, struct device 구조체를 사용하는데, sysfs 에 attribute 를 만들어야 한다면, struct device_attribute 구조체를 기반으로 하는 경우가 많다(IIO 혹은 HWMON 프레임워크에서 특히나 많이 사용된다).
// include/linux/device.h - v6.5 struct device_attribute { struct attribute attr; ssize_t (*show)(struct device *dev, struct device_attribute *attr, char *buf); ssize_t (*store)(struct device *dev, struct device_attribute *attr, const char *buf, size_t count); }; #define DEVICE_ATTR(_name, _mode, _show, _store) \ struct device_attribute dev_attr_##_name = __ATTR(_name, _mode, _show, _store) // include/linux/sysfs.h - v6.5 /* * Use these macros to make defining attributes easier. * See include/linux/device.h for examples.. */ #define __ATTR(_name, _mode, _show, _store) { \ .attr = {.name = __stringify(_name), \ .mode = VERIFY_OCTAL_PERMISSIONS(_mode) }, \ .show = _show, \ .store = _store, \ }" DEVICE_ATTR 매크로는 `DECLARE_*` 매크로들과 동일한 방식으로 동작한다. 즉, 변수를 생성해준다. 그런데, 약간 다른점이 있다면, 이름을 그대로 사용하지는 않는다. 이름앞에 접두사로 `dev_attr_` 붙는 것만 주의하자. 아래 그림으로 정리해보자.
" 버스 서브-시스템을 예로 들겠다. i2c, platform, spi 는 모두 버스이기 때문에, 서브-시스템에 속한다(`/sys/bus/`). 그래서, 각자만의 sysfs_ops 를 구현할 수 있다. 그리고, 리눅스 커널의 모든 버스들은 기본적으로 3개의 attribute 를 가지고 있다(uevent, drivers_probe, drives_autoprobe). 각 attribute 들은 자신만의 read / write 핸들러 함수를 등록해야 한다. 예를 들어, uevent 같은 경우는 `uevent_show` / `uevent_store` 함수가 사용된다.
/sys/bus/i2c$ ls devices/ drivers/ drivers_autoprobe drivers_probe uevent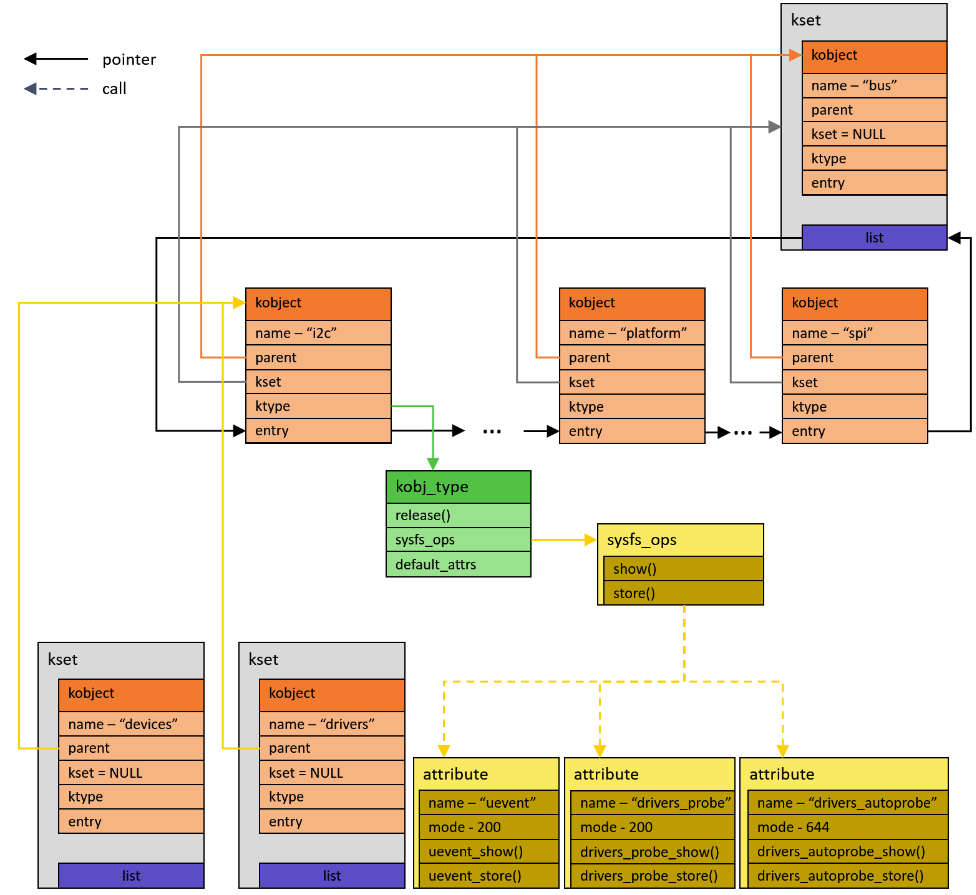
https://blog.csdn.net/yangjizhen1533/article/details/111155659- Kernfs [참고1 참고2]
" kernfs 가 도입되기 전에는 sysfs 를 생성할 때, kobject 에 크게 의존했다. kernfs 가 도입되기 전까지는 `sysfs <-> vfs` 였었기 때문에, kobject 의 구조가 sysfs 구조를 형성하는 데, 직접적인 영향을 끼쳤다. kernfs 를 도입하면서, `sysfs <-> kernfs <-> vfs` 구조가 되면서, sysfs 의 폴더 및 파일은 모두 kernfs 를 기반으로 생성된다(kernfs 관련 파일을 찾아보면, kobject 를 사용하는 코드를 찾기가 어렵다).
" 사실, kernfs 와 sysfs 는 기능적으로 큰 차이가 없다. 각 서브-시스템에서 자신만의 virtual file system 만들기 위해 앞에 말한 파일 시스템들을 사용하기 때문에 목적에서는 차이가 없다. 그래서 사실 kernfs API 를 sysfs 외에 직접적으로 사용하는 곳은 많지않다고 한다(cgroup 에서는 kernfs 를 사용한다고 함).
The Linux 3.14 kernel is getting Kernfs, which is the splitting of the sysfs logic into an independent entity so other kernel subsystems can more easily implement their own virtual file-system.
- 참고 : https://www.phoronix.com/news/MTU3NzQ" `kernfs_node`는 sysfs의 폴더 및 파일을 표현하는 구조체다. 마치 VFS에서 inode와 같다고 보면 된다.
// include/linux/kernfs.h - v6.5 struct kernfs_node { atomic_t count; atomic_t active; #ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map; #endif /* * Use kernfs_get_parent() and kernfs_name/path() instead of * accessing the following two fields directly. If the node is * never moved to a different parent, it is safe to access the * parent directly. */ struct kernfs_node *parent; const char *name; struct rb_node rb; const void *ns; /* namespace tag */ unsigned int hash; /* ns + name hash */ union { struct kernfs_elem_dir dir; struct kernfs_elem_symlink symlink; struct kernfs_elem_attr attr; }; void *priv; /* * 64bit unique ID. On 64bit ino setups, id is the ino. On 32bit, * the low 32bits are ino and upper generation. */ u64 id; unsigned short flags; umode_t mode; struct kernfs_iattrs *iattr; };- count : kernfs_node 자체에 접근하는 것은 count 를 유지하고 있으면 된다. 이 값만 유지한다면, kernfs_node 에서 read / write 는 가능해진다. 그러나, remove 는 이 값으로 판단되지 않는다.
- active : 이 필드는 VFS 에 visible 할지 말지를 결정한다.즉, inactive node는 VFS 상에 in-visible 하게 된다. 이 필드가 de-active 가 되어야,
A node which hasn't been activated isn't visible to userland and deactivation is skipped during its removal.
....
- 참고 : https://elixir.bootlin.com/linux/v6.5/source/fs/kernfs/dir.c#L463
- parent : 자신의 kernfs 부모 노드를 저장한다(일반적으로 폴더(kobj->sd)가 된다)
- name : 해당 kernfs_node 의 이름을 나타낸다.
- rb : kernfs 계층 구조는 red-black tree 를 이용하고 있다.
- priv : 말 그대로 `private data`를 저장하는 필드다. sysfs 에서는 주로 여기에 `kobject`를 저장한다.
- union : kernfs_node 가 파일(struct kernfs_elem_attr)인지, 폴더(
struct kernfs_elem_dir)인지, 심링크 파일(
struct kernfs_elem_symlink)인지를 구별하면서, 각 노드에 맞는 private meta-data 가 들어있는 필드.
- flags : kernfs_node 의 상태를 나타낸다. 예를 들어, 현재 활성화 상태인지(KERNFS_ACTIVATED), 현재 제거 중인지(KERNFS_REMOVING) 등
- mode : 퍼미션과 같다고 보면 된다." `count`와 `active` 필드의 차이는 뭘까? count 는 kernfs_node 를 사용하기 위해서 유지하고 있어야 한다. active 는 kernfs_node 를 제거하기 위해서 유지하고 있어야 한다.
As long as count reference is held, the kernfs_node itself is accessible. Dereferencing elem or any other outer entity requires active reference.
- 참고 : https://elixir.bootlin.com/linux/v6.5/source/include/linux/kernfs.h#L153" type은 폴더인지, 파일인지 등을 구분하는 용도로 사용된다. flag는 현재 상태를 나타낸다.
// include/linux/kernfs.h - v6.5 enum kernfs_node_type { KERNFS_DIR = 0x0001, KERNFS_FILE = 0x0002, KERNFS_LINK = 0x0004, }; #define KERNFS_TYPE_MASK 0x000f #define KERNFS_FLAG_MASK ~KERNFS_TYPE_MASK .... enum kernfs_node_flag { KERNFS_ACTIVATED = 0x0010, KERNFS_NS = 0x0020, KERNFS_HAS_SEQ_SHOW = 0x0040, .... KERNFS_HIDDEN = 0x0200, KERNFS_SUICIDAL = 0x0400, KERNFS_SUICIDED = 0x0800, KERNFS_EMPTY_DIR = 0x1000, .... };- KERNFS_ACTIVATED : kernfs root 노드에 `KERNFS_ROOT_CREATE_DEACTIVATED` 플래그가 SET 되어 있으면, 새로운 노드가 추가될 때, 자동으로 active 되지 않는다. 수동으로 직접 active 해줘야 한다. 만약, 루트 노드에 `KERNFS_ROOT_CREATE_DEACTIVATED` 플래그가 CLEAR 되어있으면, 새로운 노드가 추가될 때, 자동으로 active 된다[참고1].
- A node which hasn't been activated isn't visible to userland and deactivation is skipped during its removal...
- A node which hasn't been activated is not visible to userland and its removal won't trigger deactivation...
- 참고 : https://elixir.bootlin.com/linux/v6.5/source/fs/kernfs/dir.c#L463
- KERNFS_HIDDEN : 이 플래그가 설정된 노드를 hiddne node 라고 부른다. hiddne 노드가 되면, 기본적으로 de-activated 상태가 된다. 이 플래그가 SET 되면, user space 에서 보이지 않을뿐만 아니라(de-activated 되므로), activa 하려는 동작들도 모두 무시된다. 즉, 이 플래그를 먼저 풀어야 active 할 수 있다는 소리다.
- KERNFS_SUICIDAL : kernfs_node 를 삭제중임을 나타낸다.
- KERNFS_SUICIDED : kernfs_node 를 삭제 완료되었음을 나타낸다.
- KERNFS_EMPTY_DIR : 이 플래그는 `현재 폴더가 비어있다` 는 의미보다는 계속 빈 폴더여야 한다는 뉘앙스의 플래그다. 그러므로, KERNFS_EMPTY_DIR 플래그가 SET 된 kernfs_node 는 부모 노드가 될 수 없다.- KERNFS_ROOT_CREATE_DEACTIVATED & KERNFS_ACTIVATED [참고1]
: 이 패치 전에 kernfs_node 는 생성되면 즉각적으로 user space 에 visible 되었다. 그런데, 이러한 구조는 원자적으로 다수의 kernfs_node 를 생성하는데 있어서, 성공 여부를 파악하기 어렵게 만든다. 예를 들어, 하나의 작업을 수행하는데, 3개의 파일이 동시에 생성할 일이 생겼다. 당연히 이 3개의 파일은 모두 연관이 되있기 때문에 다 같이 만들어져야 한다. 혹시나, 3개 중에 하나의 파일이라도 실패한다면, 3개의 파일 모두 만들어지면 안된다. 그런데, kernfs 구조는 이렇지 않았다. 즉, 트랜잭션 및 세션 단위로 묶지 못한 것이다. 만약, 2개의 파일만 생성되었다고 치자. 그런데, 이 파일들이 user space에 노출되고, 이미 사용자에게 사용되고 있다면, 이건 큰 문제다. 얼른 active ref 를 drain 해서 제거해야한다. 그런데, 이게 또 동기화 문제 때문에 쉽지가 않다.
: 그래서 추가된 플래그 `KERNFS_ROOT_CREATE_DEACTIVATED` 플래그다. 만약, 이 플래그 SET 되면, 이 시점 이후에 생성되는 노드들은 모두 deactivated 상태로 생성된다. 즉, 명시적으로 activate 해주기 전까지는 user space 에 in-visible 되는 것이다. user space 에 visible 하는 노드는 `KERNFS_ACTIVATED` 플래그가 설정된다.
- What is count and active in kernfs ?
" 이 내용을 알려면, sysfs_dirent 패치까지 알아봐야 한다. 왜냐면, kernfs 가 sysfs_dirent 에서 왔기 때문이다. 아래 패치는 기존에 s_count 필드가 존재하는 상황에서 s_active 필드가 추가된 패치다. sysfs_dirent 에서 s_active 를 추가한 이유는 kobject 와 sysfs 사이에 링크를 즉각적으로 차단하기 위해서였다. 즉, 사용자가 sysfs 를 통해서 더 이상 kobject 를 사용하는 것을 막을 수 있다는 소리다. kenrfs 에서는 어떨까? 사용자와 kernfs 사이에 링크를 즉각적으로 끊는다고 보면 된다.
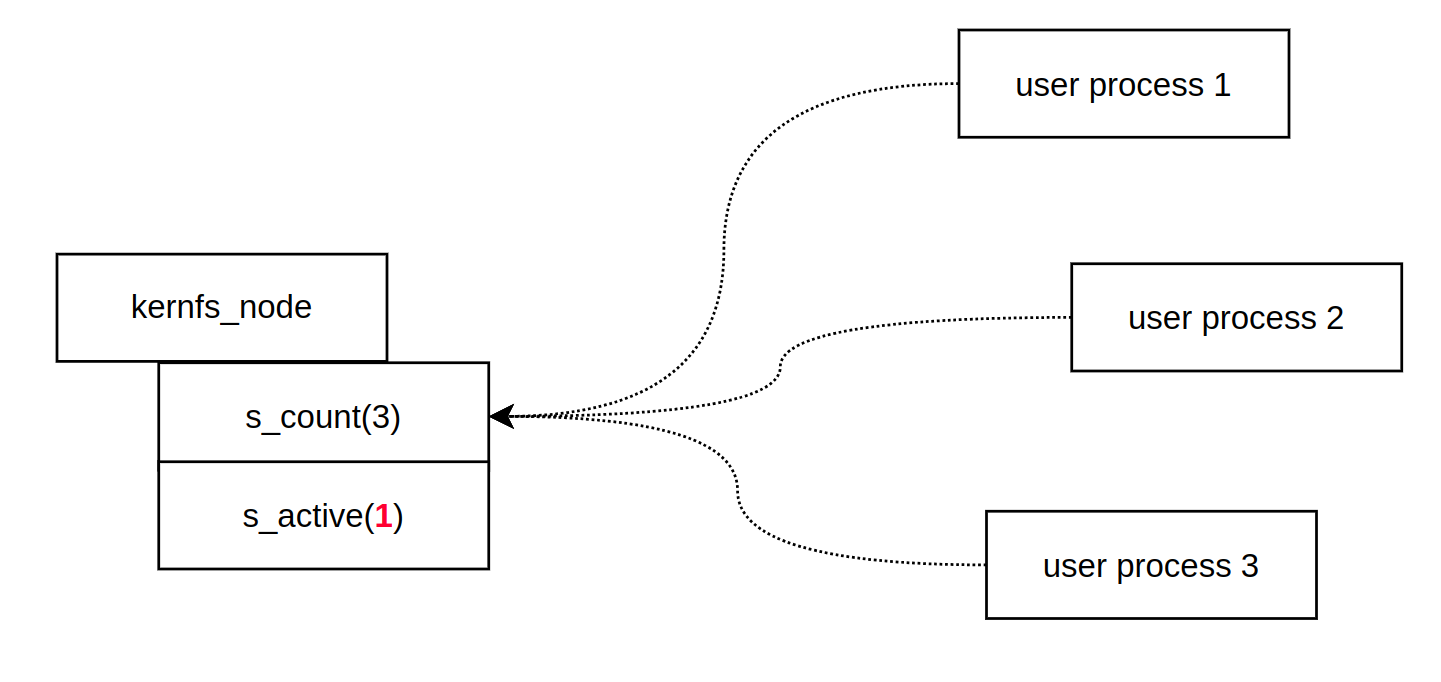
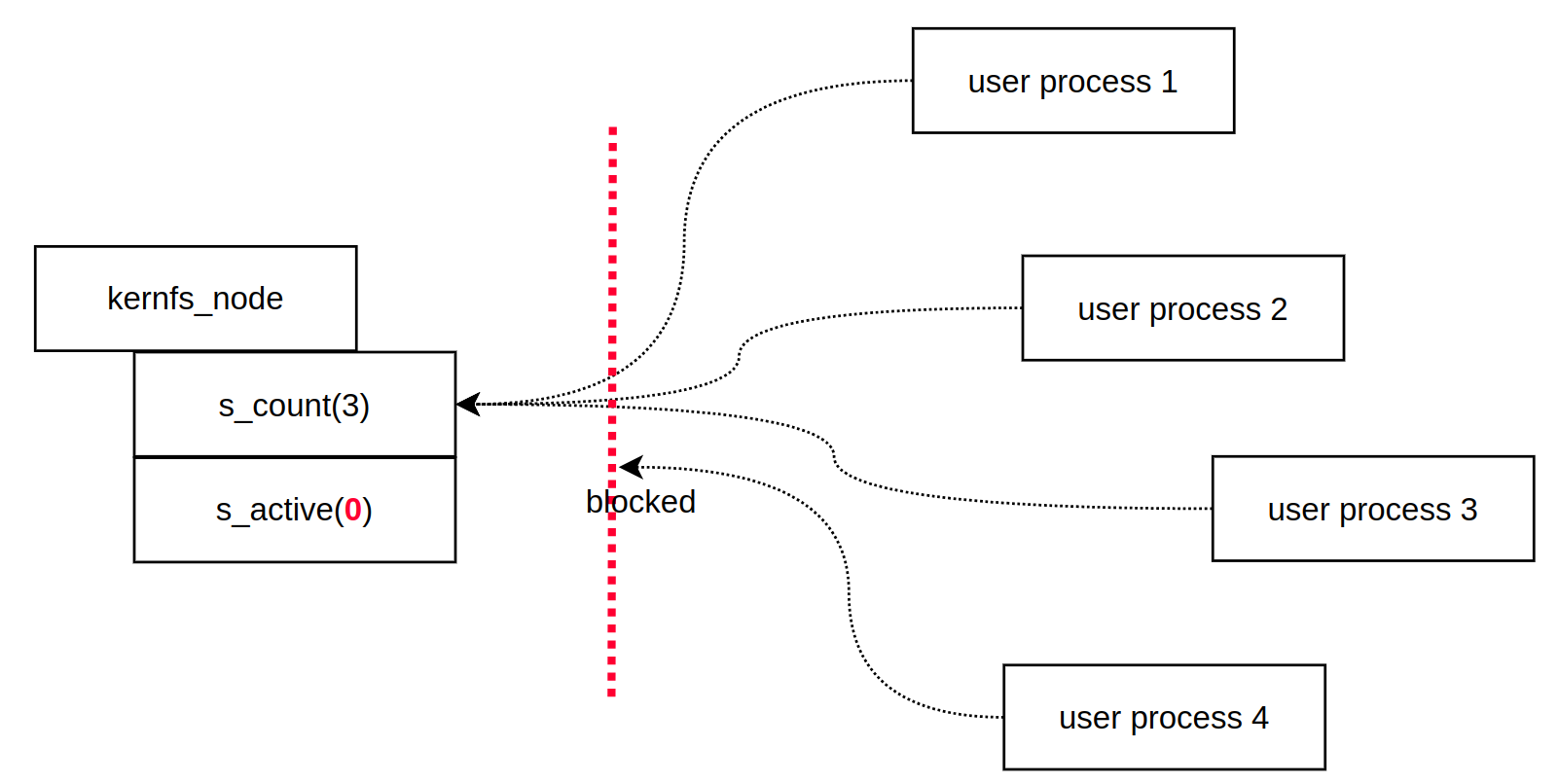
" 이렇게 하는 이유가 뭘까? 나쁜 의도가 있을 수 있기 때문이다. kobject 가 ref 가 끝나지 않는 이상 계속 메모리에 상주하게 된다. 메모리는 한정되어 있기 때문에, 반드시 필요한 객체에게만 할당해야 한다. 그리고, 더 이상 할일이 없는 친구들은 메모리를 반납해야 한다. 그런데, 앞에 언급한 기능은 s_count 만으로는 표현할 수 없다. 왜냐면, s_count 는 실제 kernfs node 의 수명만 나타내는 것이기 때문이다. 즉, kernfs node 가 release 되려면, 더 이상 reference 가 증가하지 않아야 한다(cutline 이 필요하다는 뜻이다). s_active 는 유저 레벨과 kernfs node 사이에 link 를 끊음으로써, s_count 가 증가되는 것을 막을 수 있다.
Opening a sysfs node references its associated kobject, so userland can arbitrarily prolong lifetime of a kobject which complicates lifetime rules in drivers. This patch implements active reference and makes the association between kobject and sysfs immediately breakable.
Now each sysfs_dirent has two reference counts - s_count and s_active. s_count is a regular reference count which guarantees that the containing sysfs_dirent is accessible. As long as s_count reference is held, all sysfs internal fields in sysfs_dirent are accessible including s_parent and s_name.
The newly added s_active is active reference count. This is acquired by invoking sysfs_get_active() and it's the caller's responsibility to ensure sysfs_dirent itself is accessible (should be holding s_count one way or the other). Dereferencing sysfs_dirent to access objects out of sysfs proper requires active reference. This includes access to the associated kobjects, attributes and ops.
The active references can be drained and denied by calling sysfs_deactivate(). All active sysfs_dirents must be deactivated after deletion but before the default reference is dropped. This enables immediate disconnect of sysfs nodes. Once a sysfs_dirent is deleted, it won't access any entity external to sysfs proper.
- 참고 : https://github.com/torvalds/linux/commit/0ab66088c855eca68513bdd7442a426c4b374ced" 그렇다면, 위에 s_count / s_active 가 kernfs 에서는 어떻게 적용될까? kernfs_node 는 생성될 때, active 의 초기값으로 `KN_DEACTIVATED_BIAS` 가 설정된다. 아래 `비활성화 여부` 코드를 보면, 알겠지만, 최초 kernfs_node 생성시에는 de-active 상태인 것을 알 수 있다. 그런데, KN_DEACTIVATED_BIAS 정체가 뭘까?
// fs/kernfs/kernfs-internal.h - v6.5 /* +1 to avoid triggering overflow warning when negating it */ #define KN_DEACTIVATED_BIAS (INT_MIN + 1) // 초기화 atomic_set(&kn->active, KN_DEACTIVATED_BIAS); // 비활성화 { if (kernfs_active(kn)) atomic_add(KN_DEACTIVATED_BIAS, &kn->active); } // 활성화 atomic_sub(KN_DEACTIVATED_BIAS, &kn->active); // 비활성화 여부 atomic_read(&kn->active) == KN_DEACTIVATED_BIAS" KN_DEACTIVATED_BIAS 는 굉장히 큰 음수다. 왜 이 값으로 초기화할까? 일반적인 ref count 는 0 이면 비활성, 양수면 활성을 의미한다. 그런데, kernfs 에서 active는 0 혹은 양수면 활성화 상태를 의미하고, 음수면 비활성화 상태를 의미한다. 왜 이런 구조를 택했을까?
s_active starts at zero and each active reference increments s_active. Putting a reference decrements s_active. Deactivation subtracts SD_DEACTIVATED_BIAS which is currently INT_MIN and assumed to be small enough to make s_active negative. If s_active is negative, sysfs_get() no longer grants new references. Deactivation succeeds immediately if there is no active user; otherwise, it waits using a completion for the last put.
- 참고 : https://www.uwsg.indiana.edu/hypermail/linux/kernel/0707.1/1931.html" KN_DEACTIVATED_BIAS 는 SD_DEACTIVATED_BIAS 값을 기반으로 한다. 즉, 기존에 sysfs 에서 사용되던 코드들이 kernfs 로 이동되면서 SD_DEACTIVATED_BIAS 가 KN_DEACTIVATED_BIAS 로 바뀐것이다. 그렇기 때문에, KN_DEACTIVATED_BIAS 의 사용 용도를 알기 위해서는 SD_DEACTIVATED_BIAS 를 알아보는 것이 좋다.
" 기존 s_active(현재 kn->active)는 음수가 되면, de-active 상태를 나타냈다. 그런데, 여기서 SD_DEACTIVATED_BIAS (INT_MIN)와 같은 큰 값을 빼는 이유가 뭘까? 일단, 음수로 진입시키기 위함이다. 음수로 진입을 해야, 더 이상 새로운 active reference 를 생성하지 않기 때문이다. 이 상태에서, 기존에 있던 active reference 들이 모두 해제되기를 기다리는 것이다.
1. kn->active(s_active) < 0 && kn->active != KN_DEACTIVATED_BIAS(SD_DEACTIVATED_BIAS) 이면, new active reference 를 만들지 않는다. 그러나, active reference 가 아직 남아있으므로, 제거할 수는 없다.
2. kn->active(s_active) < 0 && kn->active == KN_DEACTIVATED_BIAS(SD_DEACTIVATED_BIAS) 이면, active reference 가 없다는 뜻이므로, kernfs_node 를 제거한다." `kn->active == KN_DEACTIVATED_BIAS` 이 코드의 의미는 뭘까? KN_DEACTIVATED_BIAS 가 -5 라고 해보자. 그렇면, kn->active 의 초기값은 -5 가 된다. 그리고 활성화하려면, `kn->active -= KN_DEACTIVATED_BIAS` 이기 때문에, kn->active 가 0이 된다. 여기서 new active reference 가 2개 발생했다고 치자. 그렇다면, kn->active == 2 가 된다. 그런데, 여기서 kn 에 대한 remove 요청이 들어왔다. 제일 먼저 해야 하는 건 음수로 만들어야 한다. 그러므로, 충분히 큰 값인 KN_DEACTIVATED_BIAS 를 뺀다. 그렇면, kn->active = -3 이 된다. 그런데, 아직 active reference 가 2개 남았다. 즉, kn->active 가 -5가 되어야 zero active reference 가 된다는 뜻이다.
" 그렇다면, 언제 count 와 active 는 각각 언제 증가하고 감소할까? count 같은 경우는 sysfs 쪽에서 kernfs_get 함수를 통해서 ref count 를 계속 유지한다. active 같은 경우는 주로, `fs/kernfs/file.c` 에서 많이 사용되는데, 이 파일은 kenrfs ops 함수들이 모여있는 곳이다. 즉, 유저 스페이스에서 sysfs 파일에 read / write 할 때, `vfs -> kernfs -> sysfs -> attribute` 순으로 호출되는데, kernfs 차례에서 kernfs_get_active 를 통해서 해당 kernfs_node 를 active 한다(주로 kernfs_get_active 함수가 많이 사용된다).
//kn->count void kernfs_get(struct kernfs_node *kn); // kn->active struct kernfs_node *kernfs_get_active(struct kernfs_node *kn); void kernfs_activate(struct kernfs_node *kn); void kernfs_show(struct kernfs_node *kn, bool show);" `atomic_inc_unless_negative` 함수는 음수가 아니면, 1을 증가시키는 함수다. 그리고, 값을 업데이트 했다면, 즉, 값이 음수가 아니었다면 true 를 반환한다. 그렇지 않으면, false 를 반환한다. kernfs_ops 의 구조는 거의 대부부이 아래 `kernfs_fop_*` 함수와 비슷하다. 먼저, kernfs_node 를 활성화시킨다. 그래야, 유저 스페이스와 통신이 가능해진다. 그리고, 유저가 입력한 커맨드에 맞는 오퍼레이션이 실행된다.
static ssize_t kernfs_fop_*( ... ) { .... if (!kernfs_get_active(kn)) { .... return ERRORL; } ops = kernfs_ops(kn); ops->[write|read|open]( ... ); .... } // fs/kernfs/dir.c - v6.5 struct kernfs_node *kernfs_get_active(struct kernfs_node *kn) { .... if (!atomic_inc_unless_negative(&kn->active)) return NULL; .... return kn; }" kernfs_active 함수는 인자로 전달된 kernfs_node 의 active 상태 여부를 반환한다. kn->active 가 0 보다 크거나 같다면, active 상태를 의미한다.
// fs/kernfs/dir.c - v6.5 static bool __kernfs_active(struct kernfs_node *kn) { return atomic_read(&kn->active) >= 0; } static bool kernfs_active(struct kernfs_node *kn) { lockdep_assert_held(&kernfs_root(kn)->kernfs_rwsem); return __kernfs_active(kn); }" kernfs_node 가 active 되지 못하는 조건들이 있다. KERNFS_HIDDEN 혹은 KERNFS_REMOVING 플래그 SET 되면, kernfs_node 는 active 되지 못한다. 그리고, active 가 되면, KERNFS_ACTIVATED 플래그가 SET 된다.
// fs/kernfs/dir.c - v6.5 static void kernfs_activate_one(struct kernfs_node *kn) { lockdep_assert_held_write(&kernfs_root(kn)->kernfs_rwsem); kn->flags |= KERNFS_ACTIVATED; if (kernfs_active(kn) || (kn->flags & (KERNFS_HIDDEN | KERNFS_REMOVING))) return; WARN_ON_ONCE(kn->parent && RB_EMPTY_NODE(&kn->rb)); WARN_ON_ONCE(atomic_read(&kn->active) != KN_DEACTIVATED_BIAS); atomic_sub(KN_DEACTIVATED_BIAS, &kn->active); }- How does kernfs create a directory ?
" kobject 를 통해 sysfs 에 디렉토리를 생성할 때, sysfs_create_dir_ns 함수를 살펴봤었다. 이 함수는 실제 sysfs 디렉토리를 만들기 위해 kernfs_create_dir_ns 함수를 내부적으로 호출한다. 여기서 `kn->dir... `에 주목할 필요가 있다. kn->dir 은 공용체다. kn->dir 이 사용됬다는 것은 현재 kernfs_node 가 폴더를 나타낸다는 것을 의미한다. 그리고, 위에서 파일(attribute)을 만들 때와 차이가 있다면, kernfs_create_dir_ns 함수에 전달되는 parent는 부모 kobj의 kernfs_node를 의미한다.
// fs/kernfs/dir.c - v6.5 struct kernfs_node *kernfs_create_dir_ns(struct kernfs_node *parent, const char *name, umode_t mode, kuid_t uid, kgid_t gid, void *priv, const void *ns) { struct kernfs_node *kn; int rc; kn = kernfs_new_node(parent, name, mode | S_IFDIR, uid, gid, KERNFS_DIR); .... kn->dir.root = parent->dir.root; kn->ns = ns; kn->priv = priv; rc = kernfs_add_one(kn); .... kernfs_put(kn); return ERR_PTR(rc); }// fs/sysfs/dir.c - v6.5 int sysfs_create_dir_ns(struct kobject *kobj, const void *ns) { struct kernfs_node *parent, *kn; kuid_t uid; kgid_t gid; .... if (kobj->parent) parent = kobj->parent->sd; else parent = sysfs_root_kn; .... kn = kernfs_create_dir_ns(parent, kobject_name(kobj), 0755, uid, gid, kobj, ns); ..... kobj->sd = kn; return 0; }" 아래 그림을 보자. sysfs 에 kobject B 를 만들어야 한다고 치자. 그렇면, kobject B 의 부모(kobj->parent)인 kobject A 의 kernfs_node 를 kernfs_create_dir_ns 함수에 전달한다. 그런데, 파일은 조금 다르다.
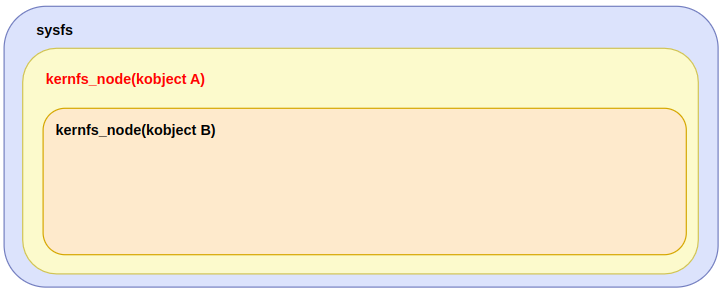
" `How does kernel make sysfs files correspoding to a kobject` 섹션에서 kernfs 파일을 생성하는 부분을 봤으므로, 여기서는 생성된 kenrfs node 가 어떻게 kernfs tree 에 연결되는지 알아본다. `kernfs_add_one()` 함수는 전달받은 kernfs_node 를 kernfs tree 에 추가한다. 그런데, 노드를 등록하기 전에 노드의 부모에 대한 검사를 빡새게 한다.
// fs/kernfs/dir.c - v6.5 int kernfs_add_one(struct kernfs_node *kn) { struct kernfs_node *parent = kn->parent; struct kernfs_root *root = kernfs_root(parent); struct kernfs_iattrs *ps_iattr; bool has_ns; int ret; .... ret = -EINVAL; has_ns = kernfs_ns_enabled(parent); if (WARN(has_ns != (bool)kn->ns, KERN_WARNING "kernfs: ns %s in '%s' for '%s'\n", has_ns ? "required" : "invalid", parent->name, kn->name)) goto out_unlock; if (kernfs_type(parent) != KERNFS_DIR) goto out_unlock; ret = -ENOENT; if (parent->flags & (KERNFS_REMOVING | KERNFS_EMPTY_DIR)) goto out_unlock; .... ret = kernfs_link_sibling(kn); .... /* * Activate the new node unless CREATE_DEACTIVATED is requested. * If not activated here, the kernfs user is responsible for * activating the node with kernfs_activate(). A node which hasn't * been activated is not visible to userland and its removal won't * trigger deactivation. */ if (!(kernfs_root(kn)->flags & KERNFS_ROOT_CREATE_DEACTIVATED)) kernfs_activate(kn); return 0; out_unlock: up_write(&root->kernfs_rwsem); return ret; }" kernfs_ns_enabled() 함수는 namespace 가 enabled 되어있는지 확인하는 함수다. 중요한 함수는 아니므로, 패스한다. 그 이후에 parent 가 폴더가 아니면, 등록 절차를 종료한다. kernfs 에서 parent 는 무조건 directory 여야 한다. 파일의 부모는 파일이 될 수 없다. 대신, 폴더의 부모는 폴더가 될 수 있다. 왜 그럴까? 만약, 파일과 파일이 부모-자식 관계를 형성한다고 할 때, 이게 파일 시스템의 구조적 측면에서 어떠한 의미가 있을까? 파일 시스템의 기본 단위는 파일과 폴더이며, 파일과 폴더과 이루는 기본적인 구조는 `포함` 이라는 기능을 통해 부모-자식 관계를 형성한다. 그런데, 파일은 `포함` 의 기능이 없다. 그렇기 때문에, 파일과 파일은 부모-자식 관계를 이룰 수 없다.
자식 부모 의미 파일 파일 X 파일 폴더 O 폴더 파일 X 폴더 폴더 O " 부모 kernfs node 가 제거중이거나, 빈 디렉토리여야 한다면 자식을 추가할 수 가 없다. kernfs_link_sibling() 함수를 통해서 kernfs_node 는 kernfs tree 에 추가된다.
" kernfs_root() 함수는 조금 독특한 함수다. kenrfs node 에는 union 구조체가 있어서 파일, 폴더, 심볼릭 링크 인지에 따라 액세스할 수 있는 변수가 달라진다. 여기서 만약 kernfs node 가 파일이면, 자신이 속한 트리의 root 에 액세스가 불가능하다. 그래서, 부모를 끌고와서 (kn = kn->parent), 루트 노드를 반환하는 것이다 (return kn->dir.root). 왜냐면, kernfs node 가 폴더일 경우에는 루트 노드에 액세스가 가능하기 때문이다.
// fs/kernfs/kernfs-internal.h - v6.5 /** * kernfs_root - find out the kernfs_root a kernfs_node belongs to * @kn: kernfs_node of interest * * Return: the kernfs_root @kn belongs to. */ static inline struct kernfs_root *kernfs_root(struct kernfs_node *kn) { /* if parent exists, it's always a dir; otherwise, @sd is a dir */ if (kn->parent) kn = kn->parent; return kn->dir.root; }" `kernfs_link_sibling()` 함수는 인자로 전달된 kernfs_node 를 kenrfs tree 에 연결시키는 함수다. kernfs 는 red-black tree 를 통해 계층 구조를 유지하고 있다. 그런데, rb-tree 에 추가될 때, 키값은 뭐가 될까? kernfs_sd_compare() 함수는 rb-tree node 의 키값을 비교해서 어디에 저장될 지를 결정한다. 이 때, 키값은 `파일의 이름`이된다.
// fs/kernfs/dir.c - v6.5 static int kernfs_sd_compare(const struct kernfs_node *left, const struct kernfs_node *right) { return kernfs_name_compare(left->hash, left->name, left->ns, right); }// fs/kernfs/dir.c - v6.5 static int kernfs_link_sibling(struct kernfs_node *kn) { struct rb_node **node = &kn->parent->dir.children.rb_node; struct rb_node *parent = NULL; while (*node) { struct kernfs_node *pos; int result; pos = rb_to_kn(*node); parent = *node; result = kernfs_sd_compare(kn, pos); if (result < 0) node = &pos->rb.rb_left; else if (result > 0) node = &pos->rb.rb_right; else return -EEXIST; } /* add new node and rebalance the tree */ rb_link_node(&kn->rb, parent, node); rb_insert_color(&kn->rb, &kn->parent->dir.children); /* successfully added, account subdir number */ if (kernfs_type(kn) == KERNFS_DIR) kn->parent->dir.subdirs++; kernfs_inc_rev(kn->parent); return 0; }'Linux > kernel' 카테고리의 다른 글
[리눅스 커널] Timer - tick layer (0) 2023.09.28 [리눅스 커널] Timer - clock event device (0) 2023.09.25 [리눅스 커널] LDM - kobject, kset, ktype (0) 2023.09.22 [리눅스 커널] PM - Platform-dependent power management (0) 2023.09.18 [리눅스 커널] PM - restart & shutdown & halt (0) 2023.09.18